TaleSpire Dev Log 254
Helloooo!
It’s been an intense few days of coding, and I’m back to ramble about it.
The issue that arose was the behavior of ‘picking’. Picking is the act of selecting something in the 3D space of the board. The current implementation of this uses the raycasting functions of the physics library. For this to work well, you need the collision mesh to match the object as well as possible. However, in general, the more detailed it is, the more work the CPU needs to do to check for collision [0].
Here is an example where we are striking a balance between those two requirements:

Most of the time, it works just fine; however, it makes the game feel unresponsive when it doesn’t. Worse, it could take you out of a critical moment in the story, and that would be a real failure on our part. Here is an example of where this can go wrong:
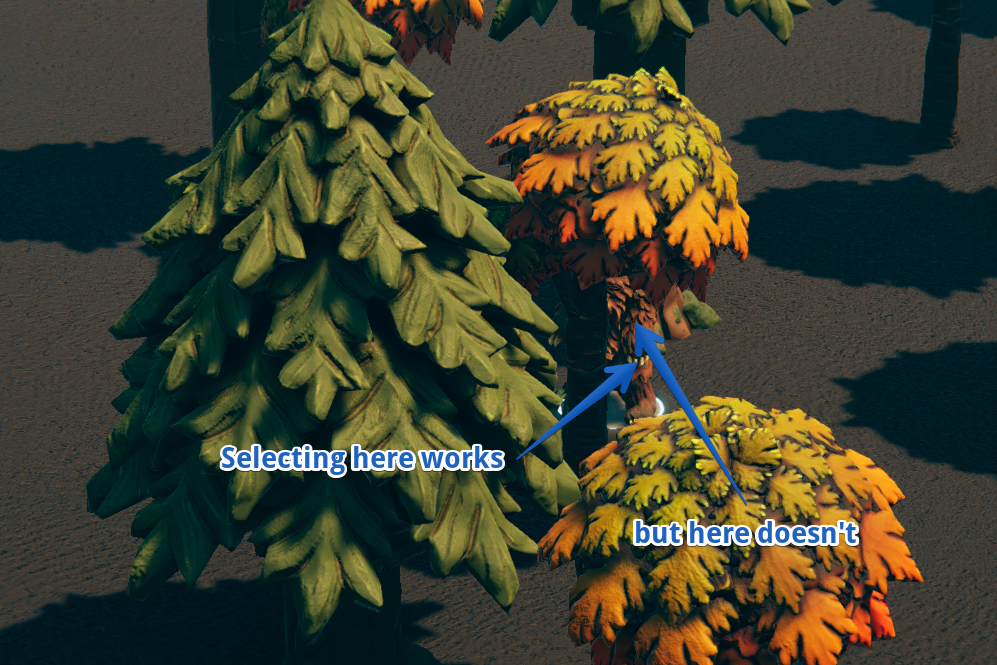
In this case, the bear is selectable just fine near the paws, but higher up, the tree’s simplistic collider is blocking the selection.
What would be ideal is to pick the creature based on the pixel your cursor is over. But how to do that?
The basic approach is very simple. Render everything again to an off-screen buffer, but instead of the typical textures, you give each object a different color based on their ID. Then you can read the color at the pixel of the screen you are interested in, and whatever color is there is the ID of the thing you are picking. Sounds neat, right? But I’m sure you’re already wondering if this might be very costly, and the answer would be yes!
We can do a lot to make it less costly though. We know we only need to consider assets in zones[1] that are under the cursor. Next, what if we have a cheap way of checking if they might be the asset under the cursor? In that case, we could greatly reduce the amount to draw.
Indeed we can do both those things. For the first, it’s done pretty much as you would expect; check if the ray from the cursor intersects each zone. For the second, our culling is done on the GPU, so we add some code to our compute shader to also check if the AABB (Axis aligned bounding box) is intersected by the ray.
That’s not bad, but we still need to render the whole of each asset. That’s a lot of pixels to draw, given that we only care about one. So we use a feature called the ‘scissor rect’ to specify which portion of the screen we want to draw to[2]
Again this is good, but it would be good to limit the number of those fragments that remain that we need to run the fragment shader for. To do this, we simply render the assets for picking after the buffer has been populated and use the screen’s depth buffer. As long as we keep our fragment shader simple, we can get early z-testing[3] which does precisely what we want.
So now we’ve limited the zones involved, the assets from the zones involved, the triangles in the assets involved, and the fragments involved. This is probably enough for the rendering portion of this technique. Now we need to get the results back.
And getting the data back, as it turns out, is where this gets tricky. Ideally, we want it on the next frame; however, we also need it without delaying the main thread, which is hard as reading back means synchronizing CPU and GPU.
To start, I simply looked at reading back the data from the portion of the texture we cared about. But Unity’s GetPixels doesn’t work with the float format I used for the texture. So after some faffing around, I added a tiny compute shader to copy the data out to a ComputeBuffer. It was immediately evident that using GetData on the ComputeBuffer caused an unacceptable delay, between 0.5 and 0.6ms in my initial tests. That is a long time to be blocking the main thread, so instead, I tested RequestAsyncReadback, it does avoid blocking the main thread, but it does so by delivering the result a few frames later. This could work, but it’s a shame to have that latency.
After a bit more googling, I learned about the D3D11_USAGE_STAGING flag and how we could use it to allow us to pull data on the following frame without blocking the main-thread. Soon after I stumbled on this comment.
MJP is an excellent engineer who’s blog posts have helped me to no end, so I was excited to see there might be an avenue here. There was only one sticking point, Unity doesn’t expose D3D11_USAGE_STAGING in it’s compute buffers. This meant I needed to break out c++ and learn to write native plugins for Unity.
Thanks to the examples, I was able to get the basics written, but something I was doing was crashing Unity A LOT. For the next < insert embarrassing number of hours here > I struggled with this that mapping the buffer would freeze or crash Unity unless done via a plugin event. In my defense, this wasn’t done in the example when writing to textures or vertex buffers, but I’m a noob at D3D, so no doubt I’m missing something.
Regardless, after all the poking about, we finally get this:
![]()
The numbers on the left-hand side are the IDs of the assets being hovered over.
I don’t have the readback timing for the final version; however, when the prototype wasn’t crashing, the readback time was 0.008ms. Which is plenty good enough for us :)
I’ve still got some experiments and cleanup to do, but then we can start hooking this up to any system that can benefit from it[4]
I hope this finds you well.
Peace.
[0] In fact, using multiple collider primitives (box, sphere, capsule, etc) together is much faster than using a mesh, but the assets we are talking about today are the ones that can’t be easily approximated that way.
[1] In TaleSpire, the world is chunked up into 16x16x16 unit regions called zones
[2] IIRC it also affects clearing the texture, which is handy.
[3] I used the GL docs as I think they are clearer, but this is also true for DirectX.
[4] Especially for creatures. We only used the high-poly collider meshes there as accurate picking was so important.