From the Burrow
Heya folks!
In preparation for creature modding feature shipping, we are making the tool available so you can try it out, and we can fix any egregious bugs you find.
You can find a guide on how to get the tool and how to use it over here:
https://talespire.com/taleweaverlite-guide
NOTE: You cannot load the mods into TaleSpire today. This is simply a build of the tooling used to make the mods.
What is this (and what is it not)
TaleSpire is going to have a couple of ways for you to add new creatures to the game:
- In-game creature creator: A way of building creatures out of a palette of configurable parts
- Mods: mod-files are composed of pre-made assets outside of TaleSpire
TaleWeaverLite is for the second approach. It is a very minimal tool for composing pre-made assets into a creature mod that is ready to be used by TaleSpire.
It is not a modeling or posing tool. It expects content in specific formats and with specific layouts.
The expected usage is that the mesh and textures are prepared in other tools, such as Blender, and using TaleWeaverLite is the final step in making a mod.
The good
Once you are producing meshes and textures in the correct format, it’s trivial to turn them into a mod. Simply drag them into the Unity project, set the fields in the creature panel, and save.
The meh
We’ve been using Unity for our asset tools for a long time. It handled processing assets for us and gave us a UI we could use to make tools.
This means that to use TaleWeaverLite, you need to install the free version of Unity.
We have mixed feelings about this, as packaging this stuff for public use has not been as easy as we had hoped. Your feedback will help us decide whether to stick with this in the long term or to start moving to a more standalone tool.
The future
We are busy working on the backend changes needed to support the new creatures. Once we have that done, we’ll wrap up the needed changes in TaleSpire and get ready to ship. We are pushing hard for this and hope we can get this in your hands very soon.
By getting TaleWeaverLite out now, there might even be some new creature mods ready to ship the moment that TaleSpire gets the feature!
Until then, thanks for stopping by.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 442
Hi again folks,
In yesterday’s dev-log, I talked about us working with TitanCraft to help you bring your creations into TaleSpire.
The first thing they would like to do is allow their users to export their miniatures in the TaleSpire creature format. To that end, I’ve been working on a command-line tool they can use in their export pipeline.
Today, I fixed a bug in the handling of thumbnails, and suddenly, we had TitanCraft creations in TaleSpire.

These are looking very much at home! [0]
The rest of the day was spent on tweaks and fixes as we tried more minis.
Tomorrow, I’ll be looking at scale. TaleSpire has some limits on scaling due to our current movement code not being enjoyable once things get really big. As with our HeroForge support, we will need to massage the input to work well with our system. It’s something we’ve done before, though, so it shouldn’t be too hard.
That’s all for now,
Peace
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] Please note that these visuals are not final, we will likely tweak the shader before this feature ships.
TaleSpire Dev Log 441
Heya folks,
Today, I’ve been working on something different. A feature, for sure. But not one that goes directly into TaleSpire.
Today, I was making a program that can fit into TitanCraft’s pipeline so that, sometime in the future, you’ll be able to download TaleSpire-compatible assets right from their creator!
For those who don’t know, TitanCraft is an excellent way to create miniatures online, both for downloading and also 3D printing. If you haven’t checked them out before, I’d recommend it. Their approach to asset packs is really neat.
We’ve been chatting for a while about working together, so getting started on this is a lot of fun. My main task for today was taking TaleWeaverLite and reshaping it into something that could run headlessly. The goal being that they can then use this as part of the export process. I haven’t tried to share the codebase with TaleWeaverLite yet as I’m not sure how this project will evolve, but I expect we might do that once we know what shape this will be in the longer term.
I got the basics working. We have a command-line tool that takes a digital miniature, and repacks it for TaleSpire. They result opens in TaleWeaverLite, but I’ve got a few bugs in-game that I’ll fix up tomorrow.
Oh, and just in case anyone was worrying, no, we aren’t moving away from HeroForge or anything like that. We love what they do, and we’d like to work with more folks in the space, not fewer! So, if you have a favorite way to bring characters and content into your adventures, why not let us know at https://feedback.talespire.com. If it’s been suggested already, please upvote it. We keep an eye on the vote to help prioritize what we are up to.
Anyhoo, that’s all for tonight.
Have a good one!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Feature Release - Builder Presence
With this release, we start showing GMs what other GMs are building. This increased ‘presence’ helps you know who is working where and on what. It brings a little of the naturalness of building together that can be lost when moving to a digital space.
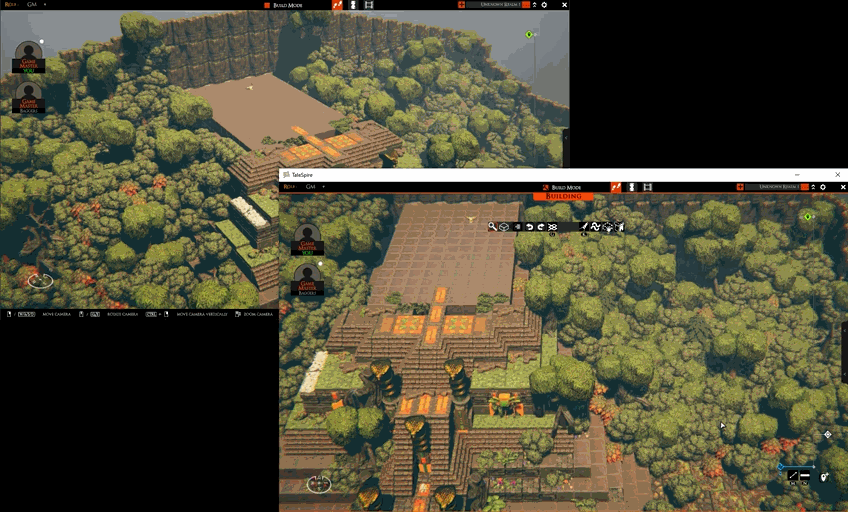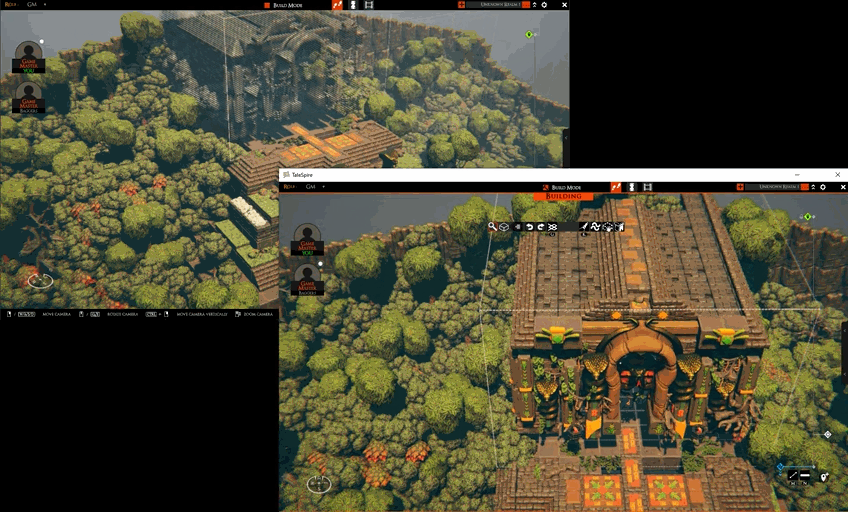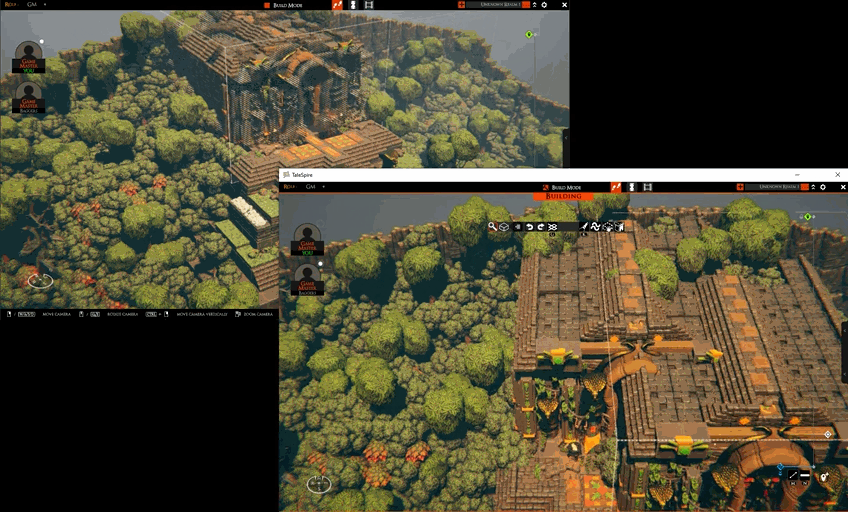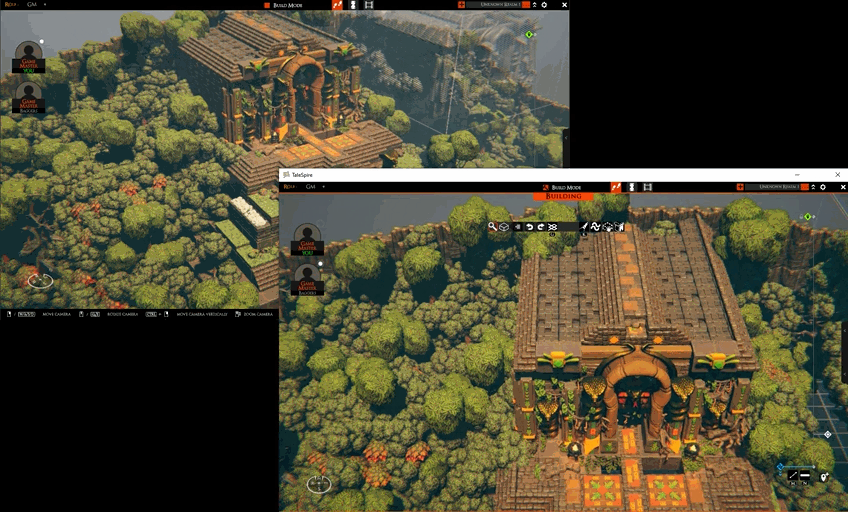
As always, let us know what you think. This is not the last iteration of this tool, and your stories help us find what we need to build.
See you in the next release!
BUILD-ID: 14438443 - Download Size: Win / Linux 2.8 MB / Mac OS 8.8 MB
TaleSpire Dev Log 440
Hi folks,
Just a quick log for today. I’ve tweaked the visuals of the build preview we will show for other GMs. I added a new shader and UI to show the dimensions of any region of tiles the GM is dragging out.
I’ve also started working on a tool for a 3rd party to take their assets and produce tsMod files. We’ll chat more about that and who it’s for another day :)
Alright, I best be off,
Have a good one folks!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the teamdidnt
TaleSpire Dev Log 438
Hi folks,
Bug month may be over, but the bugs certainly aren’t. Today, I’ve been working on some server-side bugs. I didn’t want to tackle these last week while @borodust was away due to the risk of causing a problem that would send him alerts during his vacation!
All the fixes are minor, mainly cases where we weren’t sending messages to the clients in response to events like boards being imported.
I will test these fixes shortly, and then tomorrow, we’ll look into pushing them to staging.
That’s all from me tonight. Hope you are doing well.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
Bug Month Patch 10 - The patch that already happened
This is going to be more of a dev-log than a release post. It turns out that, along with the assets we shipped yesterday, I had also accidentally pushed the fixes I was in the process of testing.
Luckily, the fixes have passed the tests, so I’m putting this out there to let you know what they were.
If you updated yesterday, then good news! You already have these fixes. If you didn’t… GOOD NEWS! You’re getting them in your next update!
The fixes in question were.
- We have fixed a shadow bug that would manifest if there were more than 500 of a single kind of prop in a 16x16x16 region
- We wait a little longer before retrying the pinging of Photon servers
- We removed the slight hover that props had during placing. It made it really hard to line up props accurately
- We now snap the position of the prop you are placing to hundredths of a unit while in your hand. The snapping is always done when the prop is placed, so this change ensures that you are seeing what you will get when you place the prop.
- Unity wasn’t showing some lower framerates, so we tweaked settings to show lower frame rates if they are integer multiples of valid frame-rates. This is a hack, but should help some folks who want to set TaleSpire to 30fps
Lastly, Mac users may have noticed that, on macOS, we now save screenshots to the desktop. This is because the old location was super ugly and tricky to get to. We will replace this with a path you can configure in the future.
Alright, I’m gonna get back to work and see if I can get something ready for tomorrow.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
Bug Month Patch 9
We are back with the second patch of the day.
In this release, we:
- Fixed a bug where props in the hand would animate constantly.
- Fixed a bug where props turned into creatures would animate constantly.
- Fixed a tutorial where the keybinding information was not responding to settings changes.
- Minor fixes to wording in tutorials.
- Add help bar hints to assist with rotating tiles and props
For those who hadn’t seen the first two bugs, this is how dumb it looked.

Really kills the space survival vibe when a crate is going full muppet!
We have another release going through testing now, so come back tomorrow for new goodies.
Ciao.
BUILD-ID: 14438443 - Download Size: Win / Linux 2.8 MB / Mac OS 8.8 MB
Bug Month Patch 8
This patch didn’t make it out last week so we are kicking off with it now.
It fixes a single, but confusing bug where tiles are seemingly hidden by a hide-volume but not actually inside one.
We will be back very soon with fixes.
BUILD-ID: 14643688 - Download Size: Win / Linux 2.9 MB / Mac OS 7.1 MB
TaleSpire Dev Log 436
Hi folks,
Yesterday was spent working towards a fix to prevent cases like the lost build session we spoke of in the last dev log. It’s coming along, but I’m going to give it another afternoon of thought as we can’t afford to get this wrong. It should go into testing later this week.
Yesterday, I also had a long tag-testing session with @chairmander. We picked some creatures and then tagged them using the new system so we could compare our results. As you might have seen in dev-log 434, he’s been working on a set of “blessed tags” and a sort of questionnaire that guides us towards some consistency in our tags across creatures[0].
The testing went well. We found some bugs in our prototype tagging tool, tweaked a couple of questions, and modified a few tag relationships that didn’t hold up under use.
Today, I’m handing this over to a contractor who has not been involved in any of this work. They will then do the same exercise as we did yesterday, and @chairmander and I will see how it works in practice. This is important as we’ve been looking at this problem for a while, so our biases and assumptions are very much baked into the system.
The contractor will then spend a couple of days tagging. We’ll get feedback, make necessary tweaks, and then unleash them on the rest of the creatures. In parallel, and as soon as we are happy enough with the blessed tag list[1], we will upload them to mod.io and start working on some UI for you folks to be able to use them.
Alright, I’d best be off. I need to get a little work done before the daily.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] It is possible to add custom tags, but a core set offers consistency and also lets us upload them to sites with fixed tag lists like mod.io.
[1] This list wont be final, but will hopefully represent a good start.