From the Burrow
TaleSpire Dev Log 341
Heya folks.
I’ve now packed up my computer, ready for the move, but I did get some stuff done before then.
I’ve made the first pass at including groups in the HeroForge browser.

I’ve merged the polymorph UI branch into my dev branch and am currently working on bugs. Currently, I’m updating the code to push scale along with the morph data so that players get the correct result even if the asset hasn’t finished loading yet.
The scale work required back-end updates to make unique-creatures handle this correctly. That is done and is looking good so far in testing.
I think that’s the interesting stuff for now. I should be set up for work by Monday, so I’ll see you then.
Ciao
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 340
‘Allo folks!
We’ve been chugging away on fixes and features as usual. With a long weekend coming up, we’ve been working hard to make sure things are as stable as possible for those days.
HeroForge made minis from packs available to TaleSpire yesterday. This rollout was not perfect, and we uncovered some details that had slipped by us. We’ve been chasing down issues that resulted from that, and once we push out a small patch later today, we should have workarounds for the most egregious bugs.
Next week I will be looking to improve the speed of fetching the HeroForge data. Currently, it’s pretty slow for large collections.
While fixing the above and the other TaleSpire bugs, I’ve also started work on “move-rulers.” These will be a feature you can control locally, and the first version looks like this:
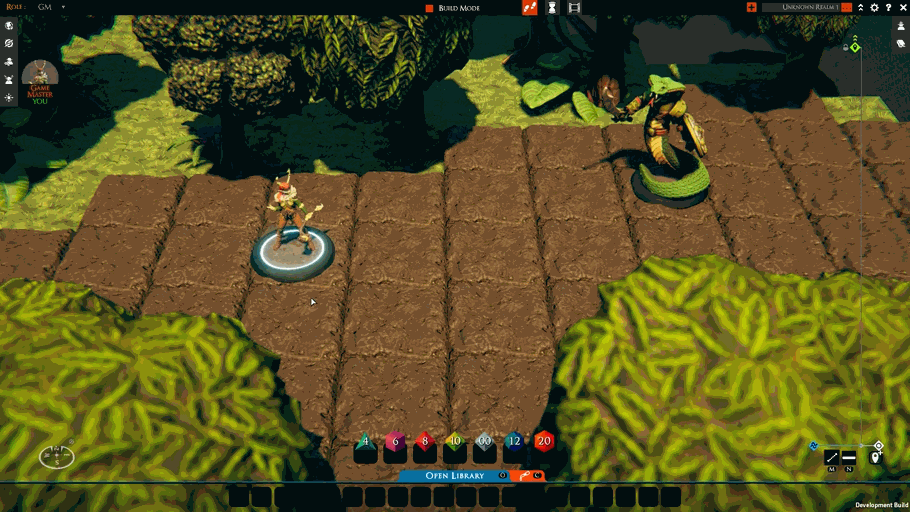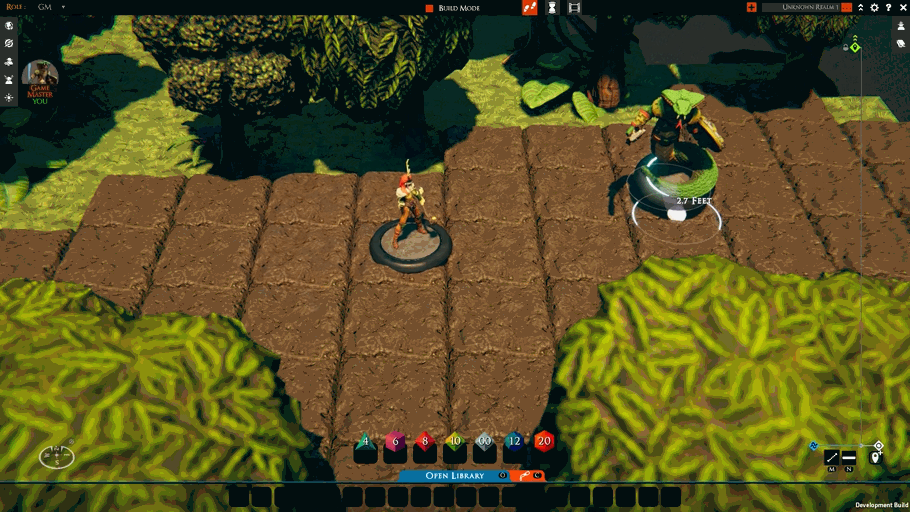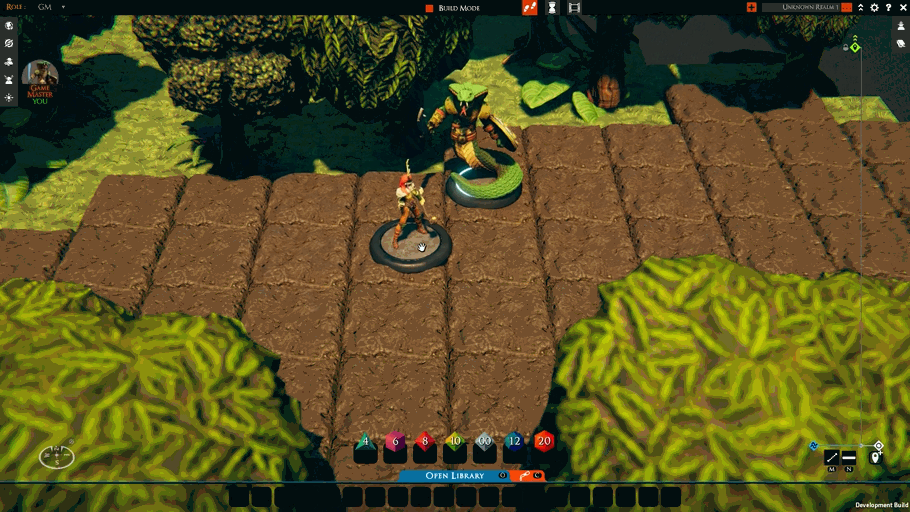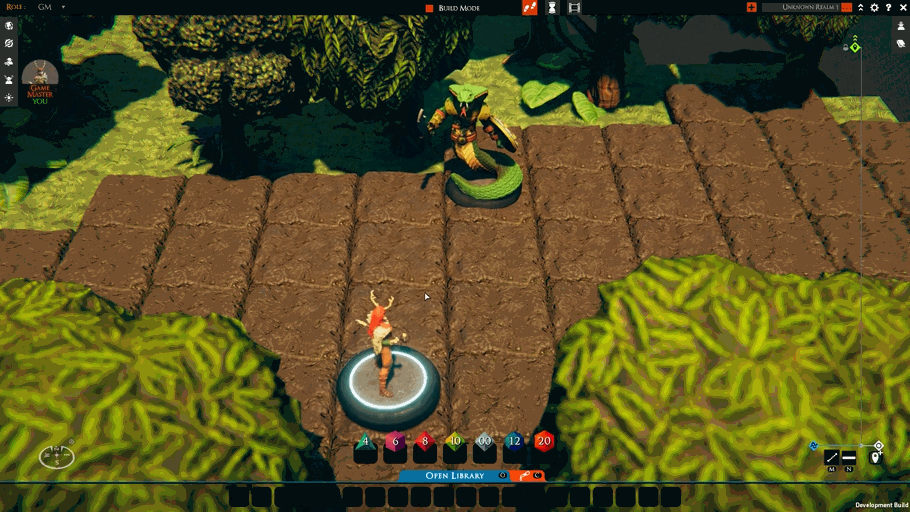
This should be a nice, lightweight complement to tactical rulers.
Not much work remains for the move-rulers feature. I need to add some UI for toggling it on or off and to clean up a few edge cases.
Until next time,
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 339
Hi again folks,
Work continues at speed over here. We will have another patch out for you pretty soon that fixes some mouse glitching, scroll speed issues, and a bug that meant people were stuck on the main menu.
As well as that, work has restarted on other features. I’ve been working on one nicknamed “tactical rulers.” The idea is that in tactical play, it is often nice to be able to leave the ruler on the table for a minute while doing things like moving creatures. This feature seeks to support that.
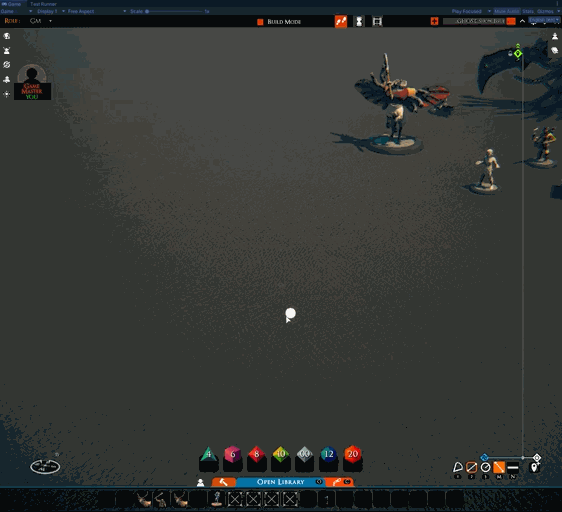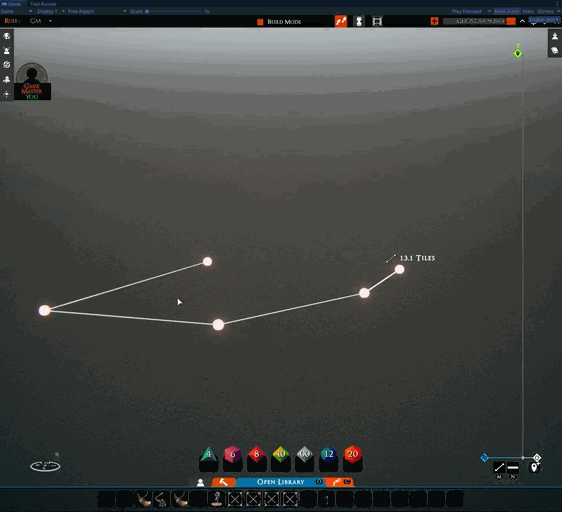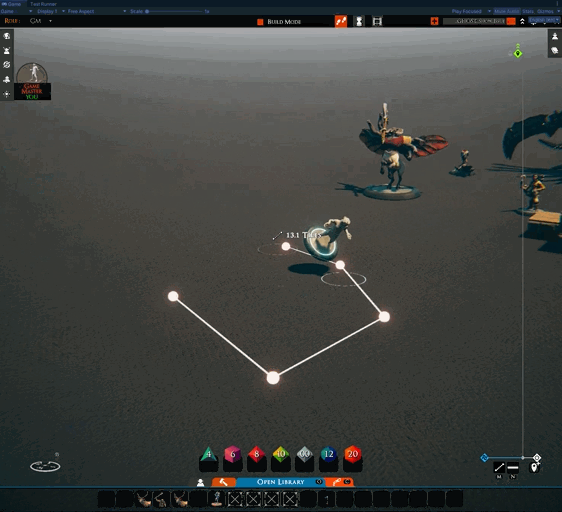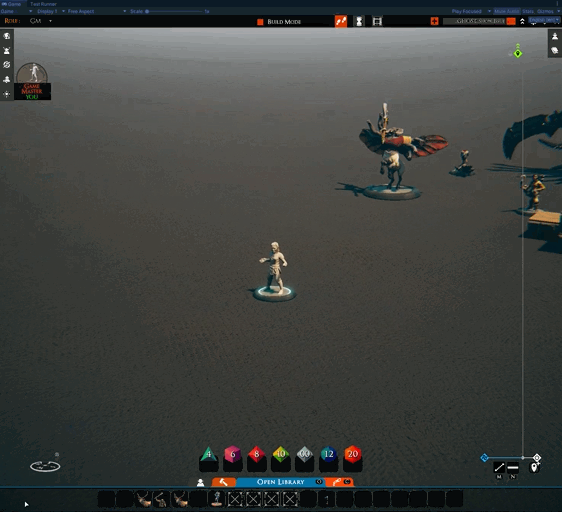
Note: this is an early test, hence the unused icon in the menu
Another benefit is that, in the future, we can add more features to the ruler right-click menu, such as turning them into markers for area-of-effects spells and such.
That’s all for the moment,
I hope you have a great day.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 338
Hellooo!
We have passed the first 24 hours of having shipped the HeroForge integration, and things are going well!
I’ll be honest that there were so many moving parts to this that I was expecting everything to be on fire at this point. It’s nice to be wrong.
Yesterday’s release included not only HeroForge support, but also:
- the vast majority of the code for the polymorph feature
- a jump to the latest version of Unity
- changes we needed to revisit creature copy/paste.
Today I’ve been working on bugs, a couple of which I’ll highlight here:
One is a regression to some of the sign-in code, which has left a few people stuck on the main menu.
Thanks to a community member, we’ve been able to get some very helpful logs, and we are testing some possible fixes over the coming days.
Another issue was that minis with transparency were failing to convert. While we aren’t supporting translucent HF minis, we don’t want the conversion to simply fail. It turned out that the issue was that those minis were missing a texture that we otherwise expected to be there. I added a new code path to handle this case.
In the near future, HeroForge will be updating their site to give more information about what is supported. So hopefully, there will be much less chance of unwelcome surprises then.
That’s probably the most interesting stuff I have to say for now. I’m diving back into feature work now! I think I will continue working on the next version of the rulers feature. Until next time.
Peace
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 337
Long time no dev-log!
Just a quick heads up to let you know that there will be brief server maintenance on Monday, 25 April 2022, 10:00:00 UTC
You can see what time that is in your region here: https://www.timeanddate.com/worldclock/fixedtime.html?msg=TaleSpire+Server+Maintenance&iso=20220425T12&p1=187&ah=1
We have scheduled one hour for the work, but we will only be using all of that if something goes wrong. The expected downtime is under a minute.
This maintenance is in preparation for an upcoming feature release :)
Have a good one folks.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 336
Hi folks,
You may have noticed that I’ve been gone for about a week. The reason for that was that I caught the flu, and it’s been doing a merry dance on me since then.[0]
I’m not entirely back to normal, I still run out of energy after about five hours of being awake, and my coughing sounds like some satanic accordion. But I am on the mend.
My sincere apologies to those of you who I’m meant to have contacted. It simply hasn’t been possible. I’ll catch up when this passes.
For those wondering, yes, this did affect the HeroForge release date, although it has not changed the month it is happening. Also, this has not given us extra time for polish, as I’d haven’t been able to code at all while ill (which has been driving me crazy!). That said, other TaleSpire work has continued, and Ree’s latest post is mind-blowingly exciting.
Here in Norway, we have Easter break rapidly approaching, so we will be away for that. Ree will be along with another dev-log talking about that, though.
Thanks for bearing with us, folks. I can’t wait to be back working while not rattling.
Take care
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] I did test that it wasn’t COVID, which was a relief.
TaleSpire Dev Log 334
Hey folks, I’m quite frazzled today so no proper update of what’s going on. I can say though, that it’s all going well, and we are still expecting the beta launch to happen on the same date that we still aren’t telling you :P
In lieu of text content, have some video content!
This is a speedy video showing the process of connecting a HeroForge account, linking some creatures to the campaign, and showing how things respond to being unlinked and relinked.
We are still working on bugs[0], and the UI is still changing. However, we are excited to make the experience as smooth as possible. So that this could be done effortlessly, even in the heat of battle.
Please note that you do not need a HeroForge account to play with miniatures created by other players, even if you are the GM. An account is only required for sharing your creations with a campaign.
Alright, I’m heading out.
Have a good one!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] that ugly lag when opening the HeroForge menu is already fixed, for example.
TaleSpire Dev Log 333
So while we wait to announce the release date, let’s talk about some other details.
The road to HeroForge release
The release itself is going to be a two-parter. First, there will be a short open beta, and then the more public “launch.”
Now, this is a bit unusual for us, so why are we doing it?
In short, HeroForge has a much larger community than ours[0], and when they publicize a new feature, a lot of folks will rock up to try it out. By having a short beta before pushing announcements everywhere, we all collectively get to kick the tires and find any scary bugs that snuck in before any bigger rush of people.
There are no restrictions to participate in the beta beyond having a HeroForge account[1]. The doors will be open, and you are all welcome in, but we won’t be doing a big PR push immediately, and the word “beta” will be slapped on a bunch of places.
Once both teams are happy, we will remove the “beta” label and then fire up the social medias, blast out announcements, and see how it goes!
The fact there is no restriction will confuse a few people, but after having you wait for so long, we couldn’t stand the idea of only letting some of you in for the beta. This feels like a decent trade-off.
Coming soon
Already we are turning our eyes to what we will be working on next. The art team will be busy with the cyber-punk and scifi pack, so it’s definitely a good time to ship some features.
This is ideal as we have a ton of stuff that feels 80% done and just needs that work to get it out the door.
Even if we marked it experimental and required turning it on in the settings, it would be good to get this stuff out.
One example of this is the change to rulers I’ve been calling “tactical rulers” internally. That change means a ruler isn’t cleared the instant you click on something else. This makes moving creatures (especially troops) pre-measured distances much easier. It is also a requirement for us to be able to start on area-of-effect markers (but that’s a different story).
Another thing that marries well with tactical rulers is group movement. Ree has already put a lot of work into that, and getting the last 20% feels doable.[2]
I feel like I’m tempting fate if I start teasing the other features in that “80%” category, so I’ll leave it for now, but I’m feeling very optimistic about what comes next.
That’s all for today
So yeah, that’s the lot for this log.
More news in the next one.
Have a good day!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] But hey, no trades, our community rules!
[1] Of course, you or one of your party will need to have bought some digital minis to be able to bring them into your campaign.
[2] We will probably limit the number of uniques that can be added to a group initially. This is due to the amount of data that must be sent to the backend on each movement. I know what changes I need to make on the backend to make this more efficient, but that will take some more time. Non-unique creatures are handled totally different and so won’t have that restriction.
TaleSpire Dev Log 332
Hey folks!
Things are going great over here. Here’s the latest from me.
Server stuff
Last week was given almost entirely to server work, continuing the work from the previous log. I was able to get our Packer scripts up to the point where it completely replaces how we were building our old docker containers and Amazon AMIs. They’re also way easier to maintain.
HeroForge
We had a planning meeting with the HeroForge team last Friday, and we now have our internal timeline, which is super exciting for us. I say ‘for us’ because we aren’t telling you the date yet so as not to put extra pressure on both our teams.
While that date is ‘soon,’ I’ve probably said ‘soon’ in so many different ways already that it doesn’t really convey how soon we are talking, but you’ll see pretty quickly from what I’m up to how close things are.
Speaking of which!
I am currently working through my last coding tasks marked mandatory for release. All of these are related to handling failure cases and how to expose the issues to the user.
Then I’m onto the tasks marked as things we really should have. This currently includes:
- Adding a panel for managing errors (which will be essential for modding)
- Changing where the HeroForge thumbnail data is stored
Ree has been working on the UI, and as soon as that lands, I’ll merge my stuff and start recording videos of the entire flow of importing minis. It’s a very short process, but we need tutorial content for TaleSpire and HeroForge’s sites.
That takes us to the rest of the work leading up to release. We need to:
- Produce various texts, videos, and images for documentation
- Set up a new Steam branch for testers
- Chase things up with lawyers (for the wording of the ToS around HeroForge)
- Work out our point of contact for HF if they need support
- Write up our PR stuff for the release
- More testing
Writing stuff for humans always takes way longer than I think, so I’m aiming to have as much of the coding done by the middle of next week as possible.
Aaaaaaaa it’s exciting!
We have also been preparing for the feature work we will be doing immediately after this ships. I think we’ll be able to have some cool features landing before sci-fi ships :)
Alright, enough vague info for one day! I’ll be back soon with as many extra details as I can share.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 331
Hi folks,
Let’s start with HeroForge news. We’ve been working closely, iterating, and finding shortcomings in the format for some time now. As of yesterday, we have finalized the format and conversion process and are looking to the next milestone. We obviously wouldn’t announce any dates for a potential release without HeroForge’s involvement, as there are naturally a lot of overlapping concerns. Not just technically, but from the PR side too. So today, all I’ll say is: Things are looking good!
I’ve also continued work on the backend. I have been working heavily using terraform to get all our backend infrastructure defined as code. In the future, we want to be able to spin up services[0] in whole new regions trivially, and this should let us do that.
Currently, I’m experimenting with an unfinished setup in the EU. This never went live but is a reasonably clean setup and makes for a good testbed.
Please note: I’m not experimenting with live infrastructure. None of this is currently used by TaleSpire, and so any bugs you hit are not related to this :)
As part of this process, I’m working with another tool from HashiCorp, packer. Packer is letting me define our docker containers and AMIs from common scripts.
Previously we have run docker containers on our EC2 servers. However, the separation from the host has caused complications in the past, and, personally, I prefer just using docker to make development cleaner. My goal with packer is to make our AMIs and containers as close to functionally identical as is reasonable. This will remove a small overhead[1], simplify some edge cases, and make building AMIs waaaay easier[2].
Today I’ll continue with that backend work.
Seeya folks!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] Using this term generally, we don’t use a microservice architecture [1] Which won’t matter now, but that I believe certainly would if we start taking on more real-time traffic [2] I could probably argue that it will make the dev environment closer to the running environment, but that’s another ramble.