From the Burrow
TaleSpire Dev Log 243
Hi!
On Sunday, I was reading about Unity CommandBuffers as I need to rewrite the code that handles the cutaway effect. At the bottom of the page was a link to this blog post where something caught my eye. They were talking about custom deferred lights. This was exciting as lights are the one place where tiles still need to use Unity GameObjects.
In our quest to improve TaleSpire’s performance, GameObjects have long been our nemesis. They are (relatively) slow to spawn, use managed memory, and only interactable from the main thread. To avoid lag, we have to spread light spawning over multiple frames and work pretty hard to apply updated transforms to the GameObjects from the Spaghet scripts that can modify them.
If we had a way to draw lights without GameObjects, we could significantly simplify a lot of code. The temptation was too great, so I’ve spent the whole day working out how to do this.
The good news is that it worked. Here is an ugly test.

We use a standard Unity light on the left, and on the right, the new approach. They should look the same. The reason for the pattern in the light is that I knew that we needed to support light cookies, and so I included that in the test. The non-cookie case should be more straightforward.
Ok, back to the blog. The author has included a fantastic example project, which was the first concrete proof that this should be possible. I had one extra complicating factor; however, I didn’t want our lights to look any different from the Unity ones. To me, this meant trying to drive the built-in Unity Shaders somehow. Due to my inexperience with this, I had a bunch of false starts, but I eventually understood the general flow of the rendering process. There is a good, though terse, a summary of the approach here.
Things were looking promising but, try as I might, I could never get the built-in shaders to have the ZWrite or Stencil settings I needed. After many failed experiments, I simply copied the bits I needed into a separate shader to apply the flags myself. This process was easier said than done, and a lot of time was spent in the frame-debugger.
It’s all looking very promising, but there is still time for it to all go wrong :P
The next step is to make sure this works with multiple lights. Then I can extend this to support spot-lights and more of the standard point light settings. Once those are done, we will change how TaleWeaver packs light data, and then finally, we can refactor the light batch in TaleSpire to use this new system. I wonder if we can get some idea of performance without doing all of this… we shall see.
Alright, that’s all for today. Seeya around!
TaleSpire Dev Log 240
Heya folks!
As you may have seen, the dice URL support just shipped today.
This post will be in two parts. The first is about how dice URLs are formatted, and the second part will be the usual grumbling about bugs :P
Url Anatomy
All TaleSpire URLs start with talespire://. From there on, we have some number of path segments.
We call the first path segment the “behavior identifier”. The behavior identifier tells TaleSpire how to interpret the rest of the segments.
For example, in talespire://dice/d12, dice is the behavior identifier and tells TaleSpire to interpret the rest of the path as a dice roll.
Currently, we only support basic dice rolls with the
dicebehavior. In the future, we will support more complex dice rolls as well as other different behaviors.
Next, let’s take a more complex URL and break it down. We’ll use this as our example: talespire://dice/1d12/4d6-1d4/4d10+2/3d20+1-d6+2
First, we’ll ignore the scheme and behavior identifier, which leaves us with these path segments: 1d12/4d6-1d4/4d10+2/3d20+1-d6+2
Each path segment specifies a “dice group”. The roll results of each dice group get totaled separately. You can see an example result from the above roll here:

A dice group is parsed, right-to-left, case insensitively, with the following regex: (\+|\-|)\d*D\d+(\+\d+|\-\d+|)
The C# code to do this is:
var diceGroup = Regex.Matches(pathSegment, @"(\+|\-|)(\d*)D(\d+)(\+\d+|\-\d+|)", RegexOptions.RightToLeft | RegexOptions.IgnoreCase);
The extra brackets in the C# regex above were added so that the Groups field contains the most useful data already separated. Naturally, you will need to reverse the results to get them in the correct order.
The regex is the most accurate specification, but here is a simpler (though maybe less precise) version with extra details.
[optional operator][optional count]D[sides][optional modifier]
where:
operator: currently, the only operators supported are+and-.count: is the number of dice of that kind. Zero is not valid, but if it is not specified at all, then the count is one.D: is only uppercase in the regex to clearly distinguish it from the\ds. The regex is always case insensitive.sides: is the number of sides of the die. Currently, we only support the standard TaleSpire dice. We will need to expand to support dice modding.modifier: here, you can specify an integer to add or subtract. It is always of the form+Nor-NwhereNis a positive integer
Three points of interest:
Negation
As the operator is part of the group, a valid dice URL is talespire://dice/-d6. This results in a negated dice roll.
Note that talespire://dice/d4-d6 is supported but talespire://dice/d4--d6 is not.
Righ-to-left
The right-to-left matching is critical to get the correct result:
Parsed left-to-right talespire://dice/d6-2d12-1 matches as d6-2 and d12-1, rather than what we want which is d6 -2d12-1
You can experiment with the right-to-left option by browsing here https://www.regexplanet.com/share/index.html?share=yyyyd9vu5ar and clicking the .Net button.
Note: remember to example case insensitive on regexplanet before clicking the ‘Test’ button
Garbage is ignored
Due to the lack of strictness in the specification, it is valid, although ugly, to have ignored text in the URL. For example: talespire://dice/horsed6horse-2d12-1horse is parsed to d6 and -2d12-1.
Arguably this should be made stricter.
Normal dev log
With that out of the way, time for me to grumble. Getting this feature out has been a huge pain in the ass. To explain why I need first to describe how this is set up, don’t worry, it’s super simple.
- TaleSpire adds a registry key on install that tells windows what exe to run when a
talespire://URL is launched. - We don’t want lots of copies of TaleSpire starting, so instead, we have
TaleSpireUrlRelay.exe, which either- launches TaleSpire and passes the URL as a command-line argument
- use some form of IPC to send the URL to the running instance of TaleSpire
One of the testers had an issue where the URLs would not arrive unless the TaleSpireUrlRelay was set to run as administrator. This was clearly a permissions issue, and so I started exploring the security options of the IPC I was using. This is where things get screwy.
But first, let’s wind back and look into how we got here.
Note: this account is intended as entertainment. I likely missed very obvious information along the way and misinterpreted errors that would have told me the real issue. I can’t accurately say which systems actually had bugs, but I can tell the little tale of how my week has felt. Enjoy!
So back in the day you might use SendMessage (or PostMessage maybe) with WM_COPYDATA. However, since Vista, this WM_COPYDATA is blocked for security reasons. However, there seem to be workarounds but this looks nasty, and it would be great to avoid this if possible.
Also, we want to port to Linux and Mac in the future, so something in the .Net framework would be much better. You could use a socket, but that’s very low level for what should be a straightforward thing.
How about websockets? We already have a client in TaleSpire, and we have stated we would like to expose a websocket API in the future. However, that has almost the opposite problem. It’s a huge piece of extra ‘machinery’ running in the game, and we don’t know how performant it would be. It would be much nicer to have something lightweight and then launch the websocket server only when needed. So let’s try and avoid the websocket approach for now.
Next, you land on Named Pipes. They look ideal, and in fact, you get them working fine for you. However, this is when that tester I mentioned reported the permissions issue. Dang.
You have a read of the documentation and see the PipeSecurity argument to the server constructor. “Yay,” you say, “this should be easy.” You take the example code from the docs, but it uses TokenImpersonationLevel.Impersonation, which seems to error in your setup. Ugh, maybe it’s best to read some more rather than copying more code.
A quick google, and you start hitting some scary posts which seem to suggest that it just won’t work… and you miss the fact that they seem to be about .NET standard so maybe it’s not relevant.
However, you have a lot of experience in cases where Mono doesn’t implement something normally available in .Net, so it all seems feasible.
A bunch more testing later, and the only pattern you have found is that the Named Pipes just don’t work if you try and specify the PipeSecurity. It doesn’t help that every tutorial you find has a different way of setting things up. Is the SID meant to be WellKnownSidType.AuthenticatedUserSid? or WellKnownSidType.BuiltinUsersSid? or WellKnownSidType.WorldSid?, or "Everyone", etc, etc.
Ok, so now we are worried that Named Pipes won’t work, what other options do we have? Hmm, IpcChannel looks promising. But, surprise surprise, when you copy over the code, it hangs. Now you have two implementations you don’t understand. Do you really want to keep down this road?
Maybe you do for a couple more hours, but “damn,” you think, “I just need something simple.” Perhaps you could dump the URL into a file and have a file-watcher in TaleSpire pick it up. Ugly as hell, but at least it could work.
You keep that in mind and look at the next option in the list, MSMQ. Oh wait, according to a blog, it’s “dead”… well, not actually dead, but you don’t need more confusion in your life, so after a quick read, you try to find something else.
Maybe .Net Remoting? It’s old as hell, but at least that means it isn’t changing all the time. You dive into some examples, and it’s built around pretending that the same object exists in both programs simultaneously. This model is gross, but hey, if we can get an example working, then maybe it’s… nah, we are running into issues connecting too.
There is this horrible balance you are trying to strike. You can try and implement a system using the tech you don’t understand, knowing that everyone gets stuff wrong the first few times, OR pull in some code someone else wrote and then have to learn that. Either way, this feature is taking way too long, and you desperately want to get it working, so you don’t want to put days into exploring each of these options.
Terrifyingly the SendMessage stuff is seeming like something you might have to reconsider. However, after checking out some example code and some fairly promising libraries you say “screw it” and go back to Named Pipes as that is the closest you’ve gotten so far.
BUT WAIT. There is something called AnonymousPipes, specially made for only local connections, with a simple API and. NOPE. It only works if the server process launched the client process, which is not the case for us. Ah well, back to Named Pipes
Now you are back where you started, poking at seemingly random things to find out what will happen. While flailing around, you decide to give the connecting client FullControl of the pipe. You didn’t try this before because you never want to grant anything higher permissions that it needs but suddenly, IT CONNECTS! You franticly whittle down the permissions until it’s the smallest set that allows the connection to work and then make a new build and give it to the tester who had the issues.
Same problem.
Just as you are about to pour a giant glass of the most potent drink you own, you casually ask them if there is any way they know that the game could be running as administrator.
“Oh…” they say.
It turns out that when they were helping test things for you half a year ago, they tried setting the exe to run as admin, and Steam, being a good little soul, maintained this flag through every update until now.
They remove the “Run as administrator” flag, and immediately the dice-URLs start working.
Now. This is not a story about where the tester screwed up; these things happen. This is a story of the sea of nonsense you sail through trying to work stuff out when almost no information you find online is truly reliable, and you don’t have time to learn it all from first principles.
In conclusion, this is why the URLs are three days late :D
That’s enough stupidity for one night. Seeya folks!
TaleSpire Dev Log 239
Heya everyone,
I got back from my break on Sunday, fully rested, and ready to build again!
For the last two days, I’ve been getting back up to speed by looking at the custom URL scheme code again. The last time I was working on this, I forgot that the custom URLs always try to open a new copy of the application they are linked too. That’s fine when TaleSpire is closed but no good if you already have it open.
To handle this, I wrote a little program that acts as a middleman for the custom URLs. It is called when one is used and then looks to see if TaleSpire is running. If it is, it connects to it using a named pipe and passes along the URL. If TaleSpire is not running, it launches it passing the URL as a command-line argument, and that argument is processed once the user has logged in.
In the future, we still think that we will expose an API for tools to hook into TaleSpire via websockets. However, that is a bigger task than I wanted to take on today, and I wasn’t sure of the performance implications. By default, I think that the websocket server would be disabled, and we’d use one of our talespire:// URLs to enable it and to fetch the connection details (like the port number).
As a test of this new code, I knocked together a simple (and rather unfinished) extension to TS that uses the custom URLs to spawn dice. It supports multiple totals within one roll and modifiers on every dice descriptor. For example, talespire://dice/2D12+2+1D20 spawns 2D12 with a +2 modifier and 1D20 and will sum them. talespire://dice/2D12+2/1D20 spawns the same dice, but the totals for 2D12 with the +2 modifier are calculated separately from that of the 1D20.
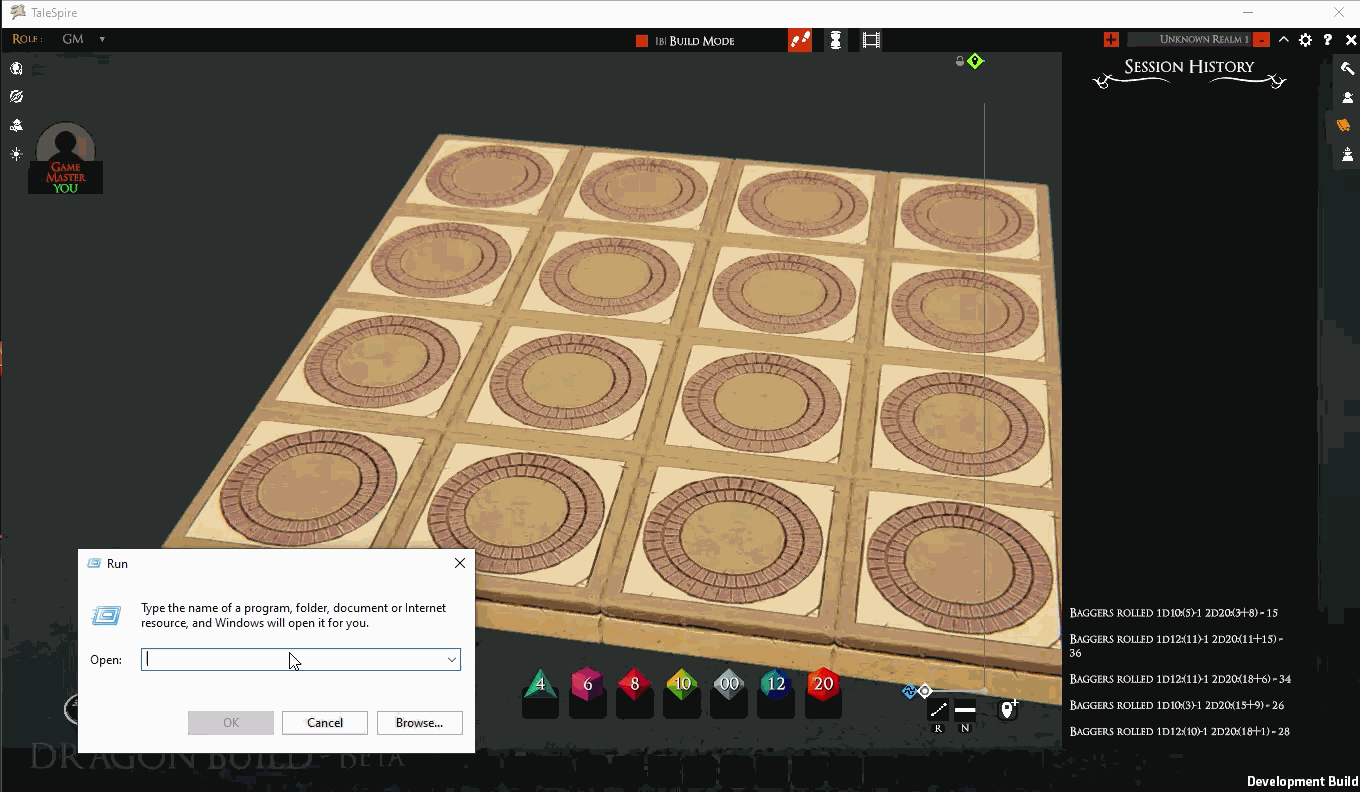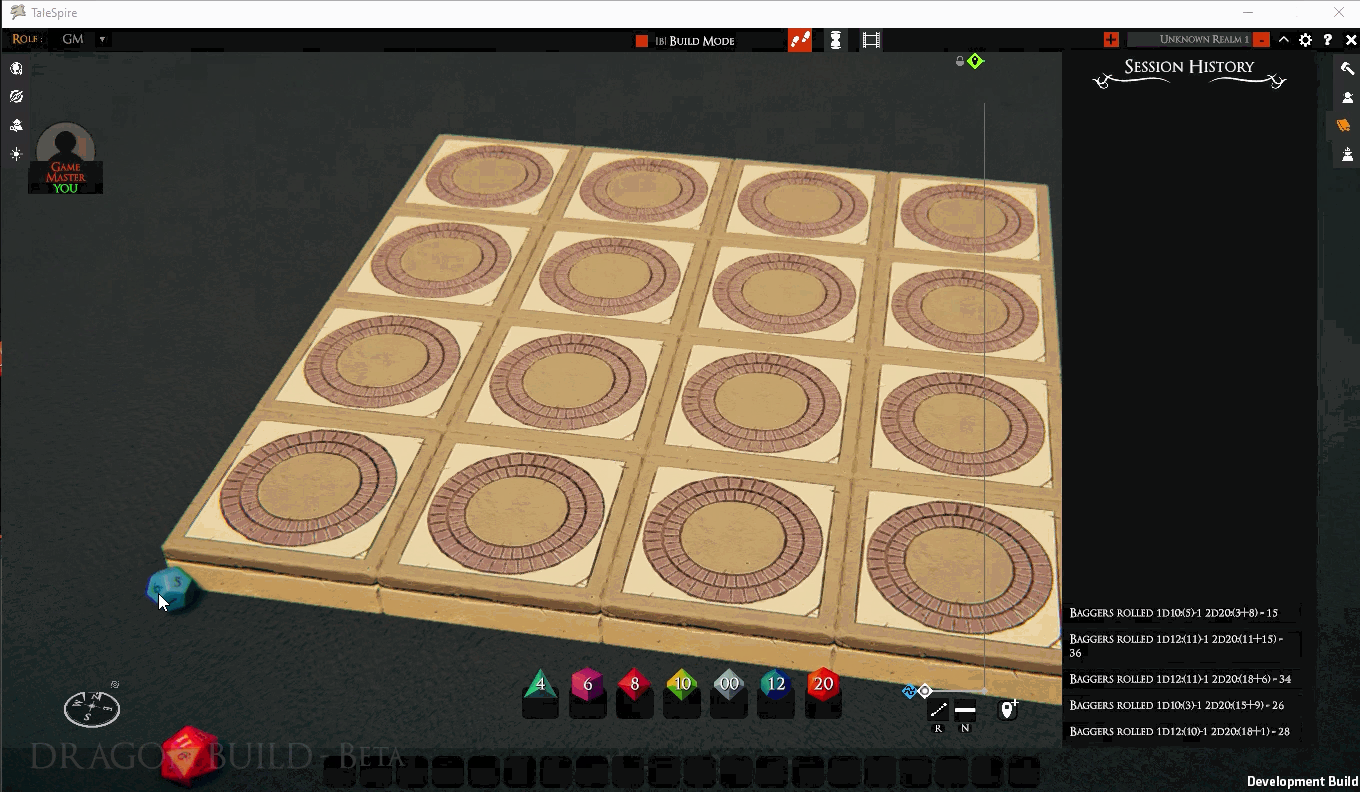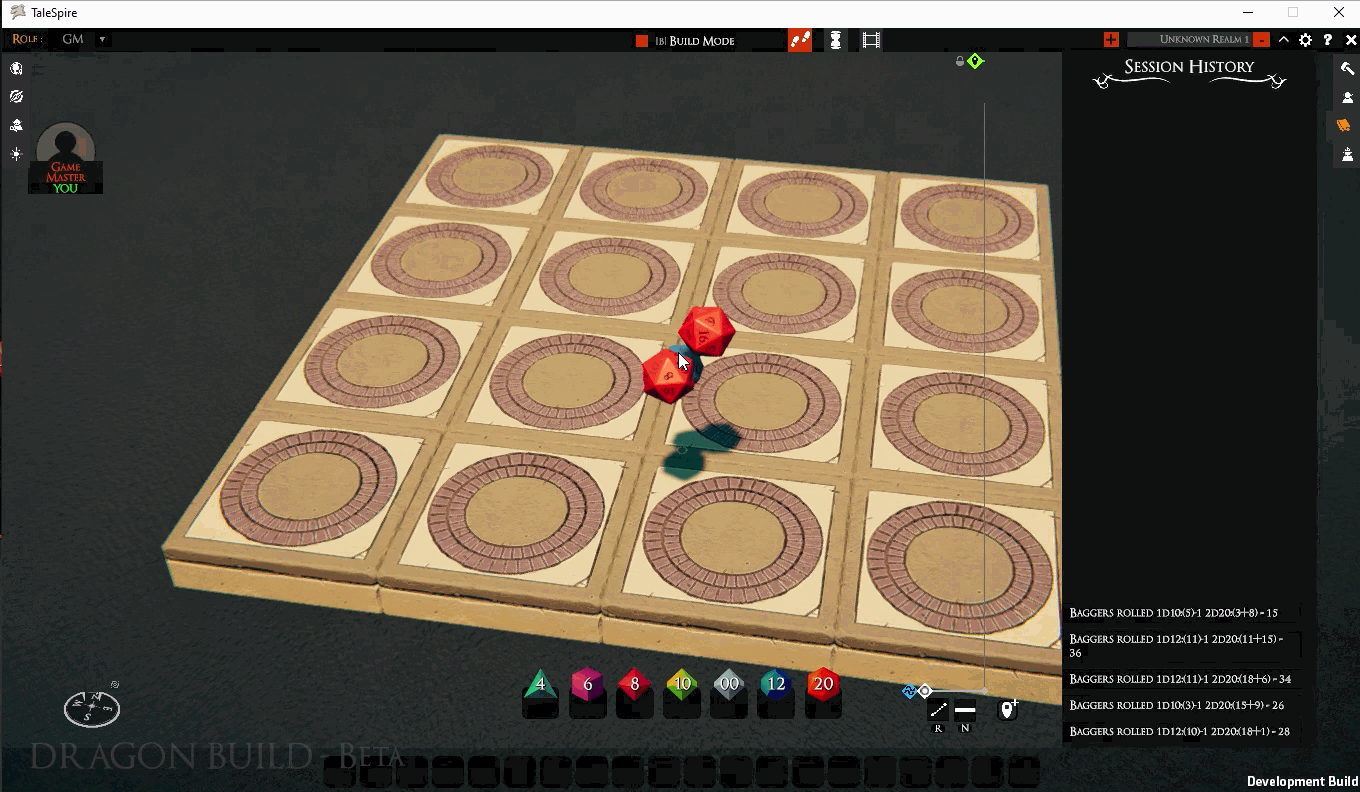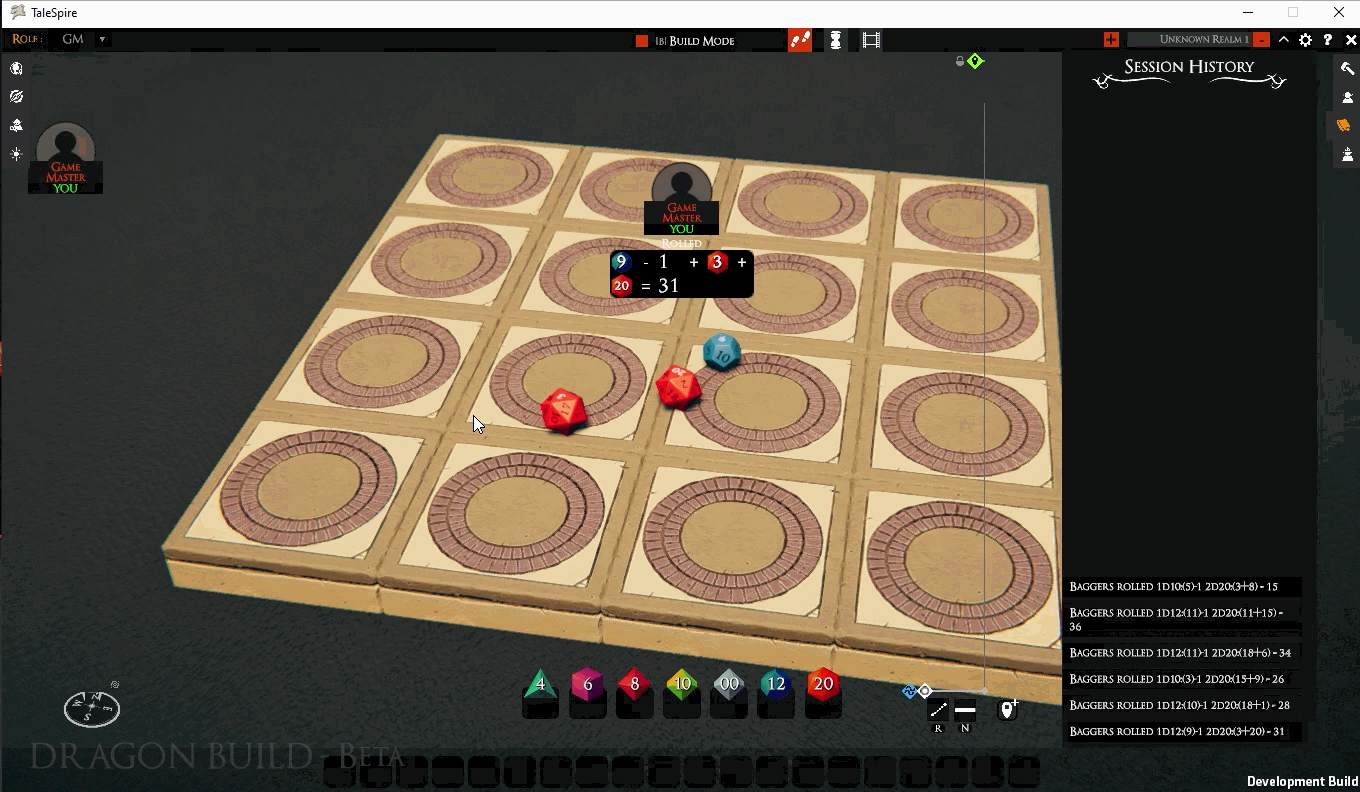
As you can see from the gif, there are still lots of things to fix. But it’s coming together. Once it’s working and we’ve play-tested (and we are sure we want to ship it), we’ll publish the specification for the dice URLs.
That’s all from me for today. Seeya!
TaleSpire Dev Log 236
Today in “I’ve not been working on line-of-sight but…”, we’ll be talking about things that ended up higher priority than starting on line-of-sight :P
On Friday, I was chatting to Ree about the next tasks on the list, and he suggested that it could be helpful to convert the boards from the beta format sooner rather than waiting for the per-zone-sync. At first, I balked at this, but after a sleep, I realized that much of the work would be valid even when we come to rewrite the new persistence system.
And so that’s where I’ve been. Format conversion is always sensitive, but Ι took the opportunity to simplify how we handle it. Now, each time we need to make a new version, we’ll:
- copy all the current types into a new numbered ‘legacy’ namespace
- strip out everything beyond the deserializing code
- write a converter from that version to the latest version.
It’s dumb and involves more leg work than fancier solutions, but it works. It’s reassuring to know that you aren’t accidentally messing with something needed by an older version of the board you still need to support when making a change. We’ll see how this feels to work with, but I’ve tried a couple of other approaches before and have found them lacking. Let’s see how Ι do with this one.
After getting conversion working, I realized the codebase was in a good place for some cleanup. I had a bunch of naming (of variables and types) that needed updating, and there is not likely to be another good time to do it before the Early Access. So Ι threw a few hours at this.
I noticed a case where, on photon failing to connect, we wouldn’t retry, essentially leaving you stuck with no board. I’ve put a simple retry in on my branch and will cherrypick this into master tonight. This will be available in the next release.
During testing of board format conversions, I found a case where the physics wrapper would incorrectly schedule some jobs. This is now also fixed.
That’s the lot for now. Back soon with more
TaleSpire Dev Log 235
Hi again,
Today I started out thinking I’d be working on line-of-sight, but instead, I dug into some issues we’ve had with builds since the Unity version upgrade.
First, one was that the dummy-asset resource wasn’t loading reliably on game start. This is very odd, and it feels like it’s a Unity bug. As we are currently using the 2020.2 beta, this is entirely possible. For now, I’ve worked around it by simply exposing a SerializableField for the prefab, which, to be honest, is probably a better way to do it anyway.
Next, I noticed that even though we had supposedly moved away from our old JSON asset format, I hadn’t converted the music asset files. This work began on the TaleWeaver side, and it was straightforward to get the music info into the new binary asset format. As I was upgrading the TaleSpire side to use this new data, I was able to do some cleanup, which totally separated the old asset-data classes from TaleSpire and so now TaleWeaver can own those. This is nice as both sides can evolve their formats in response to their own needs.
I then went on the hunt for an error that occurred when deserializing hide volumes. The TLDR was that, due to having moved to C# 8, a different method overload was being selected for a specific call. It took me a little while to spot, but it was a very easy fix. The C# change that caused this is actually the one I’ve been most excited for over the last year or two, unmanaged-constructed-types.
The code cleanup was really enjoyable, and, given that it was nearly the end of the day, I decided to do some more cleanup that had been waiting for the engine to get to this point. In this case, it was on the manager that handles asset loading and the manager that handles tiles and props. They were a bit too bound together, and their respected roles weren’t always clear enough. The changes themselves aren’t worth enumerating, but I’m happy with the result.
Tomorrow I might look at line-of-sight, or I might look at laying the groundwork for the new board format and the code to handle upgrading the current boards.
Seeya!
TaleSpire Dev Log 234
Hey folks,
Once again, today was mostly spent on physics. Having solved the dice ‘popcorning,’ we talked about yesterday, I was left with an issue that dice would slide around as if they were on ice. It looked like this:

I had assumed this was material related and, sure enough, I found several places where I had not been setting the materials properly when generating colliders. However, even with those fixed, the problem still remained.
This led me into a whole bunch of tests and tweaks which weren’t getting me very far. However, after some of the previously mentioned material fixes, I saw that things worked correctly on one of my test scenes. That scene was only using GameObjects with driven by BouncePhysics wrapped around Unity.Physics. The sliding must have been related to tile colliders, which are managed by the board and written into the physics engine separately. However, I had already set a material for all these colliders.
At some point, I finally noticed that the material I was using for the tiles (Unity.Physics.Material.Default) had a FrictionCombinePolicy than in the material I was using for other objects. For BouncePhysics, I was using a material converted from the default material found in Unity’s classic physics engine. The result of that conversion used ‘arithmetic mean’ for friction combination, whereas the Unity.Physics.Material.Default used geometric mean. I switched the tiles to use the converted classic material, and the sliding stopped.
This is good, of course, but what a silly mistake. I had just assumed the two would play well together.
Anyhow for completeness, here are the dice. They won’t behave like this when they ship. This is just to show the difference from the gif above.

With that done, I knew the next task was to rewrite line-of-sight, but that seemed like a pretty overwhelming way to end the day, and so I decided to play with something much more straightforward.
I’ve really wanted to experiment with adding a custom URL scheme for TaleSpire. This would mean opening a link that looked like talespire://<something> would open TaleSpire and do something useful. My first thought was that you could get a URL for a specific point in a particular board in your campaign. You could then share that with your party or even use it in external tools (World Anvil comes to mind), so you could link points in your documents directly to the TaleSpire maps that represent them. Also, if we support links out of TaleSpire, we could get a very basic but rather compelling way to move in both directions, which isn’t tied to any specific tool or system.
To add a custom URL scheme to Windows, I needed to write some registry keys. Steam seems to support this, but when I tested the registry options of the install script, I saw only partially made registry subkey trees. This was disappointing, but they also support executing other processes as part of setup. I assumed they would need to run as administrator, so I made a little c# script to add the required registry entries. This worked great. Here it is in action:
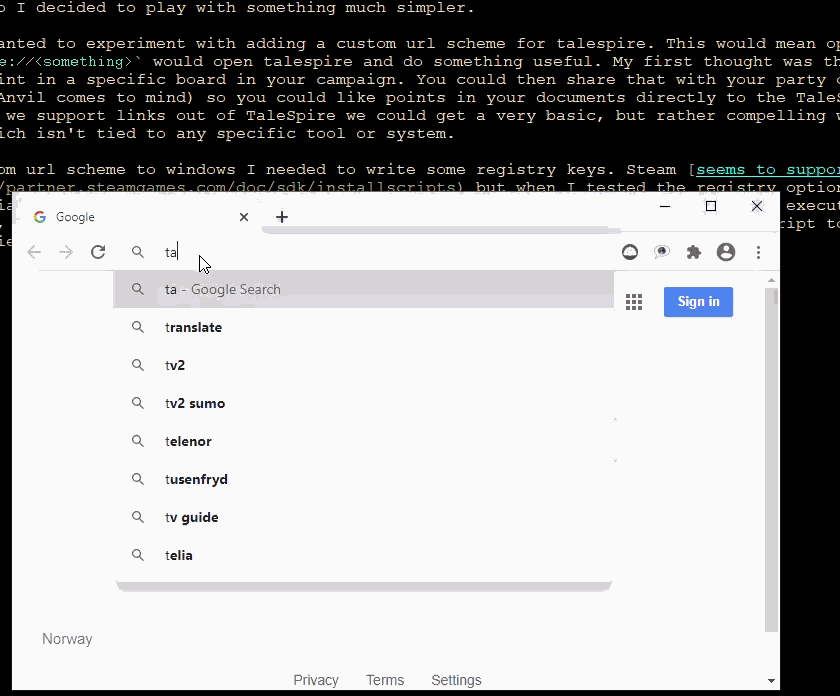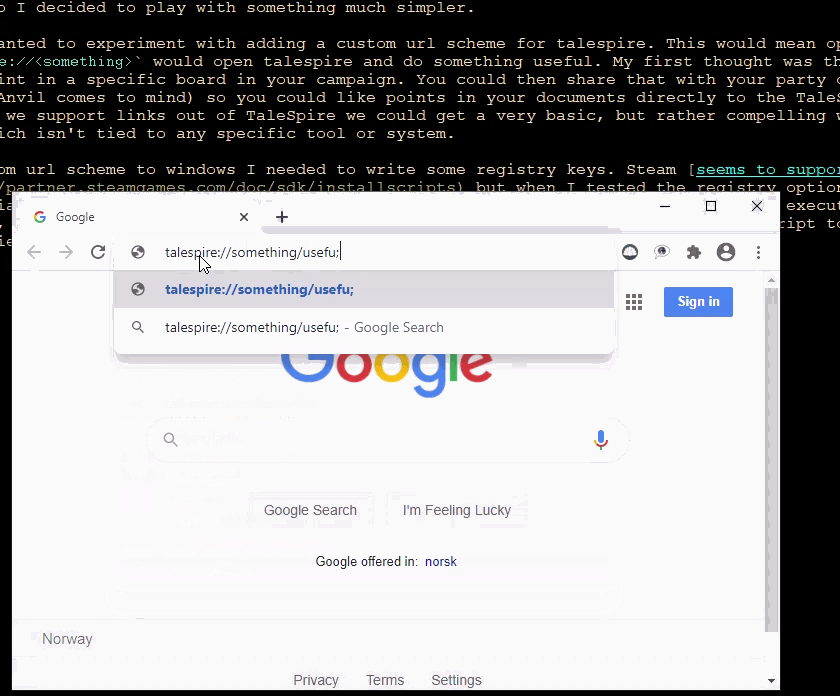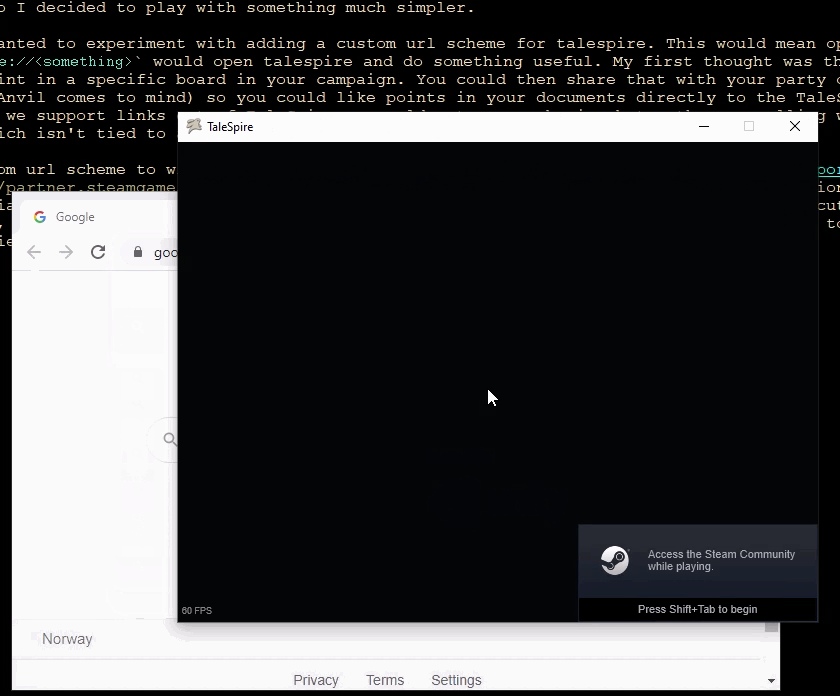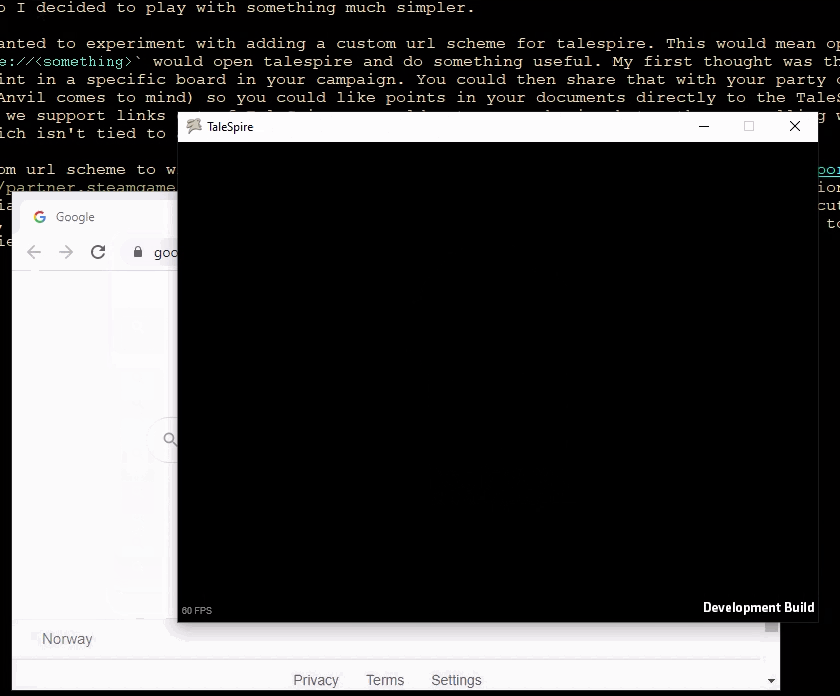
Note: I have chopped out a bit of the middle of this video as loading takes much longer in a developer build, and it’s boring to watch
I’m not going to do any more work on this for now, as there are many more important things to do, but this was a nice change of pace for a few hours.
That’s all for now.
Peace.
TaleSpire Dev Log 233

Internally we have been calling this bug “popcorn dice”, and it’s been driving me crazy for a while.
As we have our own wrapper around Unity’s new physics engine, I had assumed that I was just ‘driving’ it incorrectly. So today, I sat down and read how Unity’s ECS hooks into the physics. I had hoped the mistake was how I was loading in the physics-body data, or when reading it out after the physics step. Alas, no such luck.
I saw that they kept track of their fixed steps in a slightly different way than I did. It should have resulted in identical behavior, but just to be sure, I followed their example. Again no dice (har har).
I read that damn code forwards and backward and finally remembered that I had a test scene that had been surprisingly stable this whole time. It’s the one I showed in an update a few weeks back. It looked like this:

So what could this possibly have in common with the ECS tests I’d been doing, but that was also different from the main board scene. I suddenly got a hunch and couldn’t help but laugh when it proved to be correct.
The floor was too big.
YUP. So we’d been lazy and just made the board 6000x6000 units in size a looooong time ago and promptly forgot about it. The classic physics engine (bless its soul) had been doing a great job, and so we’d never seen the issue. However, with the new system, if you have mesh colliders interacting with a single box collider more than ~2000 units across, it gets very unstable and starts popcorning like we see above.
This find is a huge relief. TaleSpire obviously relies on the dice behavior being reliable and, if it were a problem with the engine itself, I’d have no idea of how to fix it. This should be trivial. We can make a smaller collider and just teleport it around where we need it.
Alright, that’s a great place to end the day.
I’ll seeya all tomorrow with something else!
TaleSpire Dev Log 232
Updates from the land of code.
The batching/rendering code has reached where we need it to for the Early Access. We see a three times speedup on some of our stress tests, and while there are very clear ways to get more, this endeavor has already left us two months behind schedule, so we need to press on into other features. That said, it is lovely to see all this work pay off, and I’m very excited by what we can do to get the rest of the perf that is still on the table.
During this, I hit one very annoying bug. It seems that Unity does not handle writing into IndirectArguments buffers properly on all GPUs[0]. The GPU-frustum-culling system I wrote recently worked great on my home PC but failed silently and strangely on my laptop. I ended up using a more naive approach and having the culling compute shaders pushing values into an append-buffer and using the CopyCount method to transfer the final length to the IndirectArguments buffer afterward. This still kept things on the GPU but significantly increased the number of compute shader dispatches and buffers required to work. The good news is that it does open up some opportunities for removing some indirection in the vertex shaders, which should give some performance wins later. I think I should also be able to make a system on top of this that can reduce the number of final draw calls, but we’ll see how that goes.
Ree and I did some digging into the physics instabilities we have been seeing. Along with some simple mistakes, we remembered that the Unity.Physics API allows you to swap out the engine used behind the scenes, and that Havok has such a package. We had heard rumors that it was just plug-and-play, but when is programming ever that simple?
It was that simple. To be honest, I was floored. I changed maybe ten lines of code, and TaleSpire was using Havok. We saw that, while the stability was a little better, we were getting uncannily similar issues to using Unity’s DotsPhysics. This made us confident that the problem was how my code is driving the physics rather than the instability coming from the engine.
It should be noted that DotsPhysics was significantly faster than Havok in the stress test we threw at it. TaleSpire doesn’t have many dynamic objects, but we have hundreds of thousands of small static objects. DotsPhysics seems to be heading a very compelling direction, and I think it will carve out a very successful niche for itself.
We then upgraded to the latest version of Unity, which, in turn, allowed us to move to the latest builds of various packages, including physics. The improvements in DotsPhysics was again, notable. It seems that our strange blend of using old and new systems in Unity has paid off well as we haven’t yet run into any painful bugs on this new build. Unless anything major happens to make us have to downgrade, 2020.2 will be the version of Unity we will ship TaleSpire using.
We also merged master into the branch with all the new tech. This includes the props system. To let prop development be done in parallel, Ree has been serializing the props separately from the tile data. Now that props are shaping up well, we can see what data is needed and so we are in a good place to bring props into the same system as tiles. This will let sync, undo/redo, and all the other normal stuff work with props too.
A short time back, discussions with the community on how line-of-sight should work led me to re-think how that system should be implemented. Yesterday, Ree helped me prototype one possible version of this. It relied on us not using the BatchRendererGroup in ShadowsOnly mode but instead discarding fragments in passes where we didn’t want to write to depth. It worked well in small scenes, but we took a significant FPS hit in our stress-test. I’m happy that we found this out very quickly and can now start the version that is a little more work but will not put additional costs on unrelated systems. That version will require us to dispatch the DrawMeshInstanced calls to render the scene to individual faces of the cubemap. We will use jobs to handle the selection & per-face culling of the tiles for these draw-calls.
Aside from this, I’ve continued work on the character controller. It’s not there yet, but we are relatively confident we can fix up the remaining issues, so it’s currently a lower priority.
That wraps up everything for last Wednesday to now. My next immediate task is to hunt down what I’m doing wrong in Physics as currently, it’s the biggest thing that stops us from play-testing this branch.
Hope you folks are doing good. Peace.
[0] It could be that the IndirectArguments issue was a graphics API limitation rather than a Unity one. I’d need to do more reading to find out.
TaleSpire Dev Log 231
Hey folks, I was meant to write this in the morning, but code is distracting :P
Yesterday I worked on dice physics. I had been concerned by the behavior of dice and wanted to find a good path forward.
To be able to see what was going on, I made this test scene. I can reset the dice by clicking the reset ‘button.’

This is one place where Unity absolutely excels. Being able to knock up tests and tooling in minutes so often can help you make headway on otherwise stubborn issues.
There are a few points that I find interesting:
DotsPhysics and ClassicPhysics do not line up in behavior. This is really important as this means that I shouldn’t expect my conversion routines to give the same results as classic as mine are directly based on the ones built into DotsPhysics.
The BouncePhysics wrapper around DotsPhysics lines up with the behavior of DotsPhysics. In that, the way they bounce and come to rest is similar. This lends support to the point above and gives some evidence that the conversion is ok.
DotsPhysics falls faster. This is because they don’t handle time properly, so faster framerate means faster simulation.
Mine falls at the same speed as ClassicPhysics. This is very important. It suggests my fixed-timestep code and use of Unity’s simulations values (like gravity) are in the right ballpark.
Once I realized that DotsPhysics doesn’t give the same bounce, drag, etc, for the same input values, I felt comfortable playing with values to find something that felt right. This clip is not final behavior but shows how a couple of minutes of tweaking can help.
Afterward, I set up some ramps and D12s, so we had a decent place to start testing when we sit down to dial this in for real.
I also saw that my interpolation code was incorrect. I found some issues, but I was struggling to match all of Unity’s behavior. I then noticed that we don’t use interpolation in the current build and so this stopped being a priority. However, it still took me a couple of hours to quit playing with it. It’s so tempting to keep going when you know you have the math right, and it’s the surrounding plumbing that is the issue.
Anyhoo that was that. Today I’ve been working on the character controller again, results are promising, but I’ll leave that until tomorrow.
Goodnight
TaleSpire Dev Log 230
With lights under control, I’ve turned my evil eye back to physics. Since I replaced the physics engine, gm-blocks and hide-volumes have not been working. This was expected, but it was time to fix them.
For sanity, I’m going to call Unity’s old physics engine ClassicPhysics, their new one DotsPhysics, and our wrapper BouncePhysics.
Hide volumes make use of the fact that, in ClassicPhysics, we could resize colliders on the fly. We needed something similar in our new system. First up was a different problem, however. When we convert Unity’s colliders to the form required by DotsPhysics, we remove the components. This means there isn’t an obvious place for the programmer to set the values. This meant BouncePhysics needed its own version of these components.
I knocked together a Sphere, Cylinder, Capsule, and Box collider components. I modified the BouncePhysicsBody to walk the hierarchy, converting the ClassicPhysics components to their BouncePhysics equivalent, and registering all these new colliders.
During this, I noticed some issues in how my code handled baking of scale when the collider is subject to multiple transformations. This sucked for a good few hours, but I was able to find code that showed how to do it properly, and I got it fixed.
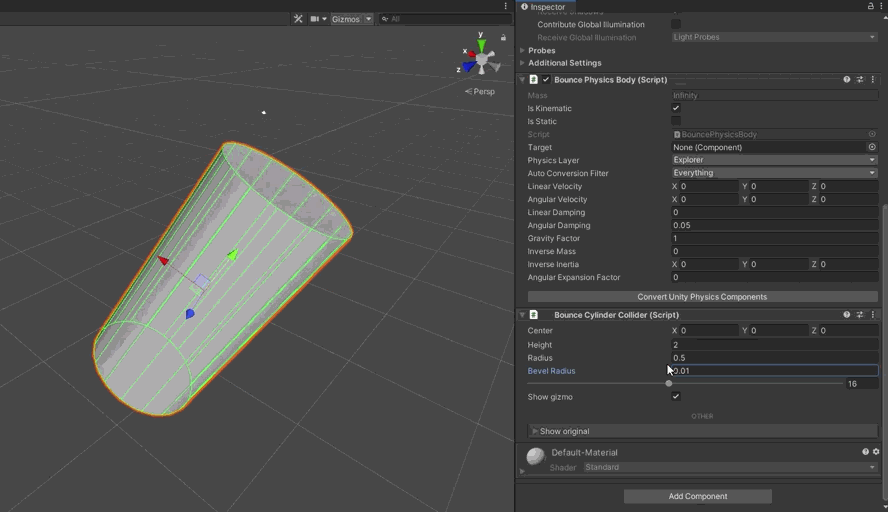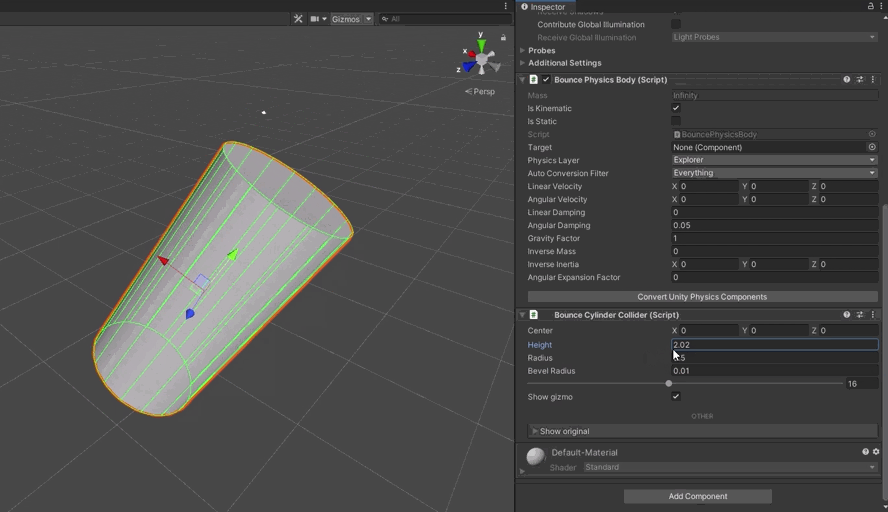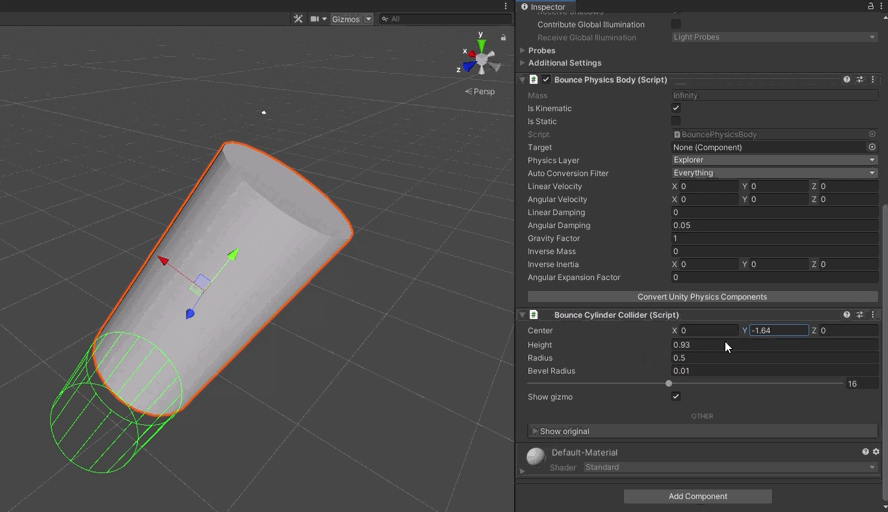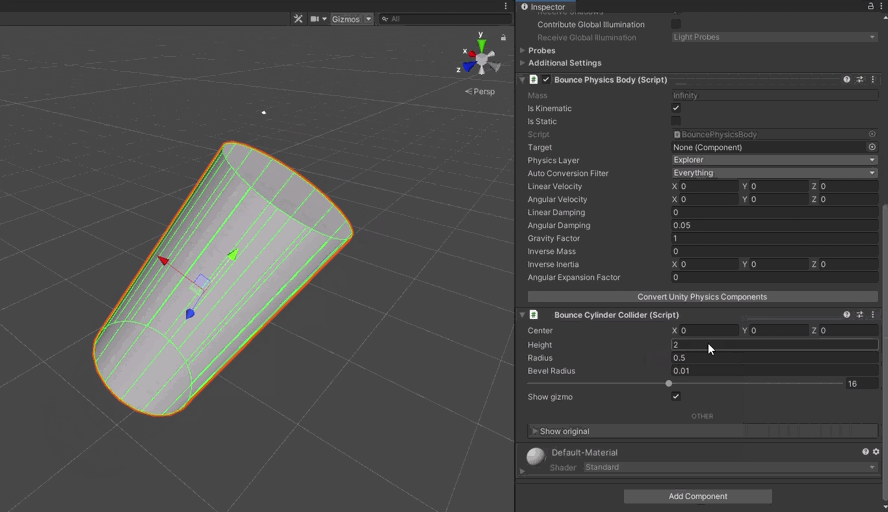
With that done, I was able to hook up the hide volumes and get them working again \o/
Next, gm-blocks. There I found an interesting bug when deselecting them. First, the gm-block would be destroyed, and as that happened, it would unregister itself from BouncePhysics. The issue arose because, in DotsPhysics, you reset and pass all the RigidBodys every frame. This means that although I had unregistered the object from BouncePhysics, the RigidBody was still in the DotsPhysics collision world. I can’t just remove that one body (the only option is Reset, which clears everything). Instead, I now set a flag inside the RigidBody to state that it is unregistered and then modified the collision queries to check for this flag when collecting results. This all takes place after the updates to motion have been calculated, so there is no risk of something bouncing off this unregistered body before the next frame, and by then, it will have been cleaned up.
Of course, this check (which is essentially a comparison of a ulong) is not free. I will probably have the system only use those new collectors on frames where something has been unregistered. Luckily in TaleSpire, we don’t have much churn in the physics objects.
During this, it made sense to clean up some of the physics code in general. Until now, I had made the class that holds the board data responsible for the physics ‘world’. This wasn’t ideal, and the physics related code was very out of place. I decided to centralize it in the BouncePhysics classes. This does mean that, for now, we only allow only one board to be using physics at a time (which could matter when changing boards), but the trade-off was that I could make the API much more like ClassicPhysics. The API design is important because, as soon as I merge this branch, Ree needs to be able to get up to speed quickly. The more familiar it is, the better.
In amongst this, there was the usual smattering of bugs, confusion, and other things that slow one down. But overall, it’s felt good to have some forward momentum.
Next, I really need to find out why dice in BouncePhysics are not behaving like they did in ClassicPhysics. It could be an issue in the conversion routines or, more likely, mistakes in the code than manages fixed-timestep and interpolation. I’ll set up some test scenes where I can compare everything side-by-side, and we’ll see what we can find out.
Alright, that’s all from me for now. Seeya later