From the Burrow
TaleSpire Dev Log 207
Good evening all. For the last few days, I’ve been struggling with the graph UI and how I want to serialize the scripts. The TLDR is that I’m making progress again, but I’m about two days behind where I wanted to be.
One afternoon was spent trying to understand some odd behavior I was seeing when dragging assets onto nodes in the spaghet graph. I was able to make a decent reproduction of the issue, and the library author was incredibly quick at fixing it.
The graphs themselves are usually stored as ScriptableObjects in Unity. This is ideal for the state-machine scripts, which I want to share between tiles, however, it did not fit my design for the realtime-scripts, which are closely tied to the assets the manipulate. I struggled with the serialization logic here for about a day, and I’m not satisfied with it yet. Regardless I need to make progress with TaleSpire, so I need to crack on.
Today I’ve started work on the UI, which lets you pick the script for a tile and then assign a realtime-script to each state. It’s looking something like this right now.
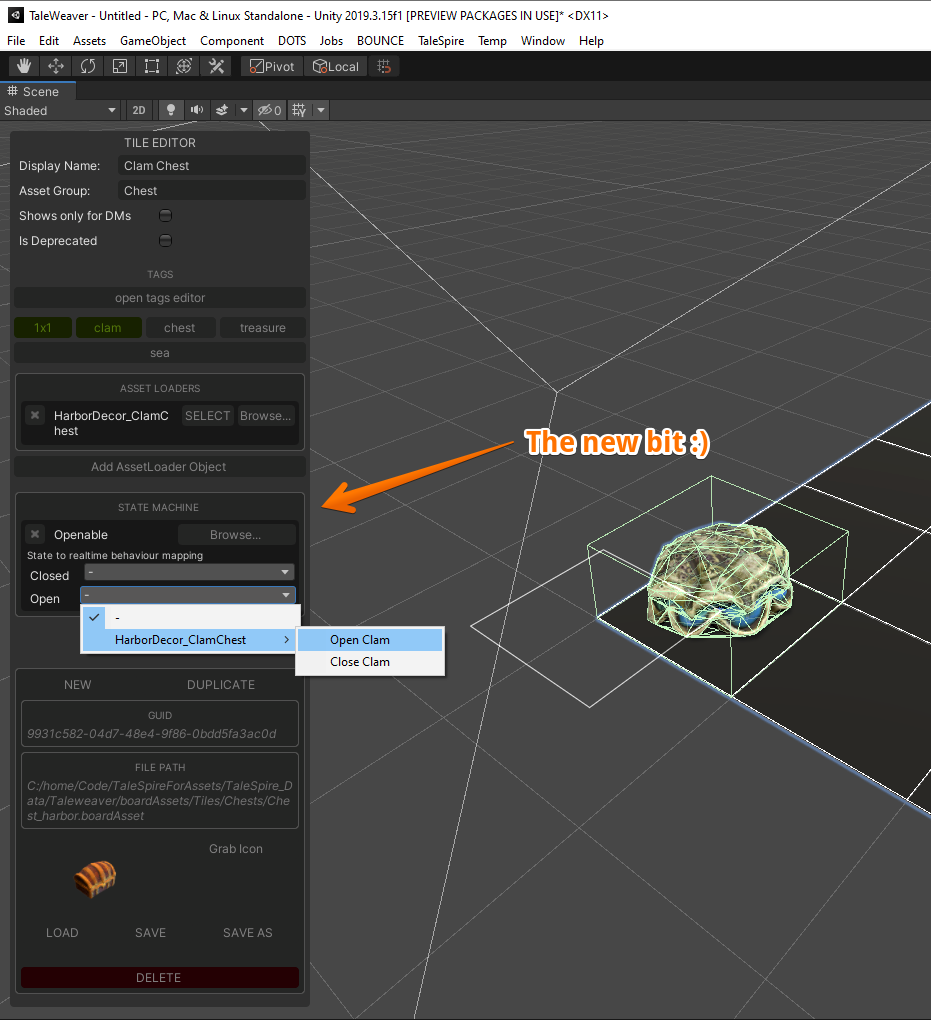
Basic, but enough to make progress.
Once I have this information serializing, I will finally start writing the new asset format. That will let me switch back to TaleSpire and rewrite the asset database. It should then be faster and compatible with the job system, which opens up some performance improvement possibilities in the future. However, we won’t be chasing those particular performance improvements, as we need to write the new animation system first.
Back with more real soon.
TaleSpire Dev Log 206
Hey folks. I’ve now ported enough of my old Spaghet experiments to the new node graph that I can compile code again.
Here is a useless script:
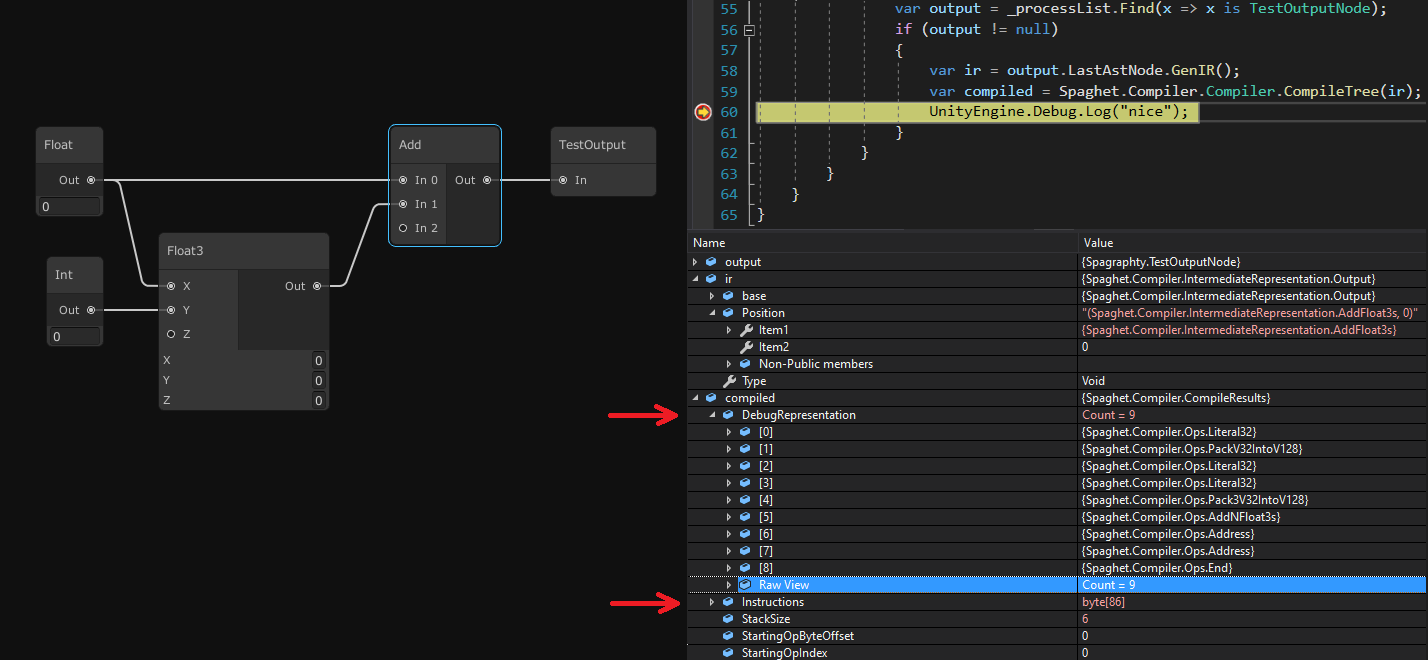
On the left, we have some nodes (the node visuals are still WIP), and on the right Visual Studio’s debugger showing the result from the compiler. I’ve indicated the debug representation as it’s a bit easier to see the generated operations. The actual result is just a byte array, so I haven’t bothered to expand it (spoiler, it’s full of bytes).
I’ve also added some code to check for type errors and to report loops in the graph. This feels like the bare minimum requirements to be able to code in a sane way.
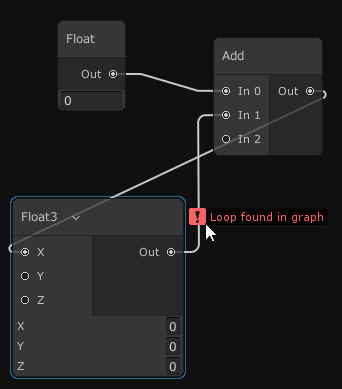
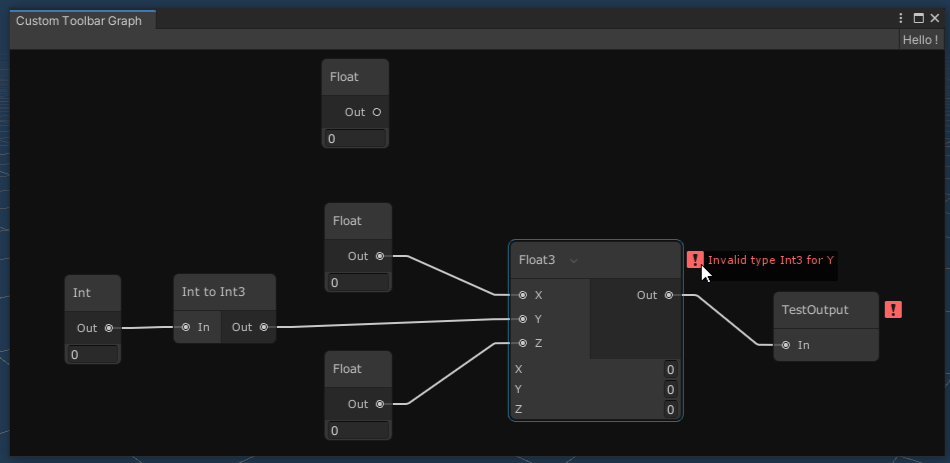
Tomorrow I’ll look into the output nodes. First, I’ll add ones for setting an asset’s transform and another for driving an animation. Both will let you drag the assets in questions straight from the Unity hierarchy so that it fits the standard Unity workflow.
That’s all for now. Seeya tomorrow.
TaleSpire Dev Log 205
Good evening folks,
It’s been another decent couple of days convincing computers to do things.
Most of my time this week has been spent getting to grips with NodeProcessorGraph, which so far I’m loving. The main developer has been super responsive, making me even happier about sticking with this library.
I didn’t write up yesterday as it was one of those days that you know you need to learn a system very quickly and so you just slam your brain against it all day until you realize why things are the way they are :) A necessary endeavor, but not one that leaves you much in the mood for writing.
Today, however, I’ve been knocking together very simple nodes for the state-machine scripts that tiles can use. The closest thing I have to a visual is this:
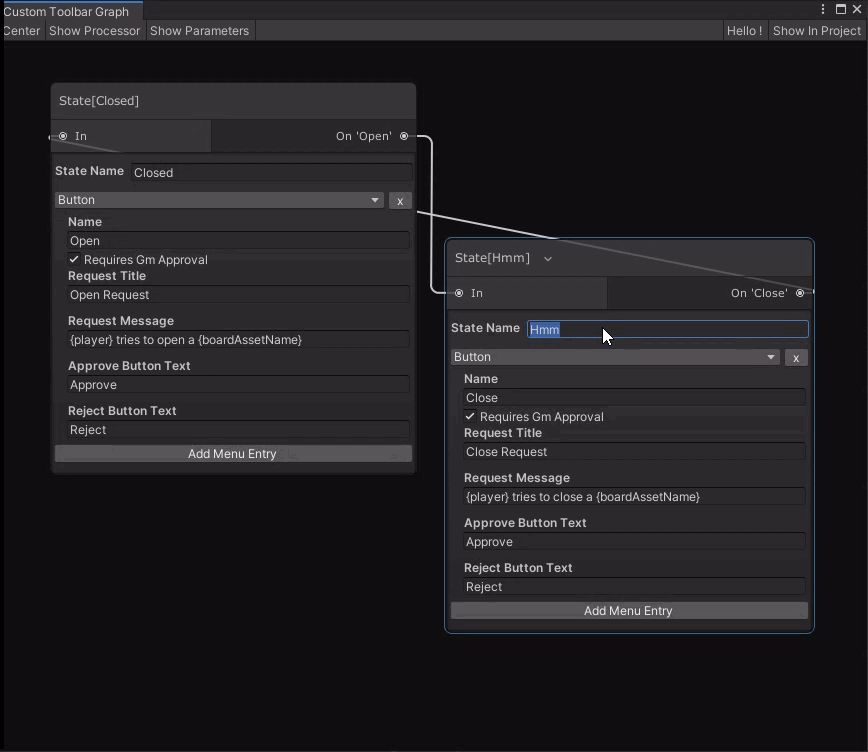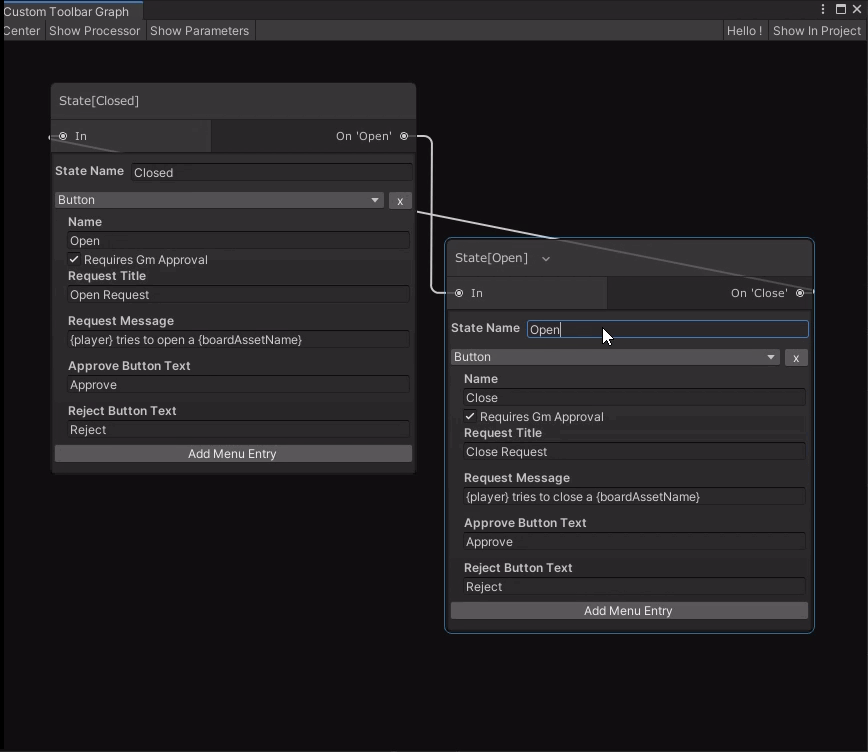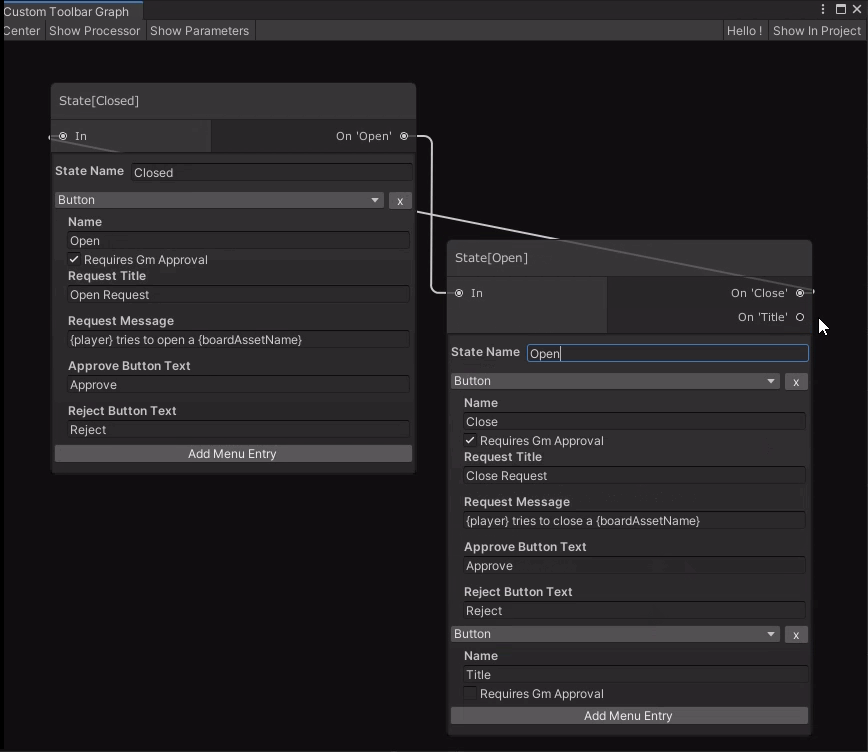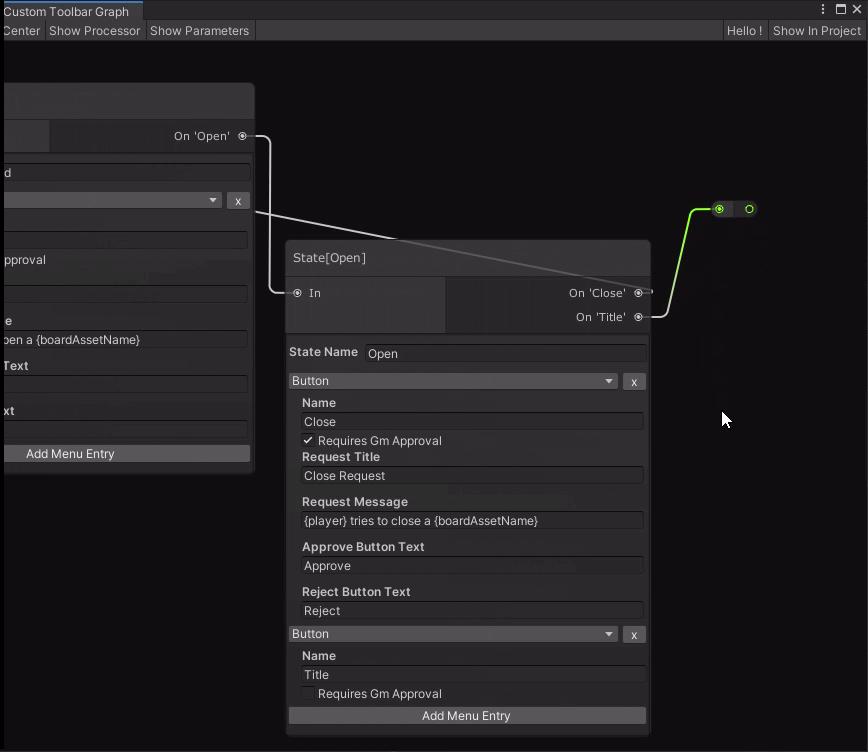
This graph only expresses the state of the tile (or prop in future), and what actions transition between them. To do something visual, you will need the realtime-scripts.
A quick aside. In TaleSpire, tiles and props are things called BoardAssets. BoardAssets are collections of Assets, which act as a single unit. The BoardAsset holds the information of each Asset required and it’s local position/rotation/etc within the unit (along with a bunch of other BoardAsset specific data). The cool thing is that a BoardAsset may be made of Assets from totally different asset-packs. This means you will be able to remix the Assets that people like us provide.
By separating the two, we can share the state machine among many tiles easily and then, per-tile, choose the visual behavior that occurs during each state by mapping states to the realtime-scripts which live on the Assets.
Codesharing of realtime-scripts will be done through making functions. These will be sharable as strings so that we can all do the same kind of thing that we do with slabs today. That’s the idea at least :P I’ll be writing that bit soon.
Tomorrow will be focussed on the realtime-scripts. I want to see if I can get the compiler for those working again in the next few days. When that is done, I’ll see what the next logical step is. It’ll probably be writing the state-machine compiler, which will be pretty straightforward.
Ok, enough rambling for now.
Seeya tomorrow!
TaleSpire Dev Log 204
On Friday, I got the code written to extract Unity’s animation data and pack it into the AssetBundle file in the way we wanted. This data will be utilized by the upcoming animation system to be used by tiles and props.
Before we get there, and as mentioned in the last dev-log, we need to update the boardAsset format that TaleSpire uses.
For the format rewrite, the first thing to review was what we were going to store. This quickly led me to look at the scripting system again. I tried to write a high level of some of the stuff I’m looking at, but it gets rather vague, so I’ll just talk about something concrete instead.
I am 80% sure I want tile/prop animation to be driven by the scripting system (Rather than tile/prop I’m just gonna say tile from now on for brevity). I already intended to have two kinds of scripts for tiles, state-machine scripts, and realtime-scripts.
The state-machine scripts are driven by user interaction and are synchronized across the network. Realtime scripts run every frame and are unsynchronized. I’ve imagined the realtime scripts to be like shaders in that they’ll run fast, in parallel, and don’t hold their own state frame-to-frame.
I’m looking into being able to specify a realtime script as the behavior for a given state-machine state. So if you are in a given state, the game runs the associated realtime script. The realtime script would set things such as the position/rotation/scale of parts of the tile, parameters of lights, and be able to drive animations.
The last item in that list of examples is the interesting one for today. If I can implement animation via the scripts, it would allow me to flesh out that part of the codebase now, and then look at custom animation code as a performance optimization for later.
Because of all this, I’ve started looking back into Unity’s support for node-graphs, as Spaghet is meant to be a visual scripting language. In the last 11 months, it seems like NodeGraphProcessor has come a long way. I like a lot of what I see there, and so tomorrow I’m going to start digging into how to use it to implement the state-machine scripts.
Once again, not making hard claims about the delivery of specific features is paying off as, if required, I’ll be able to reorder a bunch of work without causing issues. I’m sometimes sorry that this means we can’t give you as many concrete dates as would otherwise be ideal; however, the ability to roll with the punches is really helpful.
Hope you folks have had a good weekend, more news as it happens :)
Seeya
TaleSpire Dev Log 203
Phew, this one took a while to get out.
The art team is hard at work, prepping the next big asset patch. Should be another fun one!
On Wednesday, I had some boring life stuff to sort out, so I wasn’t working that day.
On Thursday, Jonny and I had a catchup meeting and roughed out a plan for the animation system for tiles & props. To get working on this, I first need to extract the animation data into a format we can work with from the job system. It took a while to realize that, if you load a prefab from a Unity AssetBundle, the full curve information is no longer available. This is ok, as in TaleWeaver we work with the original prefab files, but it was still a slow journey learning the ins and outs of this part of Unity.
With that worked out, I wrote the first pass on the extractor. This was looking ok, but the standard asset serializer only supports classes, and I want the data in a job-friendly format. Now, Unity does have a serialization scheme they use inside their ECS when serializing Entities to their Scene format. They call these BlobAssets. These are fast, immutable, and pretty much ideal. However, they are not compatible with the AssetBundle serializer we mentioned early. To get around this, I have written an adapter that makes this possible. That took a long time, and I still would like to add a bit more data validation. However, I’m happy that I can now write the data in the way I want.
The next task is to rewrite the animation extraction code using this new store. I’ve been going slow here as I need to be able to uniquely a given resource (e.g. an animation clip) inside an asset, and I want to make sure that these are stable to the kinds of changes that are made when developing a tile or prop.
With that done, I’ll be writing a new system for packing the board asset data. I’ve looked at this several times when I was investigating CaptnProto and FlatBuffers, now I have a good workflow with BlobAssets I’m going to use that instead. The current JSON format will continue being used by TaleWeaver to allow the art team to iterate on that format as required; however, when we export an asset pack, we will use the new system instead.
And once all that is finally done, I can start writing the animation system :)
I have also been researching Unity’s new Physics engine again and am slowly designing how we are going to interface with that. It’s going well, but I wanted to get animations working first as some assets (like doors) move colliders using animations.
Alright, until next time.
Peace
TaleSpire Dev Log 202
Allo folks,
Some good progress today. The new batcher seems to be laying out tiles correctly now, so I can kind of build again. I haven’t hooked into the new physics engine so I can only build on the build plane currently.
What was nice was I could do some quick performance tests to see what ballpark we are in. I was able to spawn 10000 tiles in one frame without dropping below 60fps which is very promising. There are things the code doesn’t have to deal with yet, such as animations and physics. However I’m feeling confident that we’ll be able to get a large speed up in tile spawning over what we have in the beta today.
Here is a very wip, potentially misleading clip :P
Next, I’ll be adding jobs to build the per-zone physics data. It won’t be the code that ships, but like this, it will give me some insights into how the final system might behave.
Seeya folks!
TaleSpire Dev Log 201
Hey again folks.
Saturday’s work went well. I spent most of it reviewing the current code and double-checking the tile spawning implementation. We’ve put out a bunch of fixes since the beta release, and so I wanted to be sure the code still matched my design notes from earlier in the development. Luckily it did, and working through all the code paths gave me a much clearer idea of what needed doing first.
It looks like I can get something working without having to handle uncommitted changes[0] at the same time. This means the response time of build actions will be unacceptable (as it requires a round trip to the session host), but it will let me tackle the tooling and copy/paste before having to deal with that additional complexity.
That’s all for now.
Seeya
[0] In TaleSpire, in order to keep network traffic low enough to be manageable, we send ‘operations’ over the network. These are instructions telling the game what to change on each person’s copy of the board. For this to work, all operations must be applied in the correct order. However, games feel bad unless changes happen as soon as you request them, so we keep track of changes that have not been given their final order yet. These are what we call ‘uncommitted’ changes.
TaleSpire Dev Log 200
Heya folks,
On Thursday, I continued work on the batching code. I got a first approximation written[0], but upon trying to hook it into the existing setup, I noticed that disabling the current system is not trivial. In fact, I had a choice between working a bunch for a test that wouldn’t teach me much[1] or just plowing into the real work of replacing the current system. I chose the latter.
This means that the goal I set for myself of “something rendering by the weekend” was not feasible, and I shouldn’t push myself unnecessarily. The task of replacing the system touches a lot of code and requires a different mental approach.
So instead of fretting Friday, I decided I’d take it off and just work Saturday instead. One of the blessings of working for yourself :)
Because of that, I have no news for today. I also expect that the updates from me for the next week will be variations of “Replacing part X of the old tile system”. However I will try to keep the posts coming in case anything interesting crops up.
Until then, Bye!
[0] Approximation as it just positions all the parts of the tile at the tile’s origin. So it’ll be a mess but will show if things are working. I did this as the math requires a focus to make sure I don’t screw it up and should be taken slowly.
[1] I have already made experiments to learn how the BatchRendererGroup behaves, and the process of writing the batching code had given me a good deal of the context I had hoped to get from the exercise.
TaleSpire Dev Log 199
It’s the summer holidays over here, so we’ll see a little less of Ree this week as he takes some well-earned breaks. However, you still have to put up with me :)
Today I’ve been looking at writing the batching for the rendering as we move away from Unity’s GameObjects. It’s slow going, but I should have something running before the weekend. This version won’t have GPU-culling, but it will let me progress on the rest of the systems that need rewriting. Once this is working, Ree and I can work out the bare essentials we need for the animation system the tiles will use.
I also had another brief look into Unity’s new physics engine, and I’m reasonably confident we’ll be able to drive that efficiently. More on that another time.
Back tomorrow with more very incremental news :)
Seeya
TaleSpire Dev Log 198
Just signing off for the night, so not gonna write much.
I got the server patch tested and deployed. It will have no effect on the current TaleSpire release, but the next patch will start using it.
Right. Sleep is in order. Bye!