From the Burrow
TaleSpire Dev Log 398
Hey folks,
As expected, I’ve been working on the community-mod browser so we can have an in-game way to install Symbiotes when we make that feature public this week.
Here is a little clip of that in action:

I’m currently fixing smaller bugs and UX things, and that’s what I’m going to get back to now.
Have fun folks!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 396
Heya folks,
Work has continued integrating mod.io (so we can download Symbiotes from within TaleSpire), albeit sporadically, as I’ve had a bunch of folks visiting for midsummer (no ritual deaths involved, in case you wondered :p). The first few days of this week are gonna be a bit hectic for me, so we are shooting for Symbiotes to come out of Beta sometime next week (as in between the 3rd and 7th). I am always hesitant to give dates, as life has a habit of kicking off when I do. But hey, it’s been a while, and I’m ready to make that mistake again!
As you’ve probably seen, we’ve also been adding logs and gathering details on a bug that has given some folks sporadic difficulties logging in. We’ve narrowed it down to the request that fetches the game-environment details[0], but we are still working on minor fixes to address the cases that have been reported.
I hope you’ve had a good weekend.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] The game-env tells TaleSpire the address for the backend along with some extra stuff like maintenance times
TaleSpire Dev Log 395
Heya folks,
Currently, I’m looking into whether we can have mod.io support ready in time for Symbiotes leaving beta.
I know we won’t have the in-game upload done for that time. But what if we allow uploads on the website and downloads in-game? That still should be a much better experience for regular players.
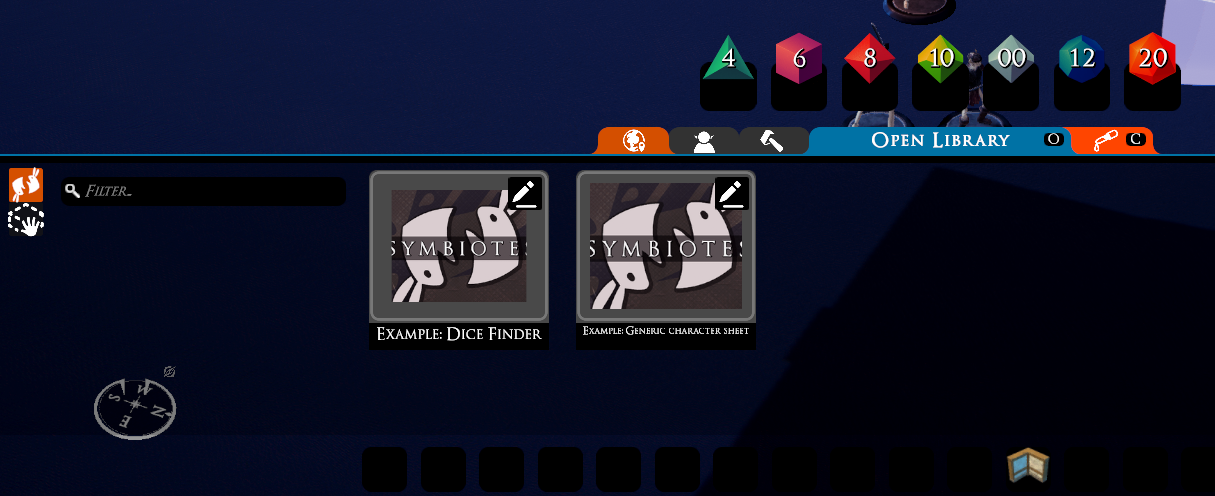
It took minimal effort to wire up the community-mod-browser to show the symbiotes, so now I need to handle the subscriptions to mods themselves.
mod.io does have its own mechanism for subscribing to mods, but we would prefer to handle that for a couple of reasons:
- It makes the code that handles mod.io more sharable with community-run repositories
- We can let you decide who knows what you subscribe to.
Number two feels important. With that TaleSpire can give you the option of whether to only store your mod list locally or on our servers so that it is automatically available wherever you are playing. If we can provide that choice, we would prefer to.
Right, that’s all from me for today. This week is pretty hectic as I have a bunch of guests over for midsummer, and I need to make sure I don’t just hide away coding :p
Have a great one folks. More coming soon!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 394
Heya folks,
Yesterday we were getting ready for the Symbiotes Beta. That involved writing up the release texts, recording gifs and all that jazz. We also tested the build and found a few more bugs that needed investigating, so that’s a pain, but better than we find it than you folks :P
The new backend made it through the first 24 hours just fine, which is a lovely first milestone. It’s great to start seeing the ebb and flow as people play across various timezones. That’s only going to get more useful over the weeks and months ahead.
That’s all for me for now. Back to the bugs!
Ciao!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 393
Heya folks, today is going very well so far.
You may have seen us talk about switching to our new backend infrastructure today. That went relatively smoothly, with only a few things to tweak for next time. I don’t want to steal @Borodust’s thunder by going into all the details of what he is doing, but I certainly sleep more easily these days seeing what is being built. We are on the road to a much more maintainable system, and the news insights we have into our servers mean we finally have some tools to start doing a decent job of seeing problems coming rather than reacting to everything. Of course, it’s still early days, but I’m naturally pumped about it.
Next up, Ree, myself, and Chairmander have all been merging in bits and pieces for Symbiotes. I’ve squashed the bugs I needed to handle before the beta, Ree merged in the UI, and Chairmander has the latest improvement to the docs (and supporting code) based on your feedback thus far.
I’ve got a candidate build running through our build system now, so I will go kick the tires on that and see how it goes.
Have a good one!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 392
Whoops :D
I released a little more than I expected to yesterday. Let’s talk about that.
I aimed to release some UI we could use during maintenance to make the process nicer for players. However, I forgot to disable a few unfinished things before shipping, so you folks got a little peek.
Big thanks to Ree, who cleaned up my mistakes as I was on the road when you alerted us to this issue.
The first thing that you might have seen is this:
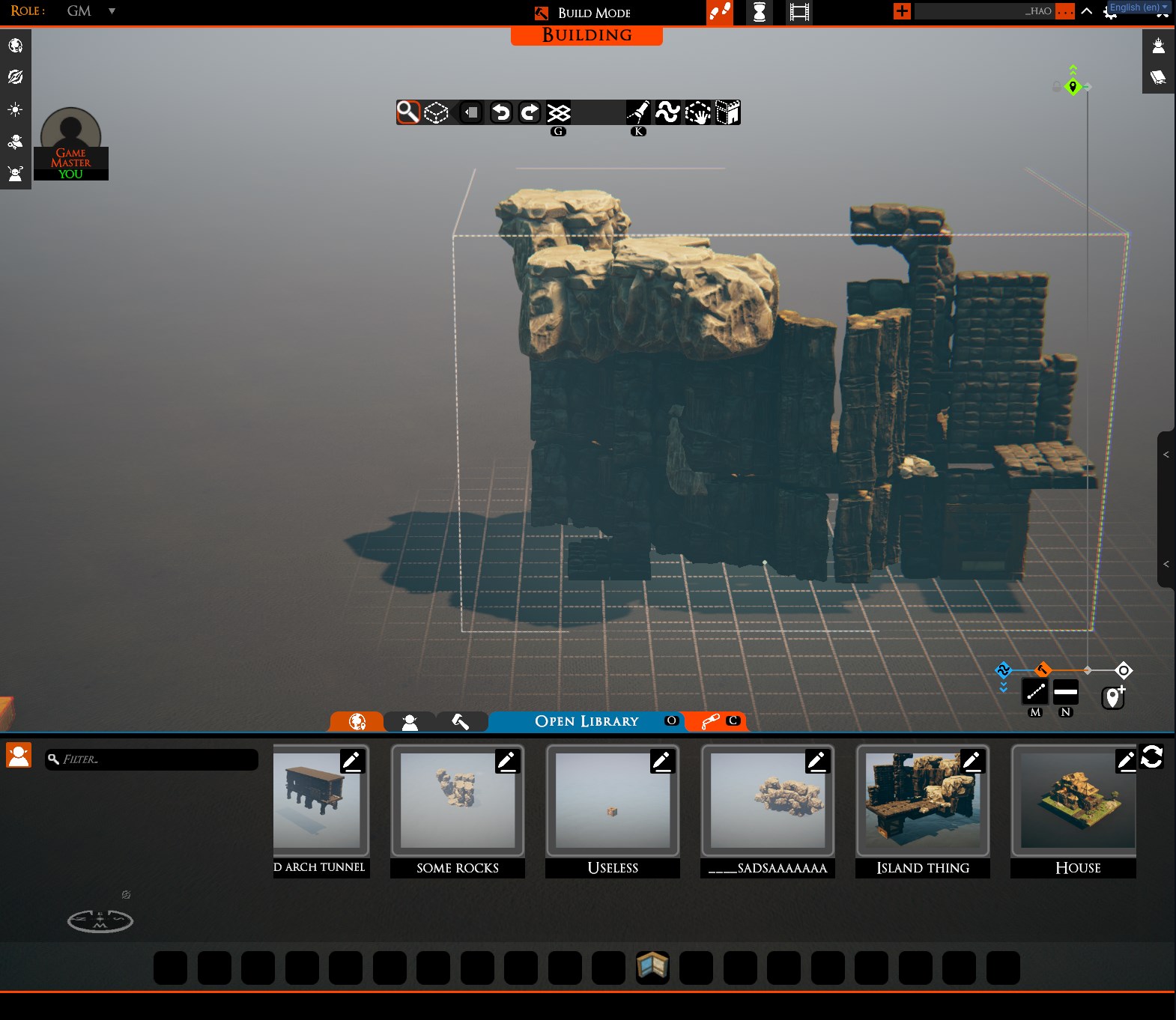
This is the first version of the ‘community mod browser.’ It’s where you’ll be able to find community-made slabs, symbiotes, etc, hosted on mod repositories. It’s currently only pulling from our mod.io repo, but that will be easy enough to expand once the core is complete.
As some of you saw, you can click on a slab to bring it immediately into the game, making the flow of building with community creations even smoother.
Aside from some more testing and adding separate categories for symbiotes and boards, this part is relatively close to shipping. The reason we haven’t is due to the next thing we accidentally shipped.
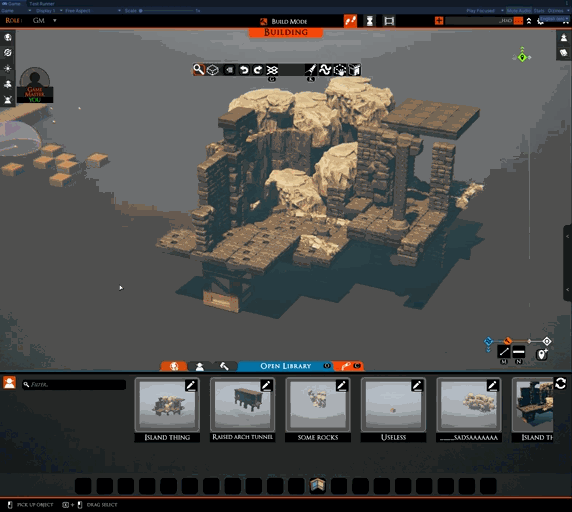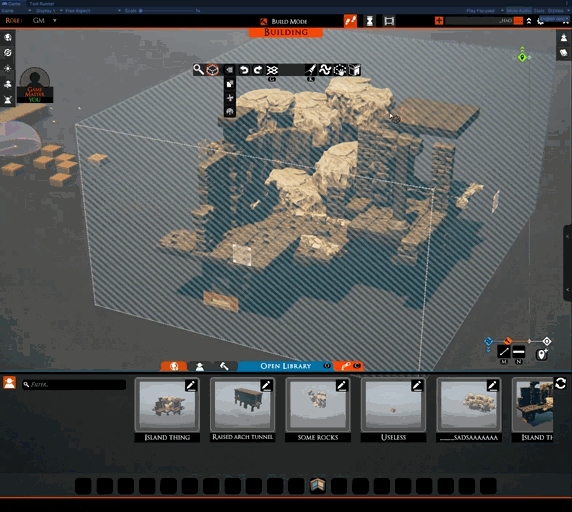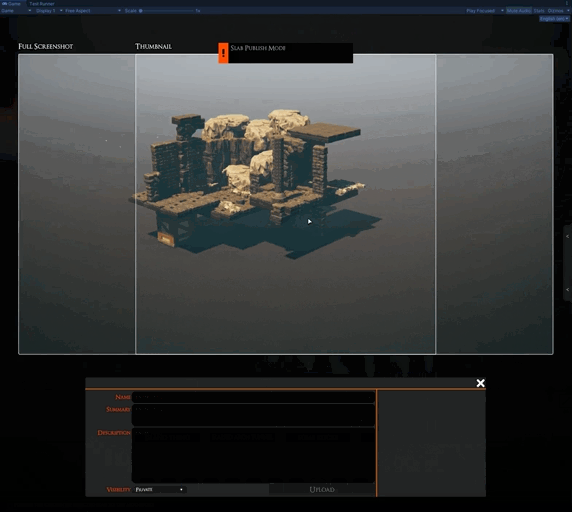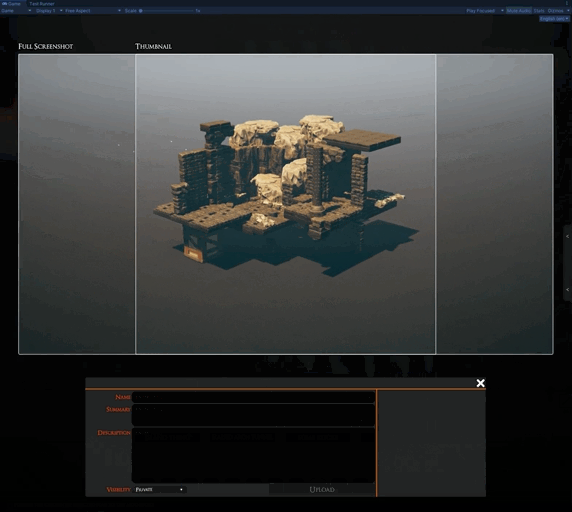
This is the unfinished UI for sharing slabs from inside TaleSpire. Very soon, it will be as easy as selecting your creation and hitting a few buttons to share your slabs with the world. We are starting with uploading to mod.io but then want to expand to uploading to other mod repositories
That said, it’s clear why this hasn’t shipped yet. The camera controls are borked, the UI is unfinished, and there is no way to set up your mod.io account.
There is one part that works, however. You’ll notice that, when entering the upload UI, TaleSpire isolates just the selection. This is very handy for seeing what is selected, which can be tricky in busy scenes and can help avoid sharing more than you mean to.
This “isolation mode” is a helpful tool in its own right, so we have made it available in the building tools menu.
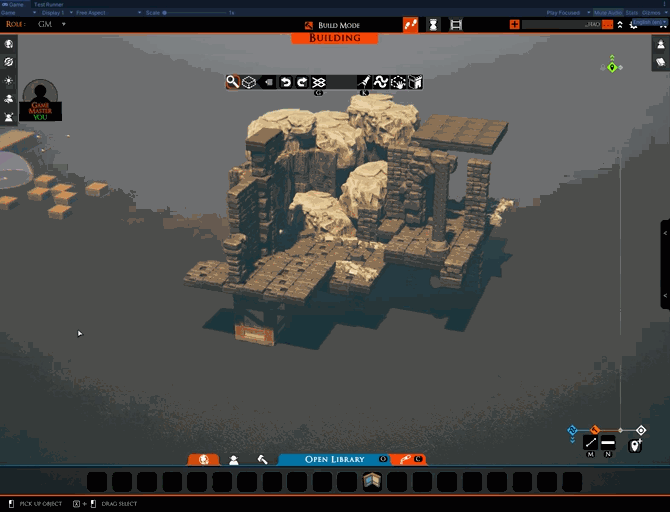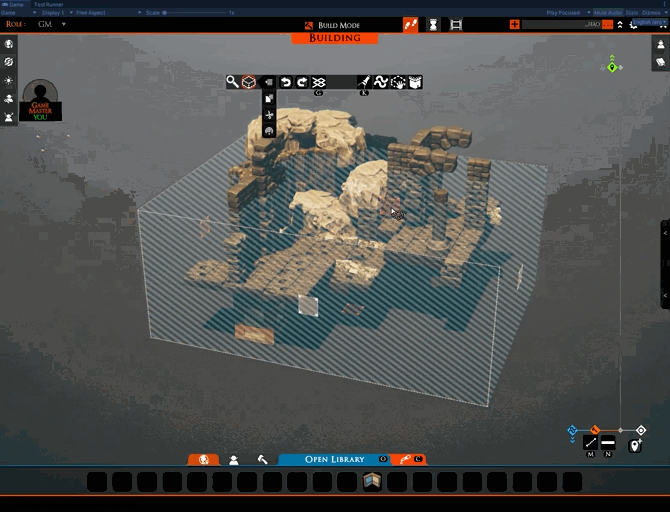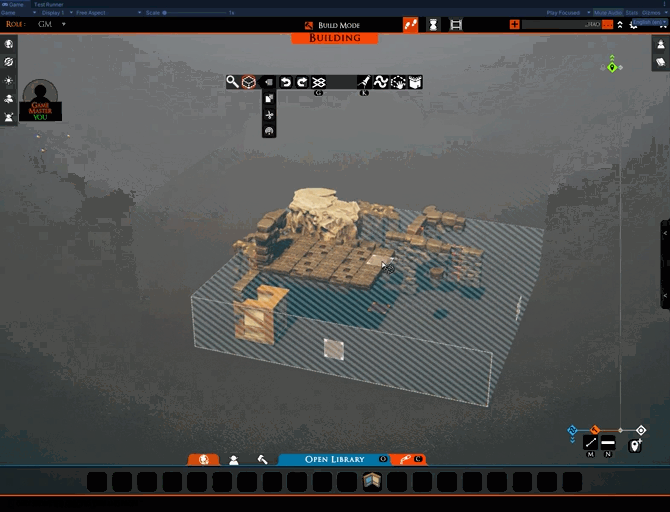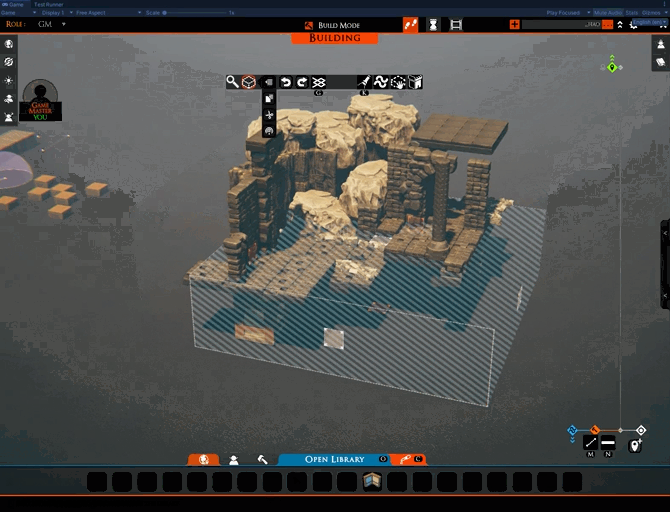
Also, this feature already works despite being an accidental release, so we’ve left it in. At least that way, you folks get something useful out of my screw-ups!
Today I’m back squashing bugs in Symbiotes. I have an annoying exception occurring when switching to and from dev-mode.
Catch ya in the next dev log.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 391
Morning all!
I waited until today to put out the maintenance ui update as I wanted to do a bit more testing. I’m prepping that release right now, and it should be out within the hour.
We are also scheduling downtime on Thursday so we can move to our new server infrastructure. We are super excited about this as it will give us far more stability, insight into our systems, and new ways to scale.
You can find the maintenance time in your timezone at this link:
I’ve got to rush off now to work on the release, but here is a little clip of the maintenance UI before I go.
Ciao!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 390 - Symbiotes Documentation
Heya folks,
Part of getting ready for the first Symbiotes release is finalizing the documentation. Or rather, I should “was” as that is now done!
We know that a bunch of you in the community are developers who might be interested in peeking at this even before the feature is available, so we have put the docs and examples public early.
You can find the documentation at https://symbiote-docs.talespire.com/ and the examples are at https://github.com/Bouncyrock/symbiotes-examples
The documentation is also a valid Symbiote. That can be found here: https://github.com/Bouncyrock/symbiotes-docs
We have intentionally not added calls that modify board or campaign state in this first API version. That allowed us to avoid the impact of such changes on the backend. However, we will be significantly expanding the API into those areas in the future.
Major props go to @Chairmander, who has been driving the entire documentation process. Left to my own devices, the first version would have been much more bare-bones!
You should also see a little patch going out in the next 12 hours. This will be the patch that adds UI that we will use during future maintenance periods.
Well, that’s all for today!
Ciao
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 389
Morning all!
It’s Saturday, so this will just be a short log.
Yesterday I completed the implementation of the maintenance UI. It needs a little more testing, but I expect to be shipping that Monday. This won’t affect you yet, but we’ll get to use it during the next server upgrade, which is also coming very soon. Pavel has done fantastic work taking the very basic thing I had built and putting us on the road to serious infrastructure that will stand up to the tests ahead.
I also got to chat with some lovely folks in the broader ttrpg community both about Symbiotes and what they were up to. it’s always a blast to see how much is happening out there.
Alright, time to get some work done in the garden.
Ciao!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 388
‘Allo folks.
Yesterday I continued working on the update UI and some details with Symbiotes that drag us that last little distance towards release.
Symbiotes has to be the most feature with the most creep we’ve ever had. It started with “let’s just get a web-view in here,” evolved to “let’s add a basic API in here so creators can interact with TS” to a place where we were really drilling down into the details of the programmer’s experience, writing extensive documentation, and making something we can truly support and grow over the years[0].
I’m much happier with this result than I would have been with the original plan, but I regret how much time it took. However, we are wrapping up the last few outstanding things:
- Finishing the v1 UI
- Prodding the legal folks to get the TOS updated.
- Fixing little bugs and annoyances as testing reveals them
We have also been chatting and working with other creators to be sure that the first version is helpful for real projects. I’ll talk more about that another day.
Anyhoo, back to what I was actually doing.
First off, I expanded the manifest to support icons for the symbiotes. The manifest is a file you write to tell TaleSpire about the symbiote, including what features to inject.
Here is a sample manifest:
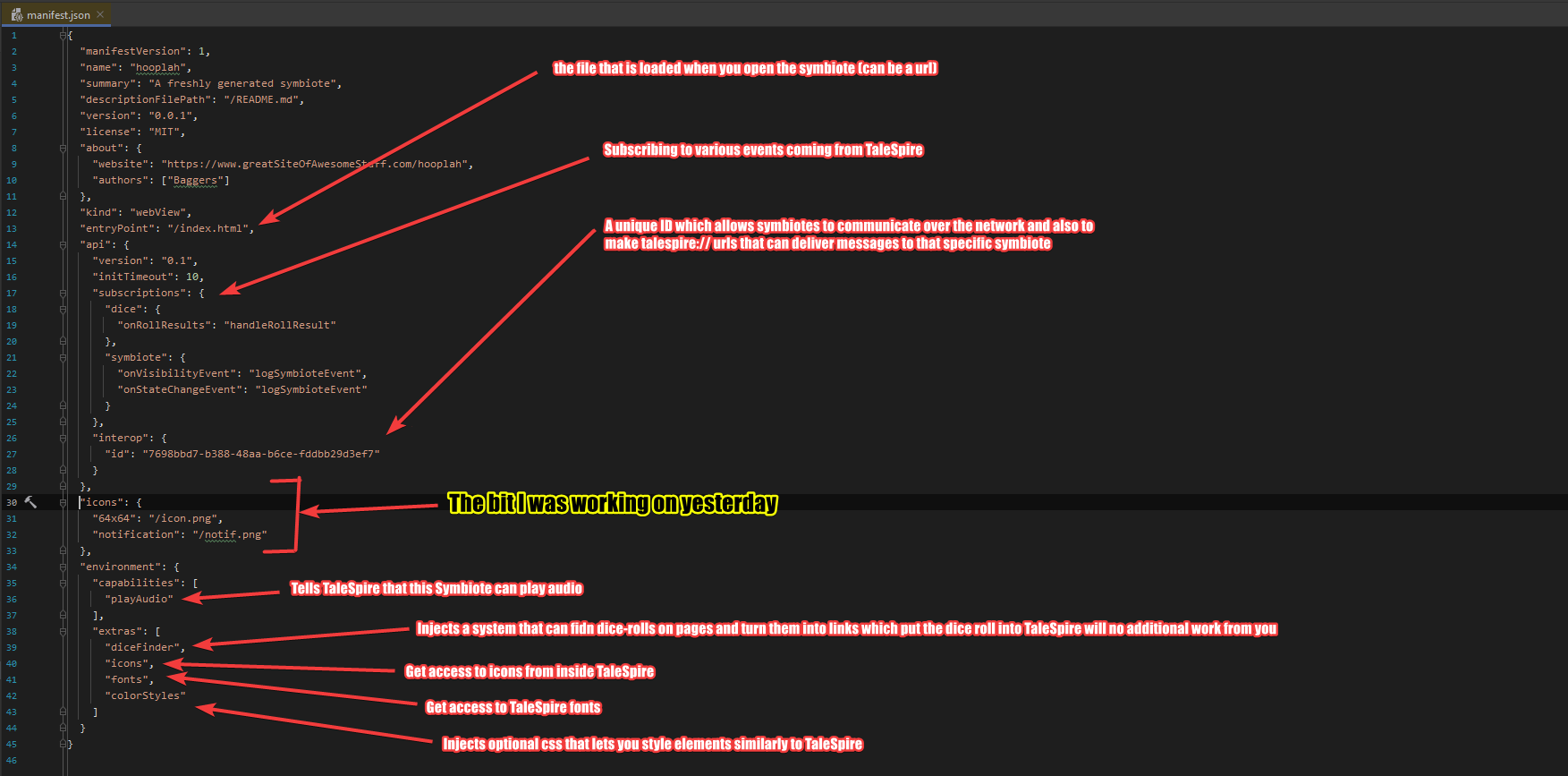
As you can see, I was focused on icons. We currently support a couple of kinds:
- A 64x64 pixel icon which is used for the symbiote in menus and such
- A smaller, greyscale icon that will be used for notifications
We can add more size options in the future as we need those, whether for nicer integration in mod-stores or higher DPI displays. But for now, this will work just fine.
I also fixed a bug in the formatting of talespire:// URLs generated by symbiotes. Let’s take a second to talk about that feature.
You folks probably have already seen that external programs can do certain things via talespire:// URLs. Importing boards, setting the dice tray, and so on have URLs that integrate with TaleSpire. It’s super helpful, and we wanted you to have that too, so we allow you to generate a URL specifically for your symbiote like this:

You can then put whatever text you like after the final slash (as long as it’s a valid URL) and it will be delivered to your symbiote when the URL is processed.
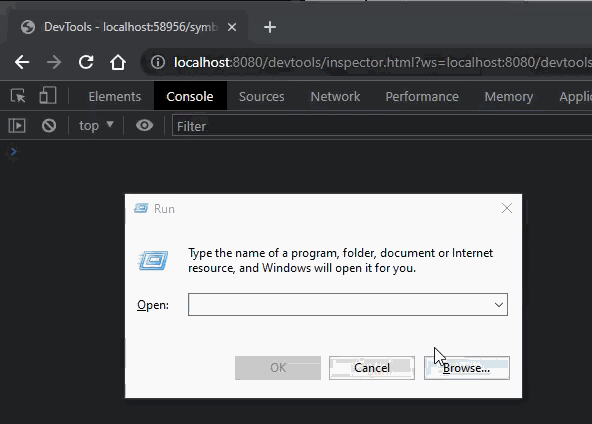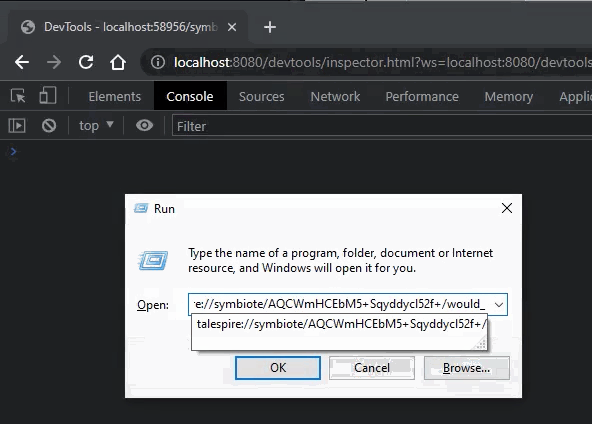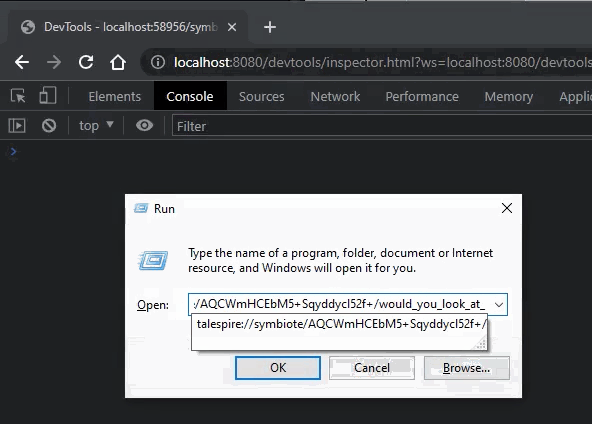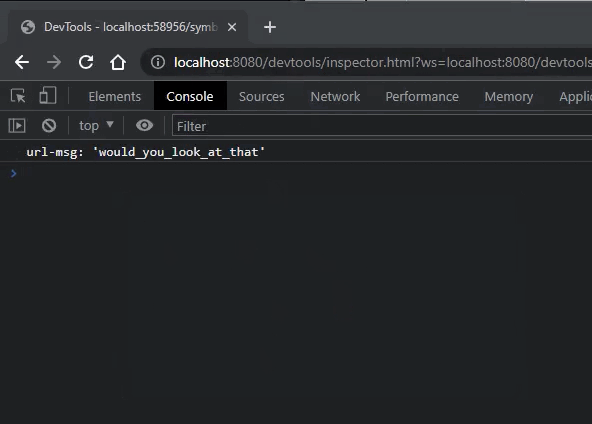
The console you are seeing is part of the dev tools in Chrome. When you enable dev mode in the Symbiote settings, you can connect to and debug your symbiotes trivially. I’ll talk more about this in another dev log.
Right! I gotta get back to work, so I’ll stop writing for now.
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] Not just supporting more features but supporting entirely different kinds of symbiotes.