From the Burrow
Talespire Dev Log 366
Heya folks!
I’m dropping in to let you know what I’ve been up to these last few days.
Hiding board list from players
I’ve done some work on the option for hiding the board list from players. I wired up the behind-the-scenes stuff and then handed it over to Ree as I was having some trouble with the UI portion.
All went well, so we expect this to be the next feature that ships.
Mac bug
In log 364, Ree talked about a bug blocking mac support and raised a ticket with Unity. I decided to spend a couple of days looking at it in case I could make a workaround. Spoiler, I couldn’t.
To trigger the bug, you have a light (which renders its volume without writing to depth buffer), and then you have something modify the depth in that area. What is extra odd is that it requires that you forward-render something for it to show up. It’s super weird. Check out this daft shit:

Looking at the Metal frame trace in XCode, the most obviously wrong thing is that the GPU actions from later command-buffers seem to be executed in an earlier command encoder. I don’t know enough about Metal to work out why this is causing the errors, but it is feasible that it’s related.
Unity has confirmed the issue, so we are waiting to see what comes next.
Persisting initiative
Today I spent my time working on the code to allow us to persist data from board-wide systems. This is going well. It’s hard to write much about as it’s mainly me poking around to find something I like. I will need to make another pass on this sometime as patterns are emerging between the different managers that persist board data.
Once I’ve got this done (I’m thinking at least one more day of work), hooking up the initiative manager should be trivial. I’m currently expecting this feature to ship late next week.
And that’s ya lot
Despite the mac bug, it feels good to be making steady progress. I don’t foresee any issues with persisting the initiative list. I’ll get right on to the Mod.io slab integration as soon as that works!
I hope this finds you all well.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 365
Heya folks!
It’s a short one today. Since the release of group-movement, I’ve taken a moment to relax. We are seeing a few crashes that we assume are group-movement related, so we’ll look into those asap.
I’ve driven east today to meet up with Ree for a catchup and the opportunity to work together in person. Our potential server/dev-op hire is also in the area, so we get to hang out and talk shop, which is lovely! [0]
My goal is to ship persistence for the initiative list and the option for GMs to hide the board list from players next week. Thanks to those server updates from earlier this week, this shouldn’t be too complicated.
And then I’ve gotta get cracking on the mod.io slab store integration. If all goes to plan, that will set us up perfectly for distributing creature mods!
Needless to say, I’m excited. Here’s to a productive run-up to Christmas!
Have a good one folks!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] We are still waiting on feedback from the Norwegian government on work status. Bureaucracy is a pain.
TaleSpire Dev Log 363
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
Let’s look at macOS
Work has continued at a good clip behind the scenes. I’ve got server updates ready for group move, new vertical controls, and the option to hide the board list from players.
Besides a few bug fixes, I’ve been working on support for apple silicon macs.
Apple Silicon
We have started our macOS support focusing on the new apple silicon macs as GPU feature support is spotty across older models, and the push towards the new architecture seems very strong. Steam’s hardware survey is already showing that over 49% of macs with Steam installed are apple silicon macs [1].
We are using the m1 iMac as our baseline for apple’s new lineup. If we can run well there, we can run well on the rest.
Final pre-show caveats
I remember an aphorism that goes roughly:
If you get a speedup of 100 or 1000 times, you probably didn’t start doing something smart but instead stopped doing something dumb.
While we are not seeing anything in the realm of 100 times speedups, we are looking at the “stop doing something dumb” category of fixes in this post.
“Dumb” code often arises simply from needing to implement something to discover what the feature would become. (But sometimes, it can also just be dumb)
Next, we are going to show timings in some parts of this post. While they were taken from an m1 iMac, they are intended to be purely illustrative. We are only showing timings from single frames and under specific loads. This is not a good representation of the performance in general.
With that said, we hope this is still interesting to some!
Part 1 - The start point
As I had recently been working on group movement, I decided to use some of the optimizations I had made for the lasso to improve culling for picking single creatures. This benefits all platforms.
I made a board with 600 creatures and got to work.

The picking code requires rendering the creatures into a buffer. With a mild amount of grief, we replaced the old code with one that culls the creatures and only draws the ones whose bounds intersect a ray from the camera.
This gave a 24x improvement for the code that dispatched the creature drawing for the pixel picker. It also reduces the amount of work the GPU needs to do, discarding irrelevant vertices.

Part 2 - Uploading data
Next, I had this fun one. In the image below, check out the timing differences between the green and red arrows for each platform.

The green arrows show when we start culling and dispatching render tasks to the render thread. The red arrows show when the render thread dispatches the render tasks to the GPU.
After a bunch of digging (and convincing XCode to let me profile a frame[2]), I saw that every call to ComputeBuffer.SetData was recreating the buffer. I changed the mode of the ComputeBuffer to SubUpdates, which had this effect.

Clearly, this has an effect.
However, with this setting, we can now write over data currently being used, which is not ok. So we have some work to do around here. This leads us neatly to…
Part 3 - The elephant in the room
I’ve been working heavily on speeding up CPU tasks. That’s all well and good, but the problem we really have is the time it takes to render things.
This is the scene I’ve been using for testing (ignore the graphical glitches, those are shaders that still need fixing and are unrelated to this case).
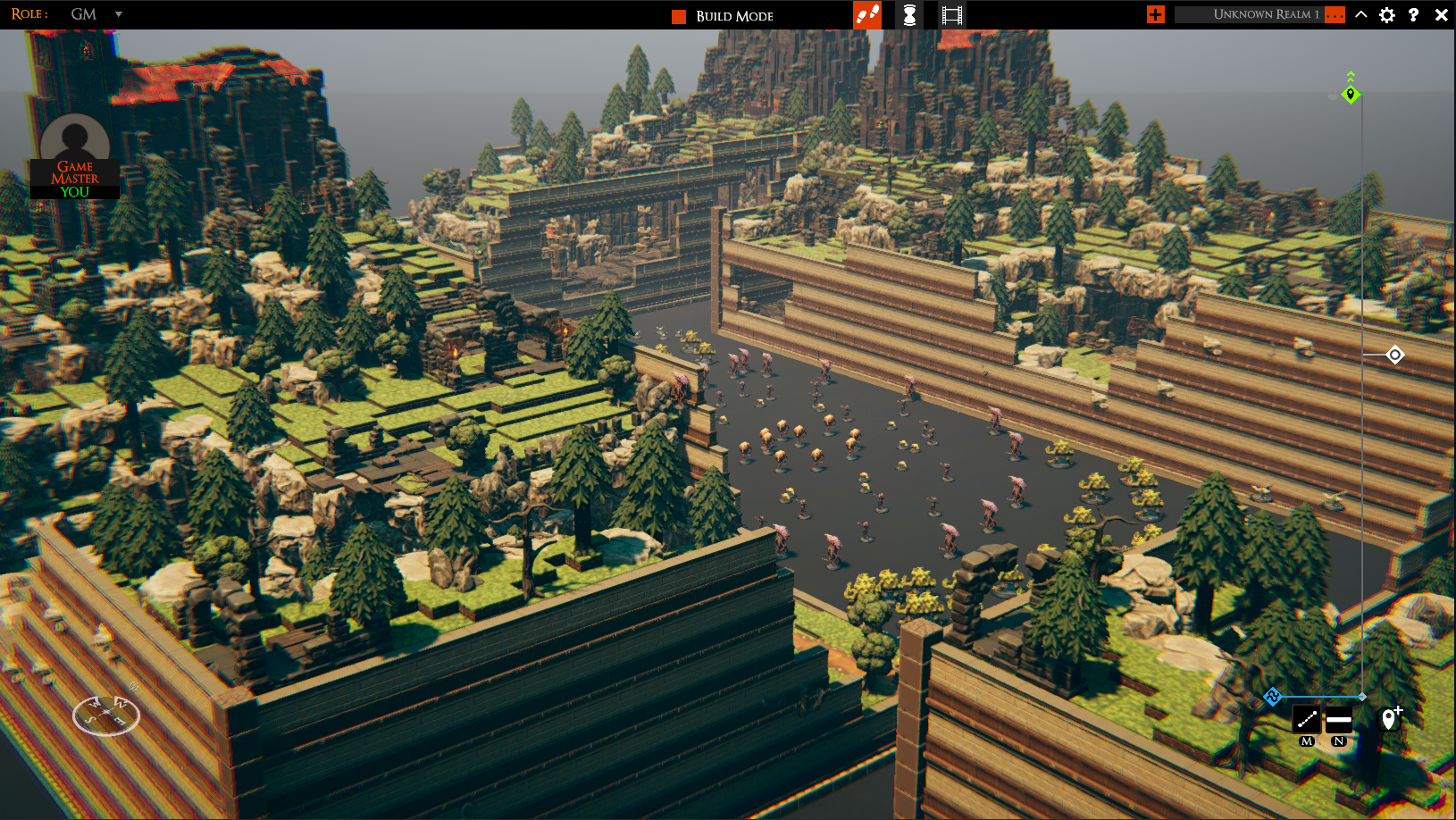
This is a lot to render. Currently, it’s taking over 25ms to do so, which is far too much. 30fps is playable, but we need to dig into how the shaders work if we hope to reach 60fps. XCode’s metal frame capture seems pretty temperamental, but I’ve got some captures we can work with.
Part 4 - Ignoring the elephant
That is not to say we shouldn’t work on the CPU side. By doing so, we can improve all platforms at once.
Given that rendering is always going to take some time, what can we do at the same time? By default, the answer in Unity seems to be “not much.” This is because their MonoBehaviours don’t expose a callback for all interesting points in a frame. However, Unity did add a low-level API to completely control the system that runs in a frame, which is terrific! [3]
With this new tool in hand, I decided to move the code that applies build changes to the data-model to just after render tasks have been pushed to the render thread.
This meant that, while we still needed to do the work, we hid it behind the work on the render thread.
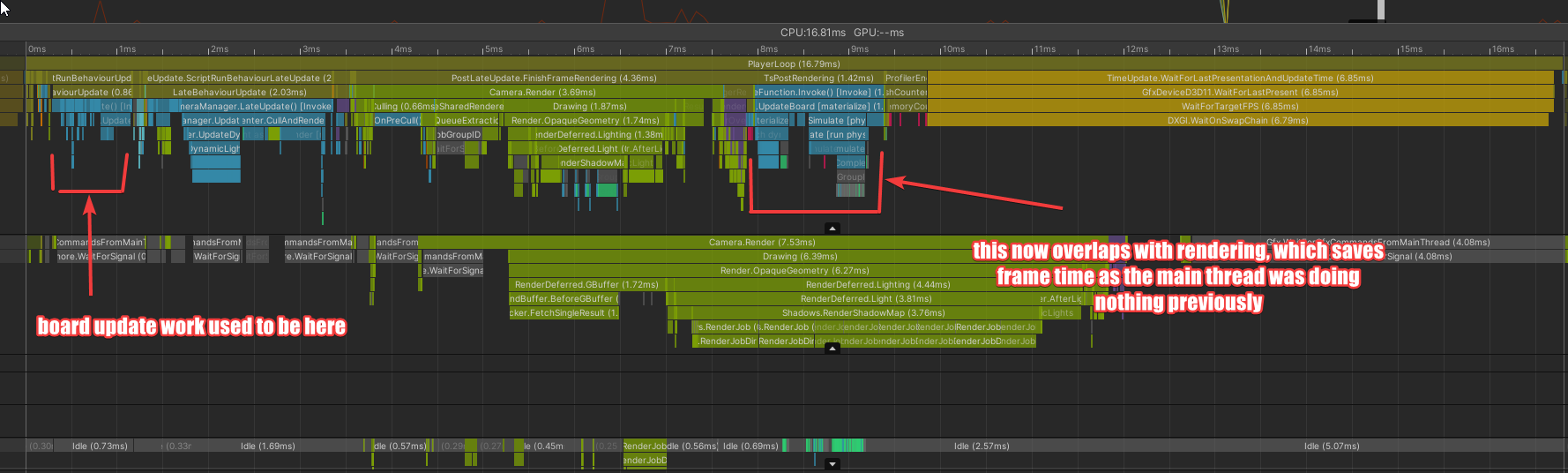
Part 5 - What elephant?
While I’m pretty happy with hiding work, I was looking at this capture and thinking…
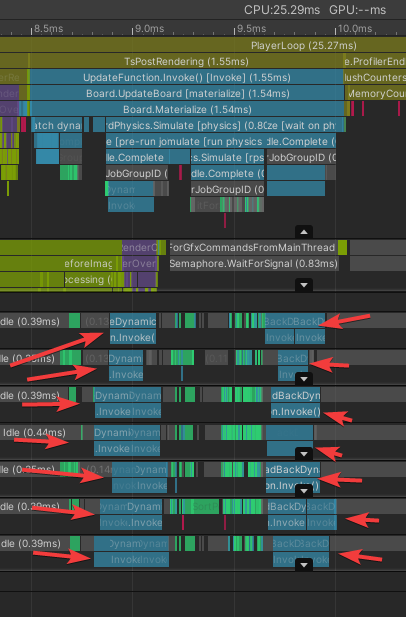
… what are these chunky jobs, and why are they taking so long?
The answer was that they are jobs that copy data from dynamic physics objects (like creatures) into the physics system before the simulation runs, and then copies the data back out afterward. The data came from managed objects, so the jobs could not be Burst compiled.
Instead, I moved this data into a native collection that our physics MonoBehaviour could index into when they needed the values. This probably makes main-thread access slightly slower, but this is not where bulk lookups happen.
This allowed for this change.
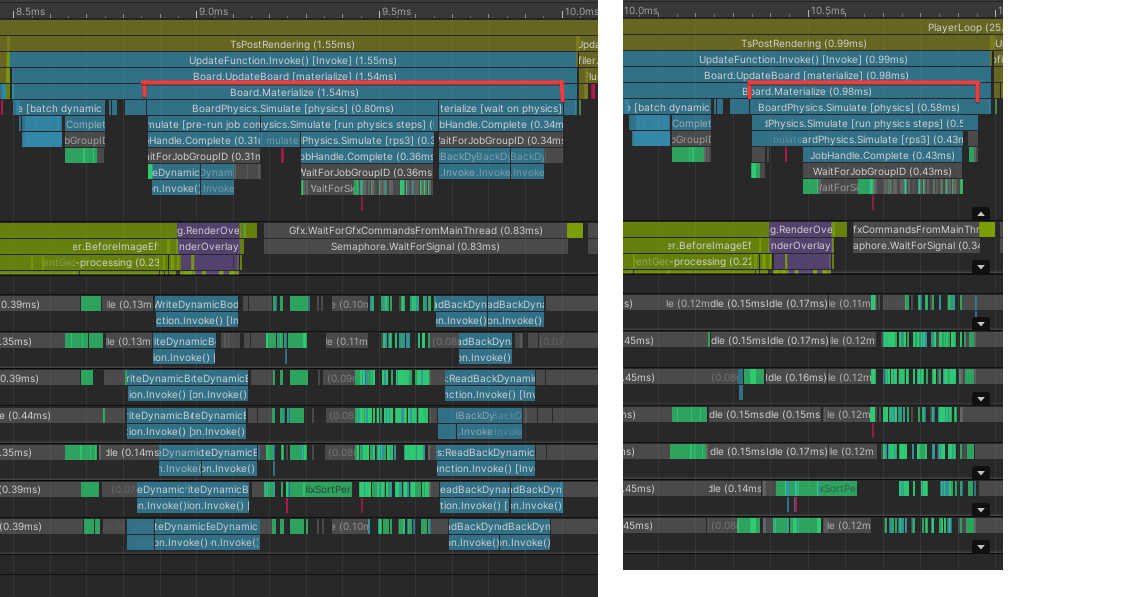
Pretty nice!
Part 6 - What next
The honest answer is “make the above work” :P
The ComputeBuffer data uploads aren’t safe, and the physics changes have some bugs. However, this feels tractable.
On the CPU side, some mesh generation code could be turned into jobs and burst compiled, which could give some notable wins. Also, creatures and dice currently take way too long to update, so I want to look into those too.
Really though, for mac, I need to look at rendering. Any improvements we can make to the shaders would be a big deal, and ideally, we would add LOD support to our batcher. I would love LODs to be a quick win, but because our code had to become so custom, this is not the case. I’ll take a look, though.
Anyhoo, that’s enough for tonight. I’ll try to post a few more dev logs this week, as I have fewer releases to do.
Peace.
[1] A huge caveat for this number is that Steam’s hardware survey is guaranteed to be biased due to the chicken-and-egg nature of gaming on mac. Without a big game market, game makers can’t afford to focus on mac, and without that focus, the market stays small. (In my opinion) Apple also doesn’t seem to care about games outside of gloating at conferences, which makes adoption harder. However, that’s a grumble for another day.
[2] No matter how long I work with XCode, it is still exhausting.
[3] You can find some ace articles about the PlayerLoop API here:
- https://medium.com/@thebeardphantom/unity-2018-and-playerloop-5c46a12a677
- https://www.grizzly-machine.com/entries/maximizing-the-benefit-of-c-jobs-using-unitys-new-playerloop-api
- https://www.patreon.com/posts/unity-2018-1-16336053
TaleSpire Dev Log 362
Heya,
I’m hopefully wrapping up work on the “move whole AOE” feature today. There are only a couple of things left.
The first is we need a better visual. The boxy thing I have in the clip below won’t do.
The second is testing network play. This is the only one that could delay things. I don’t anticipate any problems, but that is often the case :)
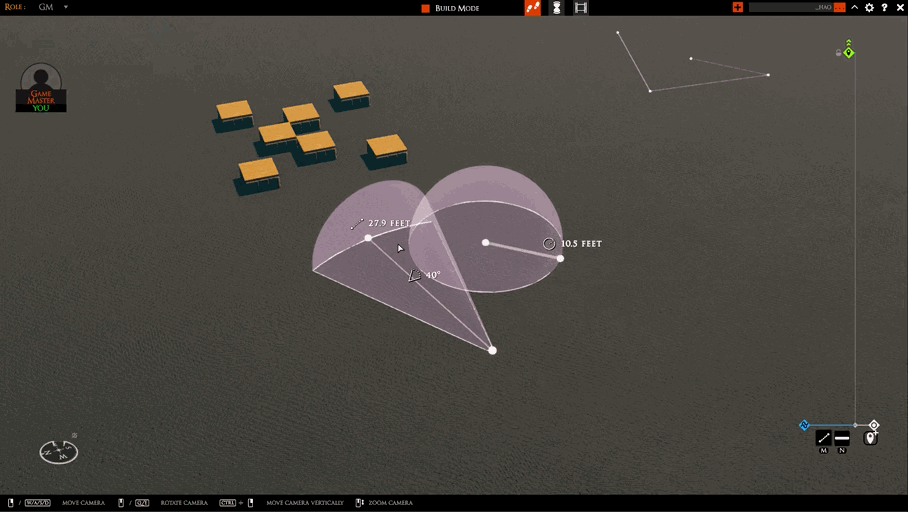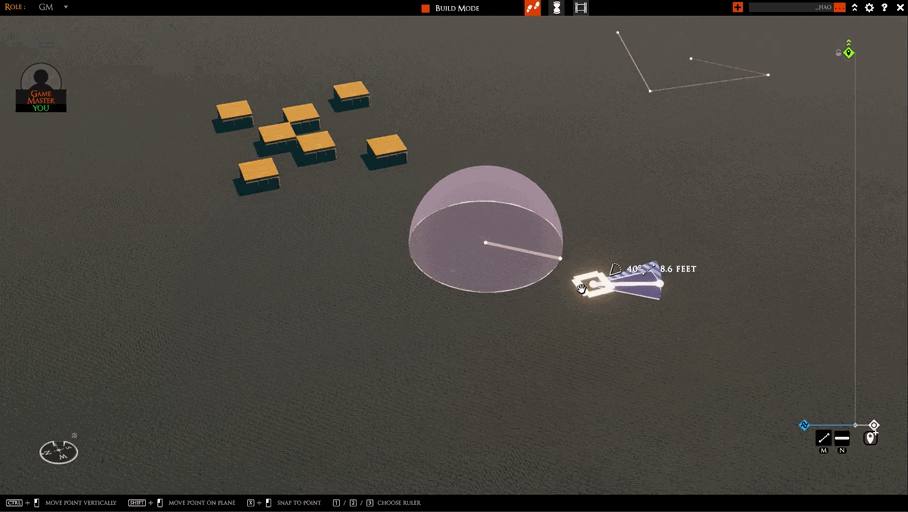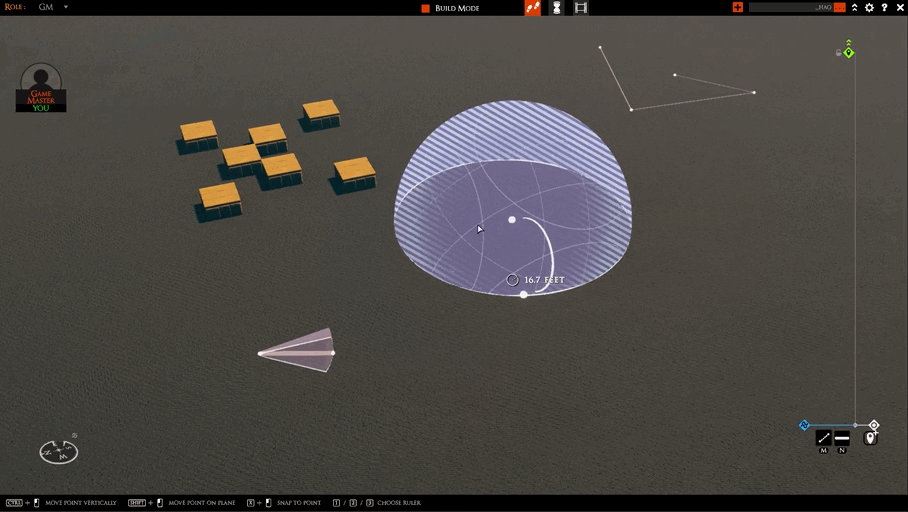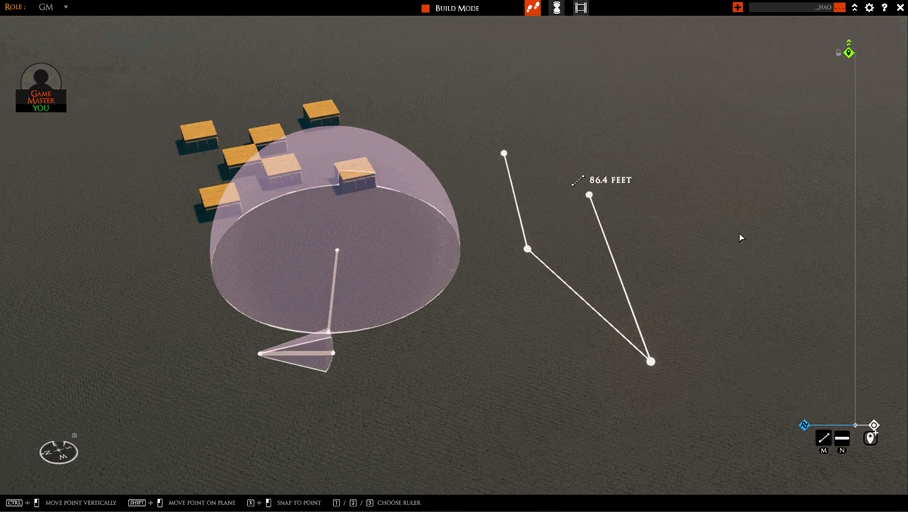
After that, I’m switching to two tasks:
- Catching up with some poor folks I’ve left in the lurch with bugs for a long time.
- Performance fixes required for the macOS beta
Those two will likely fill my next week, but I’ll drop in to let ya know how it’s going.
Ciao
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 361
Allo!
After releasing the AOE markers feature, the number one request we got was to add a way to move an entire AOE in one go. This week I’ve been working on just that.
In the clip below, you can see a square that you can grab that lets you move the whole AOE. Of course, these are dummy visuals that are just there to help me develop the feature.

Our plan is to make the visual a ring surrounding the handle. That way, you can grab the handle to adjust just that point or the ring to move the whole AOE.
The implementation so far has gone well. It requires a slight adjustment to the save format to support the feature, but that is already underway. I’d love to get this out this week, but
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 359
Hey folks.
After the push to get group movement into Beta, I’ve taken this week a little easier.
I’ve been quietly working away on the performance of the lasso picking, and I wanted to show some profiler screenshots, but I’m still chasing down some bugs, so I’ll save that for another day. The issue goes like this:
- We need to render creatures for the lasso picking
- When we enqueue them using a CommandBuffer, Unity doesn’t “batch” them into an instanced draw call, so we end up with a lot of draw calls
- We can perform a DrawMeshInstanced call ourselves, but then we have to handle the per-instance data ourselves as we are drawing a mesh, not a Unity Renderer
We could use a MaterialPropertyBlock, but doing this is extra work. How about we do something nastier. We already have to provide a Matrix4x4 transform for every instance, but only three rows of that matrix are being used. So let’s sneak the extra data in the last row. This will absolutely break the world-to-local matrix Unity will generate, but we aren’t using that, so hopefully, we can ignore it. With this, and some bodging in the shaders, we get the data we need to the GPU and MASSIVELY reduce the number of draw calls.
For example, this screen goes from over 400 picking related draw calls to about four.
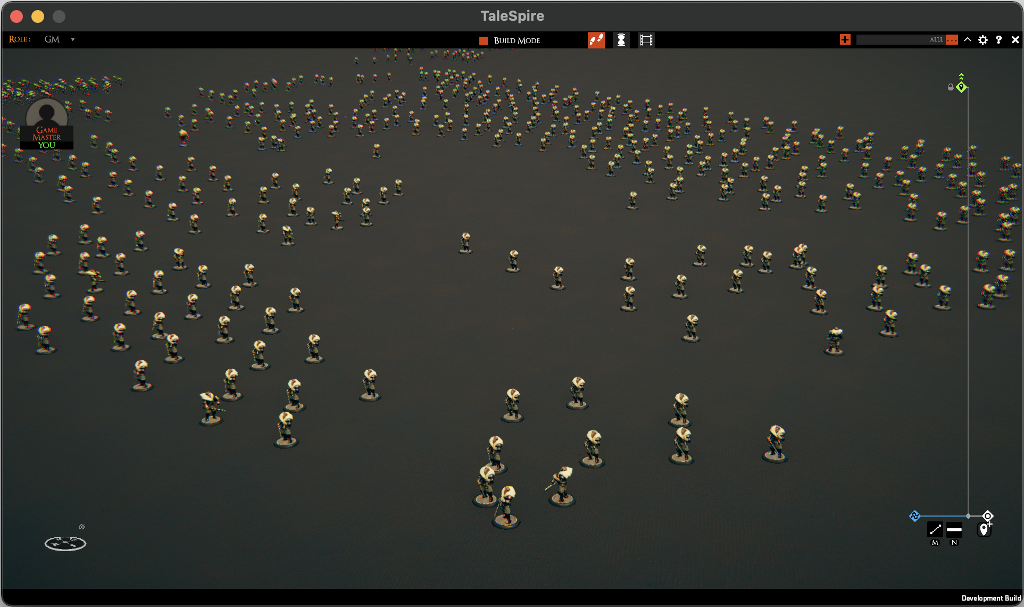
The scene might seem contrived, but higher numbers of the same creature are expected when dealing with armies.
During the above work, I also spotted that I could accelerate the rough culling we do when picking creatures normally. Most won’t notice this, but it definitely makes a difference on lower-end machines. This is part of the required work for the macOS release, so I’m happy to be doing it.
Alright, I’m very sleepy, so I’m heading off now.
Have a lovely weekend.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 358
Morning all,
I’m currently working full-steam on getting a beta build of the group-movement feature to all of you.
Yesterday I gave the lasso prototype to some folks for private testing. The feedback was generally positive, but naturally, they found some new bugs and highlighted some annoying behaviors.
I’m now working through that list, fixing the critical stuff. Hopefully, I can get those done today.
I’ll then write up the usual beta guides and tutorial videos so we can hit the publish button!
I won’t promise a date, but we are close.
One big spanner in the works is that I need to have some work done on my car, which may keep me out of the office most of the day. We’ll just have to see how that goes. If I’m stuck in town, I’ll use the day to work on server code, which is easier to work on from my laptop.
Have a good one folks, Ciao
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 357
Yesterday my goal was testing the group movement with multiple clients and, as mac support is progressing, I decided to use that for the testing.
To do this I updated our native plugin to support the lasso and broke out the profiler to check that the implementation was going to be viable on Apple Silicon. Luckily enough it ran perfectly, but as I looked at the profiler I got curious about the somewhat poor performance on medium sized boards. This led me into a day of prodding, profiling, and remembering how much I hate dealing with XCode.
The TLDR is that the M1 iMac currently struggles to render the shere amount of stuff we regularly put in our boards.
That of course won’t be the end of the story. I bumbled my way through getting an XCode build of TaleSpire that allowed for GPU profiling and the captures contains reams of data giving clues as to where we can speed things up.
We are going to need to do a lot of experiements but the work we do there will probably benefit lower-end PCs too.
There is more I can ramble about, but I’ll get to that when I’m working on mac support again so I’ll spare you that for today.
Alright folks, now I should get back to testing.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 356
Hey folks.
I’m back again with a group-selection update. In short, progress is very good.
I spent a couple of days finding a control scheme that felt good. I wanted the interaction to be based around a single modifier. You hold down a key (in my test, x), then you left-click and drag to draw the lasso. You can also single-click on a creature to add/remove them to/from the selection. It sounds simple, but I managed to go in circles a few times, ensuring that switching between single creatures and groups felt natural. It’s easy to add extra modifiers and make things feel like a tool. I’m happy to have somewhat avoided that.
Having spoken to Ree, we’ve also discussed trying another approach to the lasso control. I’ll talk about that more as it develops.
With the behavior taking shape, I turned to performance. I knew from the start that the regular C# implementation would be too slow. I wrote the code assuming that I’d be switching to compiling with Burst and using native collections. My initial tests[0] showed that updating and meshing a sizable wobbly lasso took between 14 and 17 milliseconds, which is hilariously bad[1]. By compiling with Burst, that was chopped down to a few milliseconds.
From there, I bucketed the lasso segments spatially so that intersection checks had to consider fewer segments. With this and a few more techniques, I dropped the time required to around 0.3 milliseconds.
The next part of the optimization was moving the whole process (including setting up the Unity mesh) into jobs. I spent quite a while playing with different configurations[2] until settling on what we have now. The lovely thing is that, in the typical case, the jobs are finished before the main thread needs the result. This results in the main thread only having to spend ~0.01ms on updating the lasso and mesh.
While there is definitely more I can do to optimize the lasso code, it’s plenty good enough for now[3]. It was then time to work on other actions that groups of creatures could perform. If you’ve been on our discord, you’ll have seen some clips of that work. If not, then here you go!
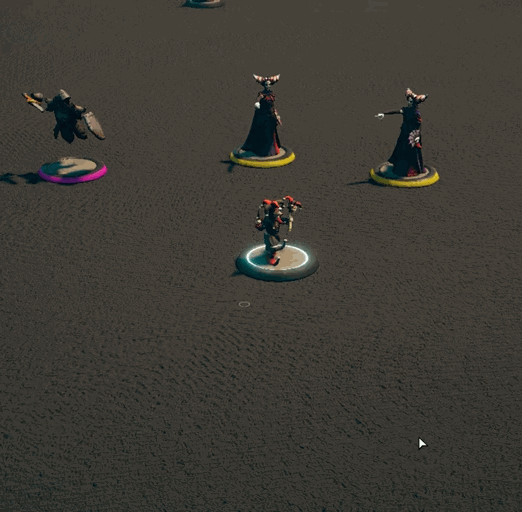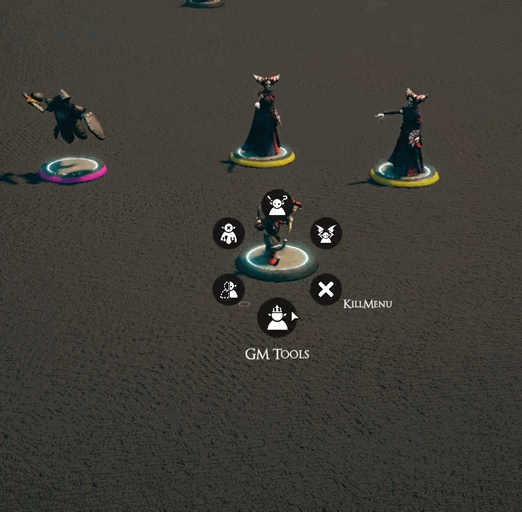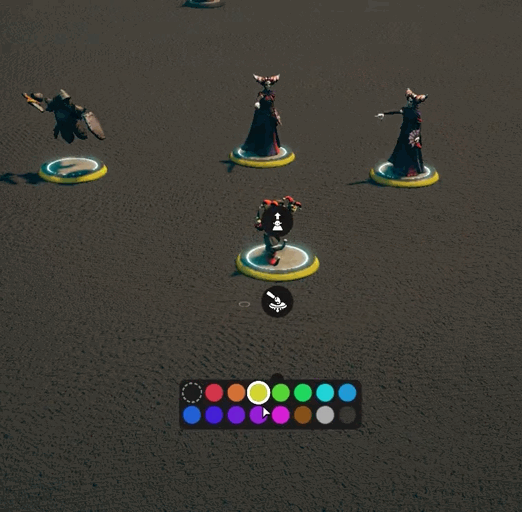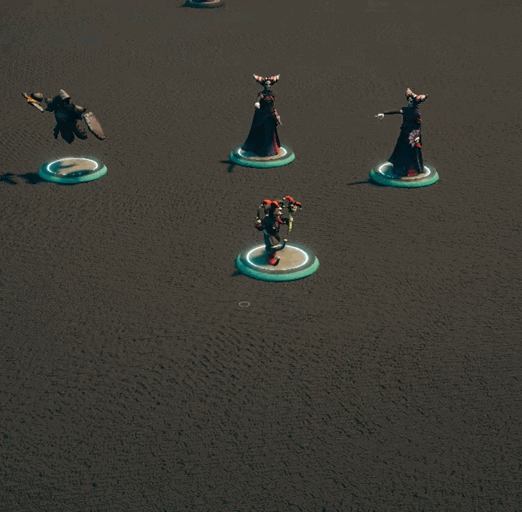
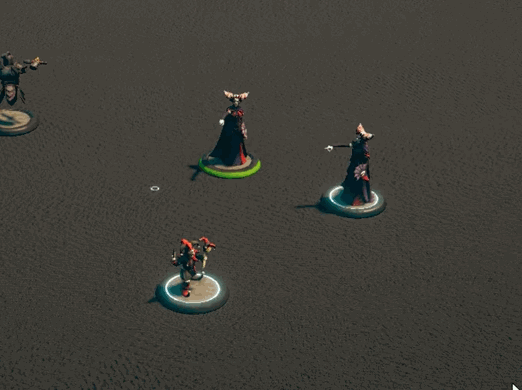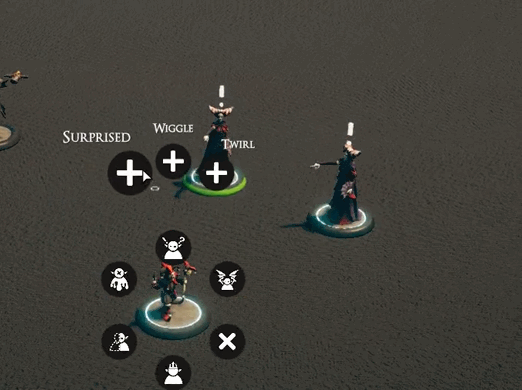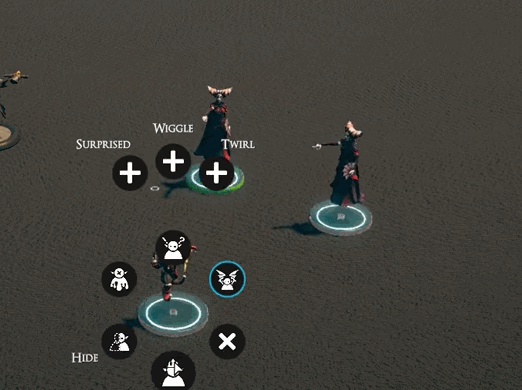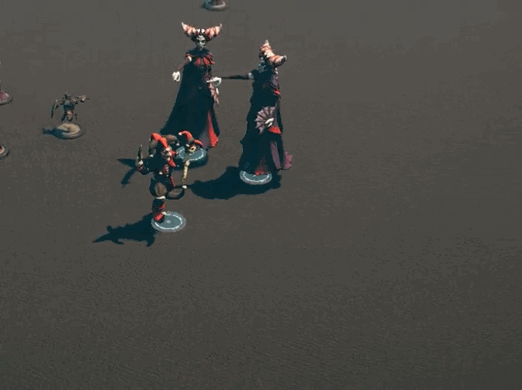

I’m not trying to support everything out of the gate, but some things just felt like they needed to be there.
Well, that’s all from me for now. While I have started looking into performance improvements needed for the macOS release, I’ll leave the details of those for another day.
Have a good one!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] I’m talking about timings, but it is very misleading. The time needed to update the lasso depends on many things, such as the lasso length, the number of self-intersections, etc. For narrative reasons, I’m going to mention numbers, but the only thing to really take away is that they got better :)
[1] For those not familiar. To run at 60fps, you need to be done with everything for a frame in 16.6ms. Spending that time just for a lasso is naturally unworkable
[2] For example, I experimented with running the meshing of separate lasso chunks in parallel. This was promising, but the overheads undid the benefits I saw from the concurrency.
[3] There are lots of other things to optimize before this one creeps back to the top of the list :)
TaleSpire Dev Log 355
Hey everyone.
As hoped, a lot of things came together today, so I’m thrilled to be able to show you this:
The lasso is finally working!
I’ve still got plenty to do, but I’m very confident about what remains.
First off, I need to clean up the implementation. Some things are still hacky and/or inconsistent with other tooling[0].
After that, the big priority will be performance. The current implementation is abysmally slow, but this was expected. I wrote it in an exploratory manner but made sure not to write code that would be hard to optimize later on[1]. If the code is slow in the ways I expect, then a combination of Burst, threading, and some spatial hashing will solve it. But we’ll see once the code is profiled.
After that, the feature should be in the cleanup phase. Tweaks, bug fixes, and testing will be the order of the day[2]. Of course, the visuals for the lasso need making, but they should not impact any other part of this feature.
And that’s the lot for today. Tomorrow is going to be another fun one for me, though not as visually dramatic :)
Have a great one folks!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] I’m being a bit nebulous as explaining it would be clunky without code examples [1] To me, this mostly means keeping to simple constructs and not writing “clever” code. [2] I’ll also be porting the c++ portions to macOS. But I think there is less than an hour of work to do there.