From the Burrow
TaleSpire Dev Log 269
This dev-log is an update from just one of the developers. It does not aim to include all the other things that are going on.
Hi everyone!
This is my first one of these post-release, and it’s been a weird first week, that’s for sure. In some ways, the game has been much more stable than expected. The servers have held up well, and, from watching twitch, it seems a good bunch of people have been able to play, which is great. This meant I could take the weekend off and start the process of catching up on sleep. This was very welcome after the nervous lack of sleep caused by the approval delay.
Now I’m a bit more compos mentis I’m tackling bugs, focussing primarily on any that cause crashes or stop people joining boards.
One bug in line-of-sight is a bit of a blighter and which I’m now waiting on more information on. We have players for whom supportedRandomWriteTargetCount is one, this means that when calling SetRandomWriteTarget you’d think you want to call with index zero. However, as the docs explain:
The UAV indexing varies a bit between different platforms. On DX11 the first valid UAV index is the number of active render targets. So the common case of single render target the UAV indexing will start from 1. Platforms using automatically translated HLSL shaders will match this behaviour. However, with hand-written GLSL shaders the indexes will match the bindings. On PS4 the indexing starts always from 1 to match the most common case.
However, SetRandomWriteTarget checks if the index is greater-than or equal to supportedRandomWriteTargetCount, and if so throws an out of range exception.
I’m fairly sure this means that the one random-write-target that supportedRandomWriteTargetCount is referring to must be the render-target. If so, it means that I’ll need a new approach for line-of-sight on these GPUs. What a pain :D [0]
That aside, the next patch will have (amongst other things) a few small fixes to issues stopping players from joining boards.
Have a good one folks
[0] In future, we will be focusing on supporting lower-end machines. It is its own art, so we are trying to get the game proper functioning well first.
TaleSpire Dev Log 267
Heya folks, just a quick one to let you know that work is progressing well. I’m currently fixing the last annoying little bugs in party line-of-sight, and then I’ll be wiring all this up to the fog-of-war code.
I can’t wait to be pushing this all out in an upcoming patch
Peace.
p.s. Just a reminder that fog-of-war will be super experimental. Both visually and functionality wise it is not ready for use in real campaigns. However, it’s gonna be great to have it in your hands so you can start kicking the tires :)
TaleSpire Dev Log 266
Hi folks.
This dev-log is relatively niche but will be helpful to the few who are into it.
In the beta, all tiles had an associated .boardAsset JSON file which held information about that tile. Since then, we have replaced the multiple JSON files with one index file with a binary encoding. Although better for the game in every measurable way, the binary format makes it hard for the community-driven sites to get info on the tiles, props, and creatures in the game. To that end, we have added an index.json file which holds a useful subset of the binary file.
You can find this at <path to the steam files for talespire>/Taleweaver/index.json
You can find an overview of the layout here https://github.com/Bouncyrock/TaleWeaver-Community-AssetPack-Index-Format/blob/master/format.cs
It is written in a C#-like pseudo-code but should be enough to get curious folks started.
We also now pack the asset icons into atlases, so the JSON file includes the per asset information of where in the atlas the icon resides.
Have a great day!
TaleSpire Dev Log 265
Heya folks,
It’s been a pretty heavy few days since the release. The beta went from feeling stable back to feeling very beta, and so we’ve been working away trying to get things back to stable as quickly as possible.
The upgrader and crashes have been number one on my plate. It is a gut-punch to see people not be able to play and, so I’ve been pushing hard to get those fixed. I introduced new bugs in the process, which really compounded that gross, ‘pit of the stomach’ feeling. No data was lost, but it sucks to worry people that they might lose their creations.
The bug was in the upgrader and is now fixed. The next update will re-introduce the downgrade button.
As before, the downgrader is only helpful for restoring certain things. As of today, it can fix:
- Missing hide volumes: in the case you upgraded and they were missing
- Boards which were empty after upgrade (potentially except for creatures)
The next patch will also fix the bug where, if a board crosses a certain number of lights, all the lights go dark.
Next, I’ll be looking into some of the layout bugs resulting in particular objects (like doors) being at the wrong angles. I’ll also be continuing work on any issues related to the upgrader.
I hope you are all keeping well,
Ciao.
p.s. Oh, and Happy Easter for those of you that celebrate it :)
TaleSpire Dev Log 264
Phew! Well, that was an ‘exciting’ start.
The big upgrader bug was a use-after-release of some malloc’d memory (seriously, who allowed me to have pointers). Took a little while to track it down as different code would trigger the final crash. After that, it was about 3am so I slept like a log.
Back today to start looking at all sorts of stuff. I need to take a quick look at a LoS issue while I’m with Ree, and collaboration is easier, but then I’ll be back on a raft of bugs (especially upgrader-related ones).
If you’ve had issues with the upgrader, don’t worry, the original board data is safe. I’ve written some routines that should also let us roll back and retry the upgrade if needed. We’ll see how it plays out.
It’s gonna be a heavy couple of weeks as we need to land more stuff for the EA release. Nothing to do but do it!
Special thanks to the bug reporters and folks digging through all this.
Seeya around the Discord :)
p.s. The new format for the slabs is coming. While encoding them in the slab and pasting them was simple, undo/redo brought with it a world of pain. Maybe something to chat about on a stream sometime.
TaleSpire Dev Log 263
I wanted to write an update, but it’s all particular, so sorry this one isn’t exciting.
I’m working on persistence again. A while back I decided that, to start with, we will have two files per sector. One which everything will be persisted into and one that will only hold some kind of changes. The reasoning for this is that when a person copies a board to play, they will be moving around creatures and using objects (chests/doors/etc), and we don’t want that to invalidate the whole sector and cause a copy of the tile/prop data on the backend. So instead, the first file acts as a base, and the second optional file is applied on top.
I’ve updated the backend to support this.
I also set things up to keep the three most recent saves for each sector on the server. This will allow for a rollback in case of bugs. However, I’m still not sure what form the UI should take for this in TaleSpire itself.
I’m now focused on updating code to keep track of the board’s modified regions (using the masks from yesterday’s post) and changing how the non-unique creatures are persisted.
Tomorrow will be lots more of this, so I’m gonna go get some sleep.
Seeya around!
TaleSpire Dev Log 262
Hi again, time to recap what I’ve been up to today.
Aside from fixing a bug in picking, my focus has been on board sync.
We will soon be syncing sections of the board on demand rather than downloading the whole board. This means a bunch of communication between the client and server requesting information about the board’s state.
Naturally, instead of sending long lists of sections in the requests, we would prefer a more compact approach. To that end, we use masks a lot. Our regions of the board form a hierarchy:
- a board contains sub-boards
- sub-boards contain sectors
- sectors contain sub-sectors
- sub-sectors contain zones
Using sub-sectors is optional, and so I’m going to skip over those today. All the requests I’m interested in are about sectors.
Each sub-board contains 64 sectors, so a 64bit mask paired with a sub-board id is a very convenient representation for identifying a bunch of sectors. I had written the code to produce and manipulate these masks, but I had seen an issue a while back that suggested that the math was incorrect. Because of that, I put today aside for testing.
It’s rather tricky to stare at a 64bit number and correctly picture the 3D mask it represents, so I knocked up a little project for visualizing them (Unity makes this very easy)
First a visualization for a single sub-board:
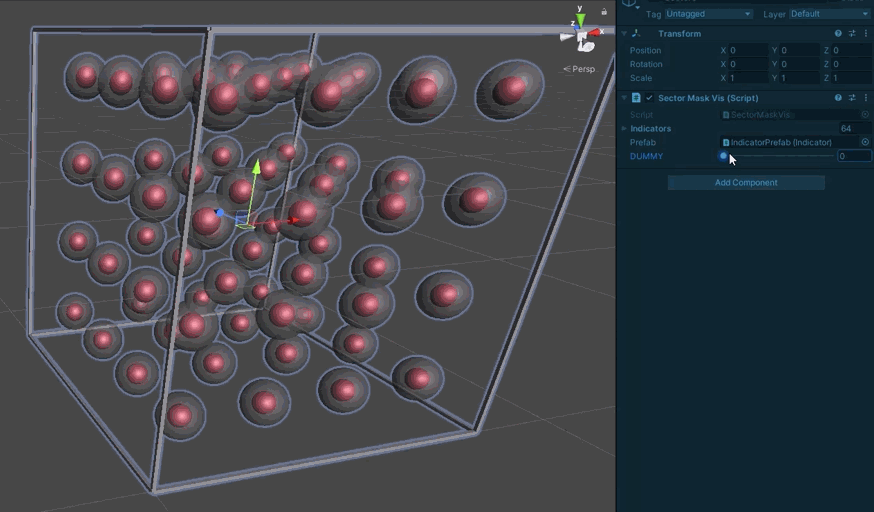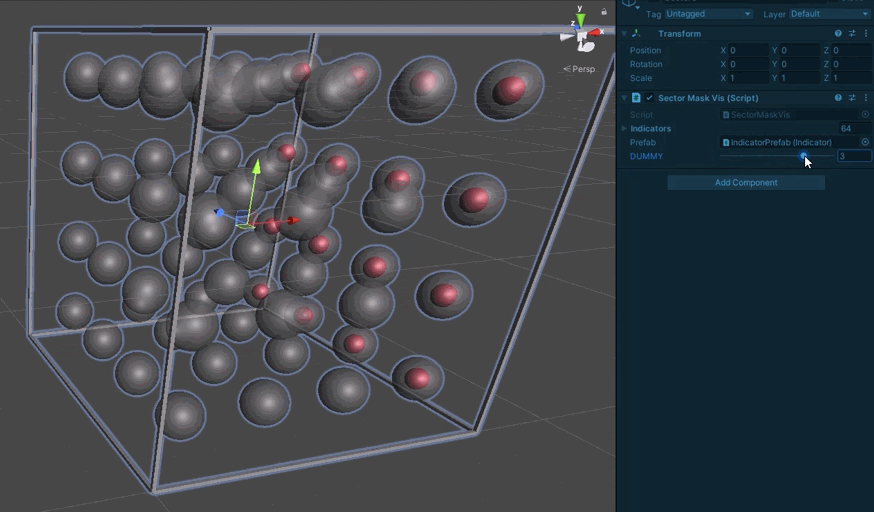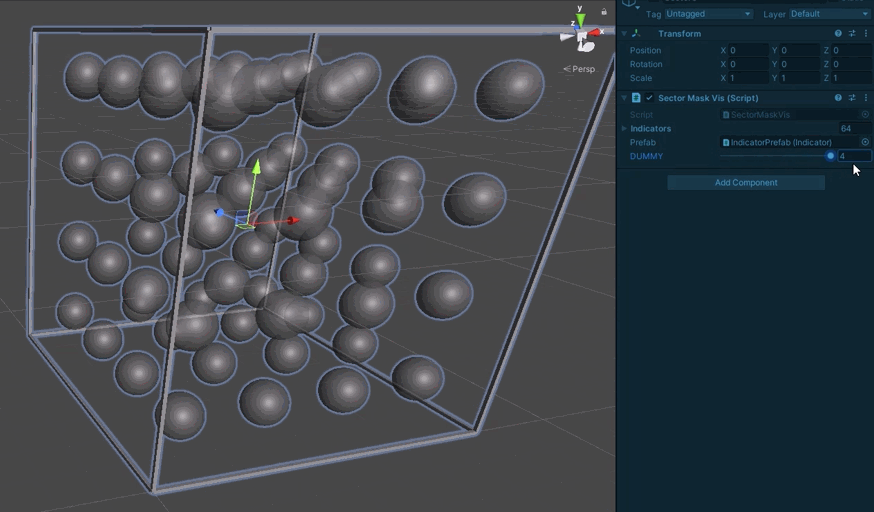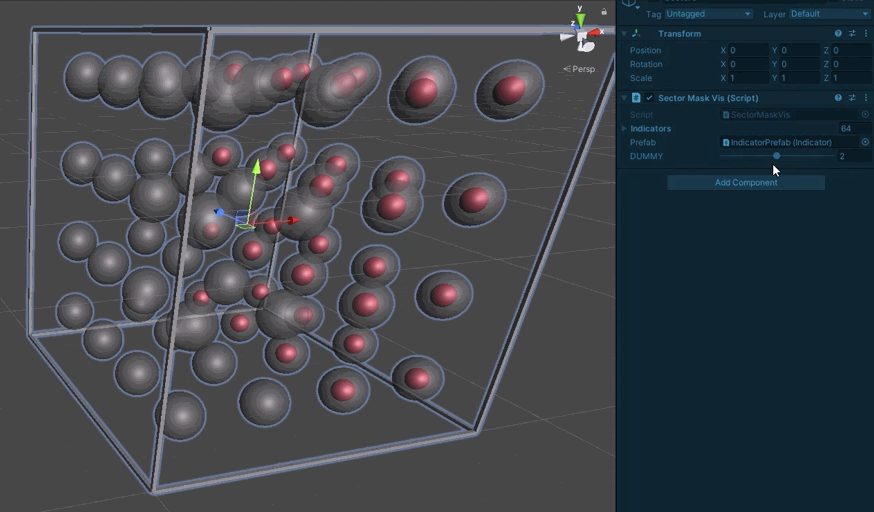
Each spherical indicator represents one sector. One the center is red, the bit is set in the mask.
From there, we build up to multiple sub-boards so we can test crossing boundaries:
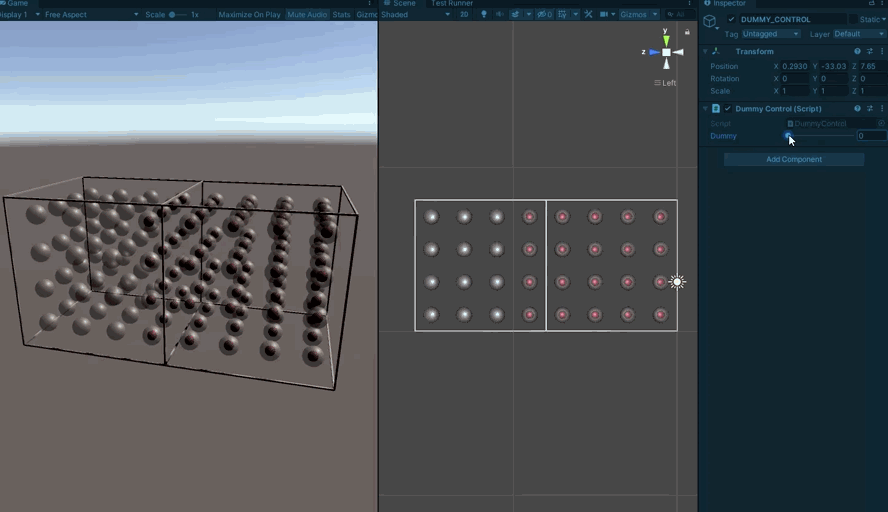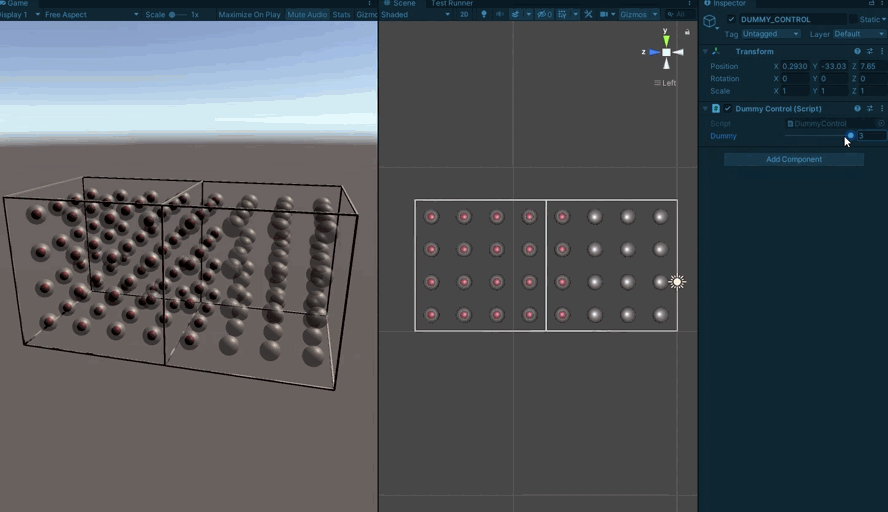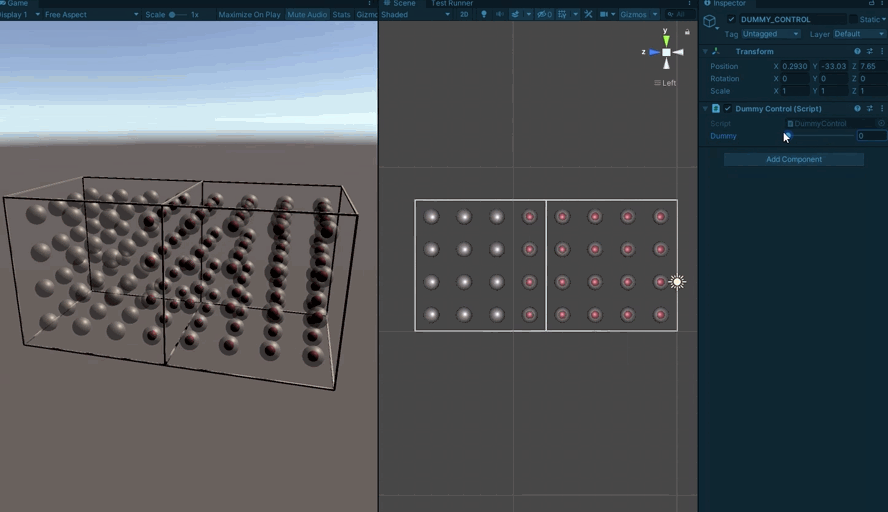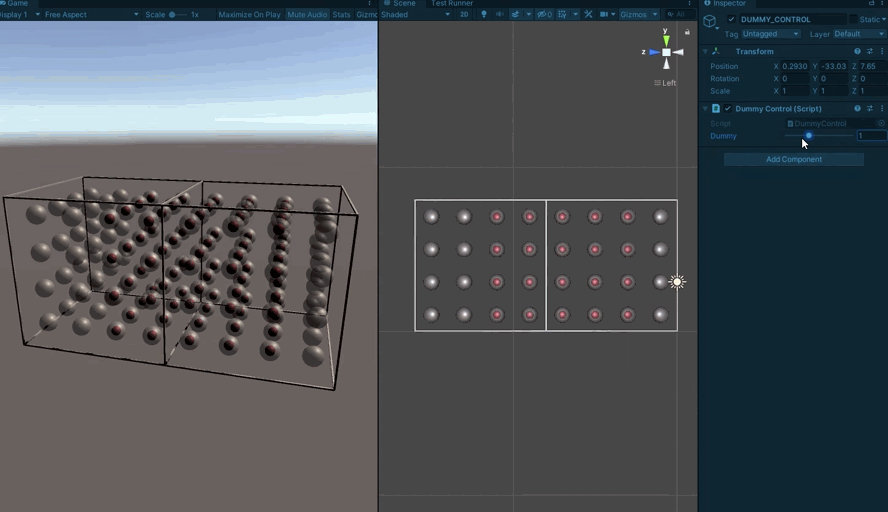
And then finally to testing a full board’s worth.
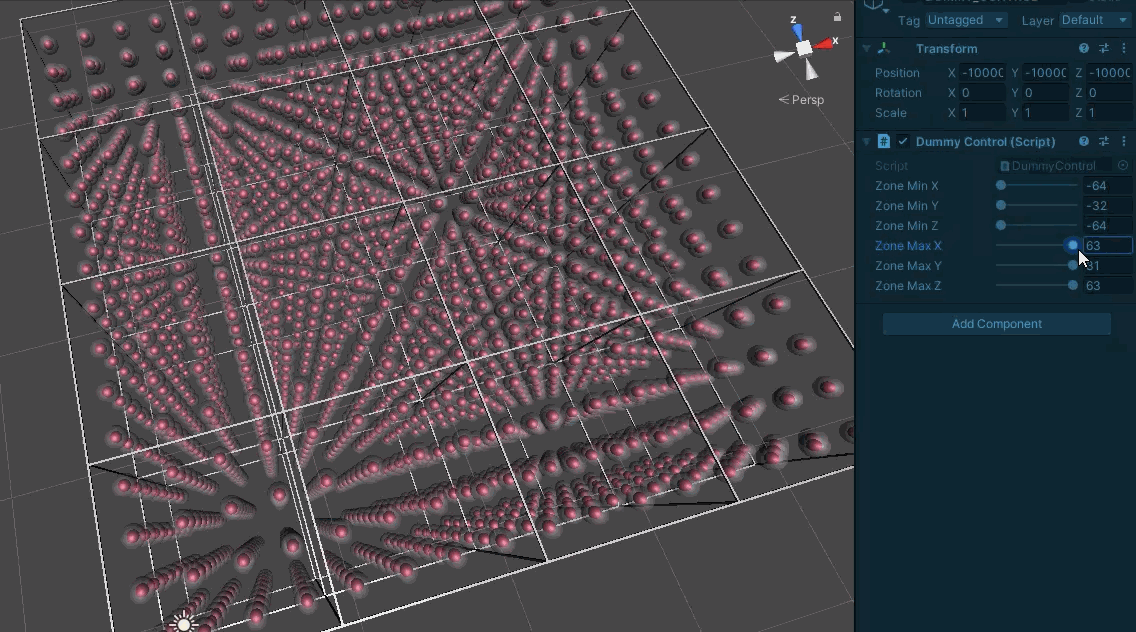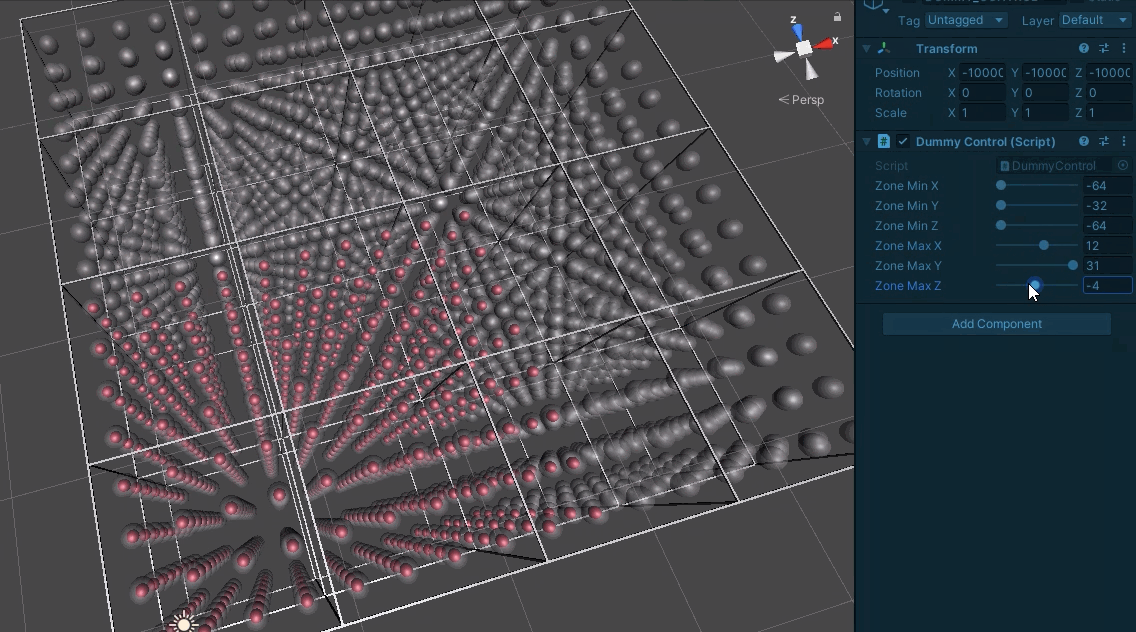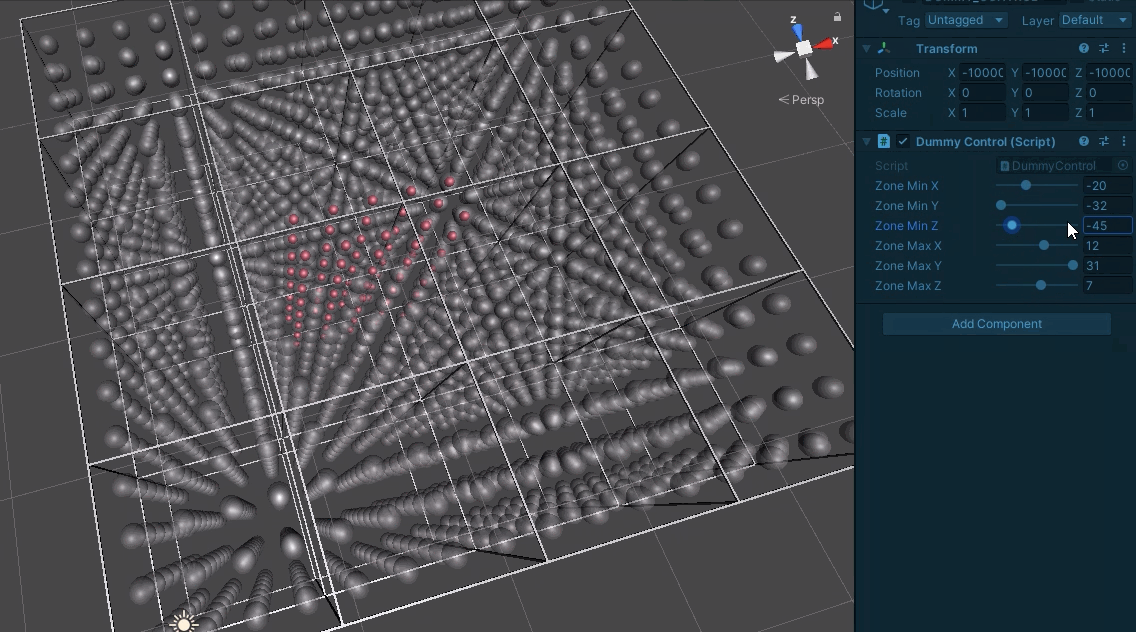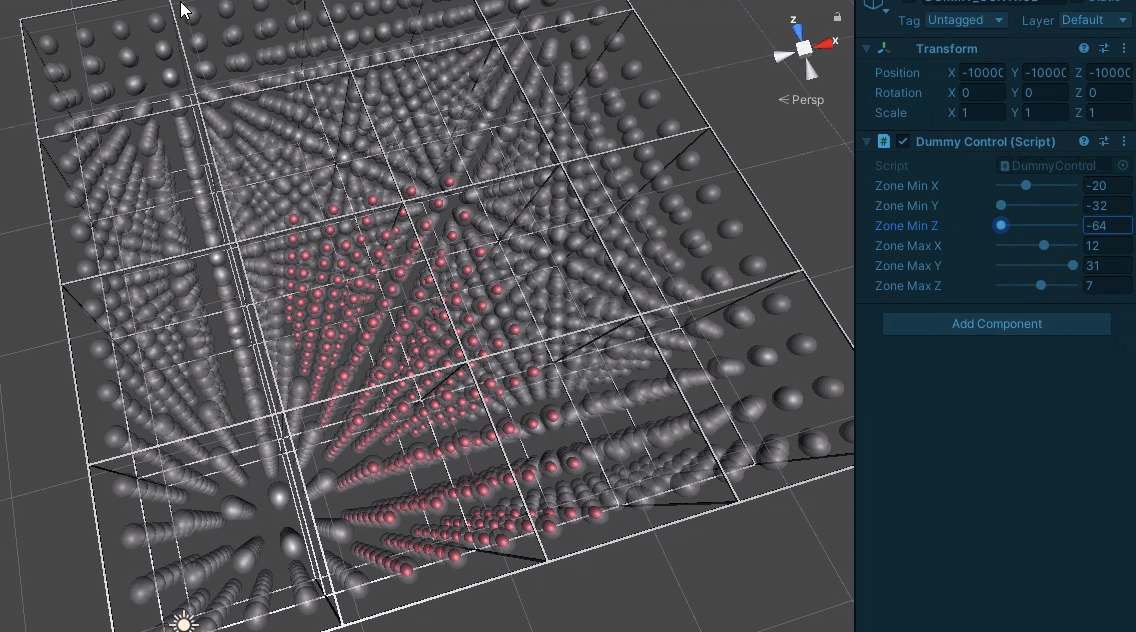
We can now be much more sure about the masks being produced. This is a relief as beyond server requests, they are also used to track modified board regions and whether they have loaded.
Tomorrow I’ll probably be looking set separating the storage of script & non-unique creature state from the rest of the board data. This will minimize the amount of data changed when people are playing boards shared by others. Once the non-unique creature state has moved, I can at long last add copy/paste of creatures. I have held off on that for AAAAAGES as it makes it far too easy to add hundreds of creatures in a single action, and previously all creatures lived in the database, meaning lots of server requests.
Once creatures are added to copy/paste, I’ll publish the new format so the community can be ready to support it when it lands.
Anyhoo I’ll keep ya posted with all that in the coming logs.
Goodnight.
TaleSpire Dev Log 261
Howdy folks!
We had a round of testing to see where we are at, and it’s pretty positive. There are significant bugs to squash, and the new backend hasn’t landed yet. However, it took a little while to start getting crashes, so that was positive. It is expected at this point for it to be somewhat broken, we just needed to see if there were things we weren’t expecting (for the record, the first time we did this for the beta, it was a nightmare :D)
I’ve spent this last week on bugs:
- an issue with assets jumping when being picked up making tooling feel bad
- a crash when an asset is missing from the pack rather than using the dummy asset
- atmosphere not being correctly applied when joining the board
- fix sync of spaghet scripts
- get gm requests working again
- fix a bug where a scripted asset with no MeshRenderer freaked out my batcher
- an issue where static lights were not being invalidated on change
- fix an incorrect vertical offset of slabs that were elevated when copied
And then a stinker: Assets using our fake-translucency plastic shader don’t look correct with the new lighting system.
This thing has dogged me for days now. It’s on the critical path as this shader is fundamental to how TaleSpire looks and, more immediately, we can’t record the trailer until it’s fixed.
Here’s what the problem looks like:

It is happening because we had to write our own lighting to move tiles and props away from Unity’s GameObject system (because they were too slow). However, this means that a lot of lighting magic that Unity did for us is our problem instead.
Fire, for example, used to render in multiple steps.

First, the base object is rendered. Then it is rendered once for each nearby light, with the result being additively blended with the previous pass.
I had a look at the shaders to see how things were split up, and I figured that we could replicate the effect in a single pass if we could get the light data in a buffer along with some info on where in the buffer to find the lights for the current rendering asset.
But first I needed to make the shader. This took me a day and a fair bit of swearing (visuals are not my strong suit), but I did get a proof of concept working, enough to get back to the renderer.
This also proved to be a real pain in the ass. The batching code that collects light information was written to group lights of the same kind, regardless of what tile or prop they belong to. This is done to ensure that, when rendering, there are a few unnecessary state changes as possible. However, we now need the information grouped per-tile/prop and in a ComputeBuffer. Swearing and coding continued until I had a nice little allocator for the ComputeBuffer, and all the batching jobs were updated to use it.
Finally, we could port over the new shader and wire everything up.

At last! We have something looking correct.
We still need to wire up the changes to the other plastic shaders used for crystals and the like, but that is trivial now that we know the approach works.
Today I’m back on backend work, and I will be for the next week. This thing is shaping up fast now.
Seeya in the next one folks.
p.s. This dev-log is rather late so the next one will be coming very soon
TaleSpire Dev Log 259
Hi everyone!
Progress is excellent behind the scenes. Unfortunately for the dev-logs, my recent work hasn’t made for very interesting writeups.
My focus has been on and around the new board sync.
In TaleSpire, each change to the board is applied in the same order on all clients. Naturally, this means we need to start from a common state. So if you join a board after someone else, how do we catch up? We will need to fetch the board from the GM, but that is not enough as, in the time we are waiting for the board to transfer, the board could have changed. In the current build, we use the following approach:
- When you join the board, start recording all board change operations which arrive (each has an id)
- Ask the GM’s client for the board. The client will write the ID of the most recent board change operation that had been applied before the sync along with the board data.
- When the board is finally delivered, deserialize it and discard all the recorded board change operations with IDs older than the one in the board sync file.
- Apply the remaining board change operations in order
We now have a complication. Each client may only have a portion of the board locally. Ideally, we only want to sync the parts of the board that have changed this session and load the rest from the server. It took me a bit to work out that we should only need to pause applying changes if an operation intersects a zone that exists but is not local yet. We don’t need to do the same ‘id juggling’ as the former approach (although it’s still required for the parts coming from the GM).
Part of the above is about keeping info on what zones or sectors are loaded, modified, etc. I spent some time making sure we do this efficiently.
When we release this, we will need to upgrade all the boards that are already out there. We usually do this transparently on load; however, this time, the changes are so fundamental that I want to make it a dedicated step to reduce the chance for error. This means that once the update is out, players won’t be able to connect to a campaign until it has been upgraded by the campaign owner. The owner will simply have to click an update button and allow the process to run to completion[1].
I’ve added a new board format to my branch where I am putting the new logic, and I’ve started writing the system that will handle the update itself. This change touches so much code that I find myself jumping back and forth doing small parts on one system to allow progress in another.
As we are making changes to the board format again, I made sure all the tests were still passing. We don’t have a CI server, so these tests are run less frequently than they otherwise would be [0]
As I was working on the format, I decided to move board-wide settings like the water height and most recent atmosphere to the database. As I was implementing it, I got really annoyed at some poor JSON was for encoding the data, and, against my better judgment, I decided to spend the weekend on a little diversion.
That diversion was to implement binary messaging to the server. In previous posts, I had talked about experimenting with ERTS, erlang’s built-in binary format, and how I had already written some experimental code for making ERTS messages from C#. The plan was to update the code generator on the backend to support custom types in requests and replace the JSON serializer with ERTS.
This was going pretty well, it was tricky, but by late Sunday, I had the first messages set from TaleSpire to the backend. However, when I thought I had about an hour of work remaining, I spotted a critical issue.
I had wanted to use specific sized integers for certain parts of the message. When sending messages from C#, this was easy to control as it was my code. However, on the server, I used a method called term_to_binary, which is analogous to Json.Encode or similar from your favorite language. What that method helpfully does is to look at the value it’s encoding and pick a suitable encoding, which could be bigger or smaller than I needed[2].
This sucked. I didn’t want to handle those different possibilities on the client-side, but there wasn’t a way to control it on the server side without writing a custom ERTS encoder. Of course, that defeats the point of using ERTS as I wanted something to reduce the amount of work I needed to do.
Apparently, I refuse to pay heed to the sunken cost fallacy. If I were going to write an encoder, I would make something much less dynamic than ERTS that would make smaller messages. For example, there is no point in encoding the values’ types if the message has a fixed layout. And so that’s what the next 8 hours were — a dogged hammering at the keyboard until the format came to life.
So we now have our own format. Because it’s a binary format, the data is usually smaller than the equivalent JSON text representation, and writing the messages is simply pushing bytes into an array rather than conversion to a more human-readable format.
An awesome side-effect is that it’s now easy to add support for more types. For example, I added a dedicated UUID type that sends them in their usual 16byte representation rather than the 36 chars needed for the text version. Given how many UUIDs we pass up and down, this alone is a win.
I cannot stress enough how awesome erlang’s syntax is for handling binary data. It boggles my mind that low-level languages haven’t jumped to add something similar. For example, let’s start with 4 bytes of data in binary.
Data = <<255,255,255,255>>
Now let’s say we want to unpack 3 coordinates from those 4 bytes, where the X and Z coords are 11 bits, and the Y coord is 10:
<<X:11, Y:10, Z:11>> = Data
That is binary pattern matching in action. X is bound to the first 11 bites, Y to the next 10, etc.
Obviously, we often want to read out specific values where we care about endianness. Below we see how to read the first 20 bits as a little-endian integer and the final 12 bits as a big-endian integer.
<<X:20/little-integer, Y:12/big-integer>> = Data
The result from the above is X=2047, Y=1023, and Z = 2047.
You can also bind the rest of the data to a variable:
<<ArrayLen:16/little-unsigned-integer, RestOfTheData/bytes>> = SomeLargeBinary
The above binds a ushort to ArrayLen and the rest of the bytes in SomeLargeBinary to RestOfTheData. This made chaining patterns trivial and allowed me to make a tiny binary encode/decode library in no time.
So yeah, erlang is still a great choice :D
That’s enough for now. This week I’ll keep working on board sync.
See you around
p.s. Although I don’t write for other team members, there is plenty of cool stuff happening. Although we are not changing our release date from ‘Early 2021’ we are still on track for our own internal goals. TaleSpire is coming. The release is gonna be fun!
[0] Tests run with a specific build flag as we have to track additional data that we do not want in normal builds.
[1] The reason is that some data which used to live in the database (non-unique creatures) is moving to the board files and the board data, which used to be one file, is now many. I am nervous about an error or network failure resulting in partially updated boards, and so making it a big, dedicated step seems safest.
[2] I want to stress again that this is an excellent decision for how ERTS is used within erlang. It was just a failure on my part that led to this issue.
TaleSpire Dev Log 258
Hi folks!
Small update from me tonight.
After much wrestling with SQL quoting rules, I’ve got the partitions for board-data set up in the DB. I can now reserve an entry for a file, commit that once an upload has completed, insert the sector info into the correct place, and then query the board hierarchy to find out what files I need to pull for a given area of the board. To be clear, we aren’t uploading real per-sector data yet, but the database doesn’t know that :P.
With that looking promising, I started thinking about the upload/download managers again. To support resuming incomplete downloads, I knew I’d be using the HttpWebRequest API. However, I don’t have that much experience with it so, as an exercise, I rewrote the upload/download routines that we currently use when syncing the entire board. This was great as I didn’t get distracted overthinking the API or wondering how to get a realistic data-set. I could just use TaleSpire as it stands on our branch.
This went well, and now I feel ready to sink my teeth[0] into the real work of the managers.
One data-set I haven’t talked about much recently is the non-unique creatures. We want to remove their data from the database to support more of them, which means they need to be stored somewhere else. I’ll work out how I want this for the Early Access release, and then I can get coding.
Goodnight folks.
[0] No, not sync my teeth, and how dare you pun in this place.