From the Burrow
TaleSpire Dev Log 435
Good evening folks.
Today, I was looking into a really ugly slowdown when opening the “community” section of the asset library. I cracked open the profiler and, after poking around, found that calls to new Texture2D were insanely slow, easily 1ms each. I think it might be that either Unity is initializing the contents of the texture (which I’m immediately replacing) or can only make a certain number per frame.
The next version of Unity above the one we use does have an API call that allows making textures without initializing them, but the one we use doesn’t. I tried upgrading the project to that newer version on the off chance everything would just work, but no. Some APIs critical to TaleSpire have changed, and refactoring the code that relies on them is not trivial.
So, I need to decide on a different approach next. I could write some C++ to make the textures without initializing them and call that from Unity. And/or I could spread the texture creation over several frames. The first option is trickier than I’d like as I don’t think the conversion between Unity’s GraphicsFormat and DX11’s formats are documented anywhere (hopefully, I’m wrong; please leave a comment if you know!)
Before I could dig further into that, two things came up. One scheduled and one not.
The first was a very disappointing case. TaleSpire did not recover from a lost connection properly and lost 2 hours of someone’s work. This is terrible. So much of creation happens in the moment, and doing something for a second time is never quite the same. With our newer infrastructure, we now have much better logging, so we quickly tracked down the bug. What happened was that TaleSpire, at some point, lost connection to the backend (potentially due to a network issue.) Upon reconnection, we did not correctly re-register the ID of the board the player was working on. This put an invalid value into a temporary cache, which subsequently caused uploads to fail. The board was not destroyed, but the work for that session was lost. This bug has been around a long time, but now we’ve seen it, we know how to fix it. The first step is ensuring the server fails much sooner when it hits this case. That will cause the problem to manifest faster, and thus, the player won’t be able to spend hours making things that we then lose. The second step is to fix TaleSpire itself. On reconnection to the backend, we must ensure that the board-id is registered before allowing play to continue. We will have a fix for this soon.
The scheduled portion of the afternoon was a planning meeting. @Borodust and I sat down and sketched out the next few months of backend development. We also took some time to review previous decisions and talked over some recent process problems we’d like to correct. It was nice, which is not something you usually hear in meetings. Working in a tiny team on something we really want to see exist helps a lot.
And that’s all for today. I’ll be back with more fixes and dev-logs in the next week.
Hope you enjoy the weekend.
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire - Bug Month Patch 7
Hi again folks,
In this patch, we have a few tweaks and an experimental thing we’d like to hear your opinions on.
We have:
- Set 800x600 to be the smallest resolution pickable. This avoids a case where the window became so small you couldn’t change the resolution back again.
- Fixed the stats in the radial menu so that they update immediately if another player changes them (before you’d have to close and re-open the radial menu.
- Added result counts to community mod browser folders
Now, on to the experimental thing. As we all know, using the community mod browser needs work. The search is somewhat lacking, and the experience of finding creations is sub-par.
A big part of the answer will be tagging. We are bringing tags to creatures soon™ (we’ll have a dev-log on progress by Monday, and the tagging tool is going into internal testing on Tuesday), but in the meantime, I was wondering if there were any quick wins.
The search implementation is on mod.io’s end so we can’t tweak that. The current behaviour is such that if you search “Lord of the Rings” - it will return every result where the name contains any of the following words: ‘The’, ‘Lord’, ‘of’, ‘the’, ‘Rings’.
There is another option, though. They have an option[0] where you can use % as a wildcard. That means you could search fi%b% and get results with both “fireball” and “Firebird.”
So here is the question: Is that useful to any of you? It sounds like it could be, but in theory and in practice can be very different.
To that end, I’ve added it to the game so you can try it out. By default, the search is the same as before, and the wildcard symbol won’t work. However, if you start the search with a question mark, it will switch to the mode where you can use wildcards. For example, ?fi%b% matches “fireball” and “firebird” as mentioned above.
That’s it for today. We’ll be back soon with more fixes.
Ciao
BUILD-ID: 14543672 - Download Size: Win / Linux 4.9 MB / Mac OS 7.8 MB
[0] Fellow nerds might like to check out their api docs. The two places I think are most relevant are https://docs.mod.io/restapiref/?http#get-mods and https://docs.mod.io/restapiref/?http#filtering Do let us know if you find anything interesting!
Bug Month Patch 6
Today, we tackle a bug that has thwarted the pasting of certain kinds of slabs.
When a slab that combined thin tiles and props was copied, this bug made it impossible to place the slab back on the grid correctly. It would be misaligned.
The following shows the difference before and after this patch.
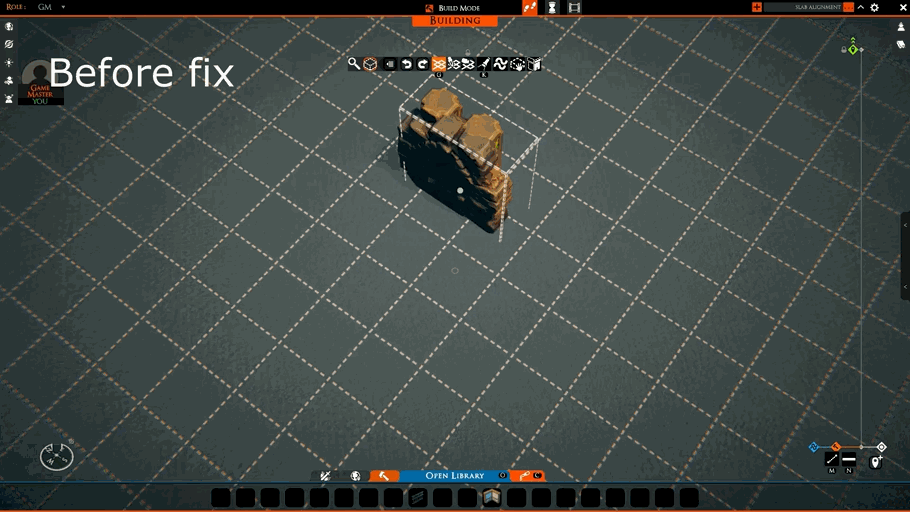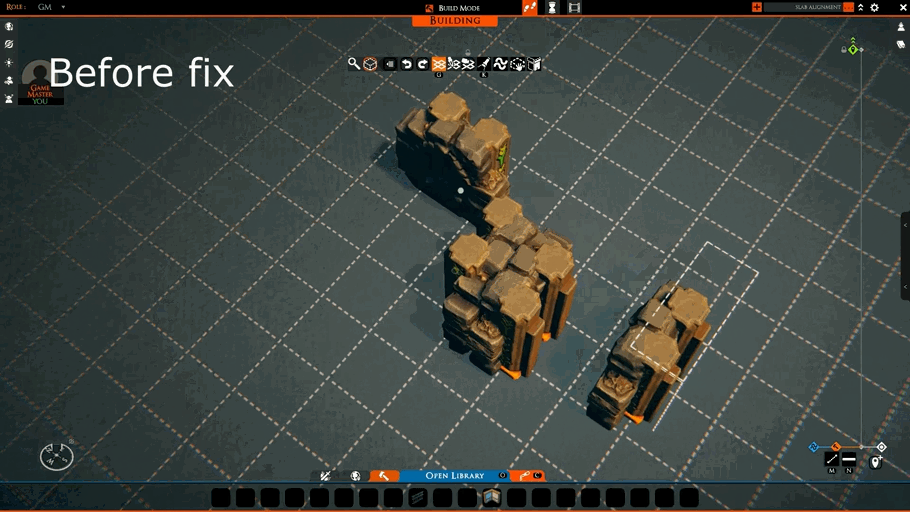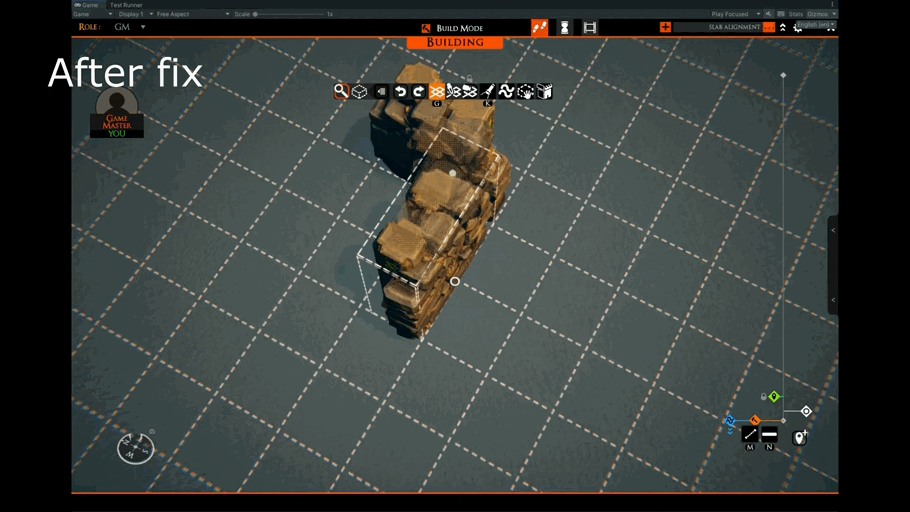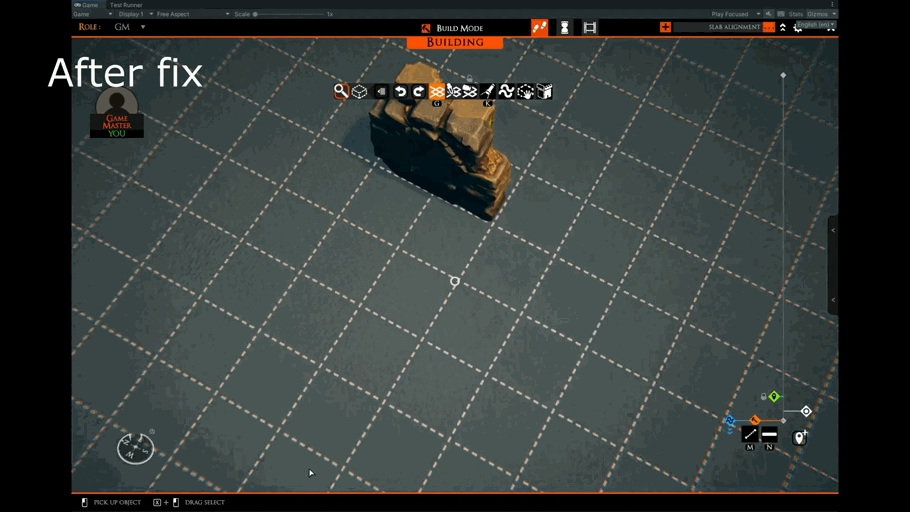
Along with this, we fixed a case where a malformed slab could put tiles in unsupported rotations. This also allows for some data optimizations later on.
That’s all for this today. We will be back on Monday with Seats and more fixes.
BUILD-ID: 14497681 - Download Size: Win / Linux 2.9 MB / Mac OS 6.7 MB
Ps. We are not going to make a habit of releasing on the weekend. This fix was going to ship on Thursday, but our main build server decided to freak out and mess up the end of our week. Remember, computers can hear you, and as soon as you announce a deadline they will do their damnedest to mess that up :p
Bug Month Patch 5
Hi again, we come bearing more fixes!
Today, we finally make sure that the creatures that have been knocked down show that state properly when placing.
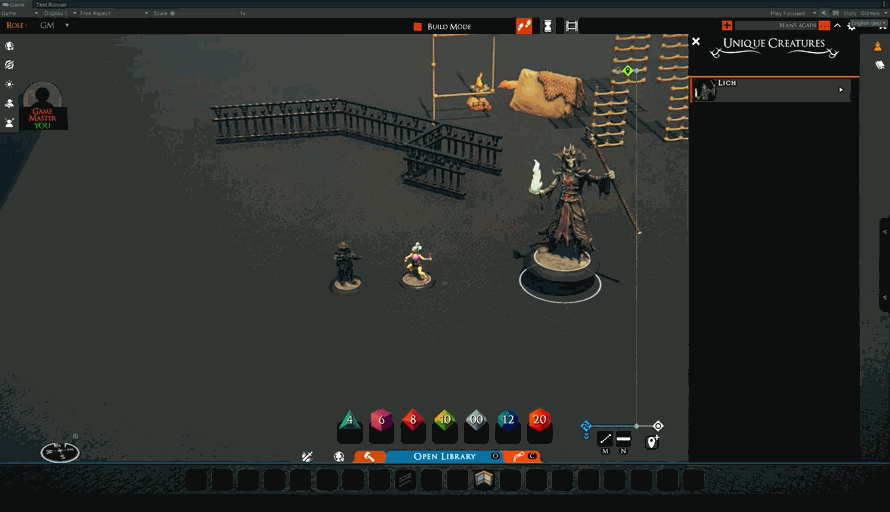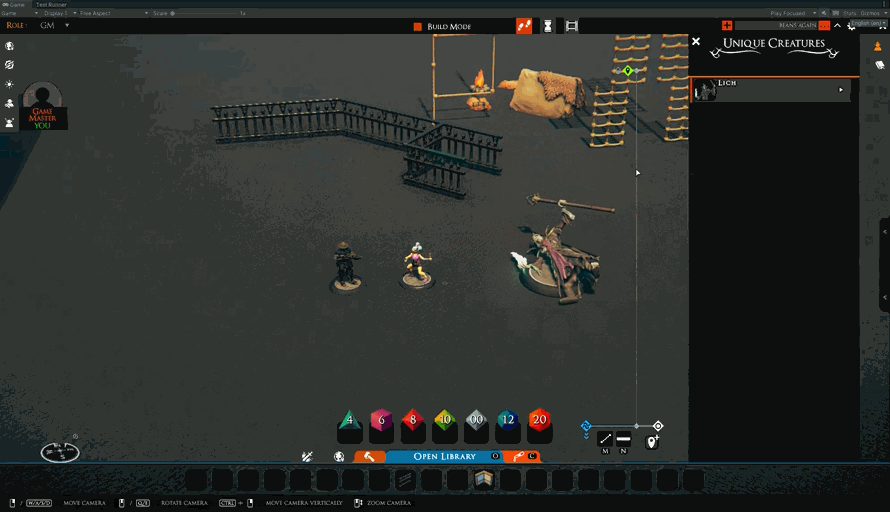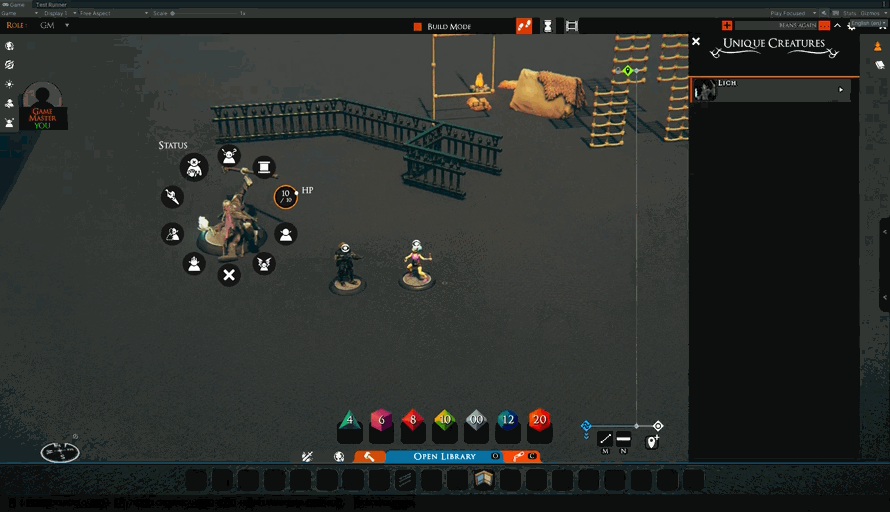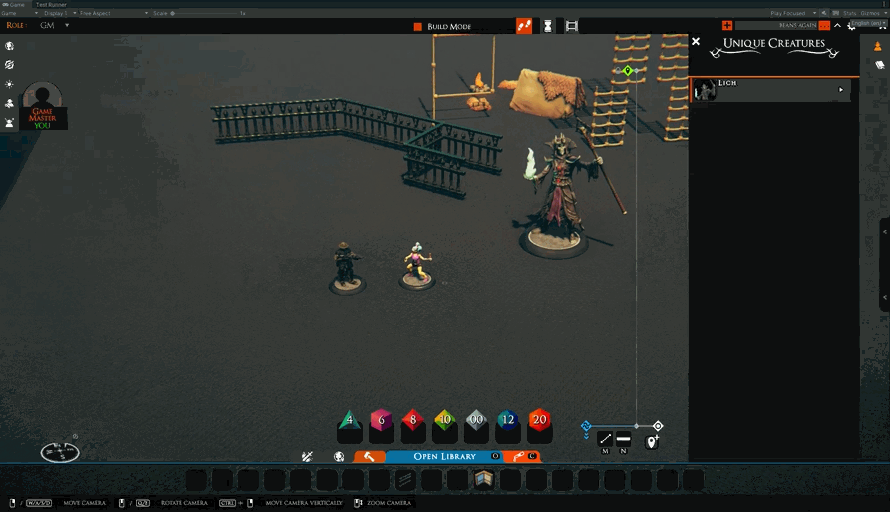
We also fixed the “rename campaign” dialog so that pressing the “return” key will apply the change in the same way as clicking the button does.
See you in the next patch.
BUILD-ID: 14451116 - Download Size: Win / Linux 7.1 MB / Mac OS 7.7 MB
Bug Month Patch 4
Fresh out of the national holidays, we have another patch. This one tackles the following:
- Entries in the unique-creature panel should be ordered alphabetically. Previous they would go out of order in certain situations
- Minor performance improvement: avoid re-sorting the unique-creature panel on every change to a unique (such as changing position)
- Fixed an issue where the first use of the ‘sample’ tool did not properly focus the entry in the asset browser.
The war on bugs continues next time, in bug month!
Bug Month Patch 3
Hi folks,
In this release, we are tackling a single bug.
TaleSpire would sometimes place the prop slightly lower than it should when using attachment points. This was cumulative, so over the length of a fence, each piece would be sunk slightly lower into the ground.

This patch fixes this, so subsidence is no longer on the menu!
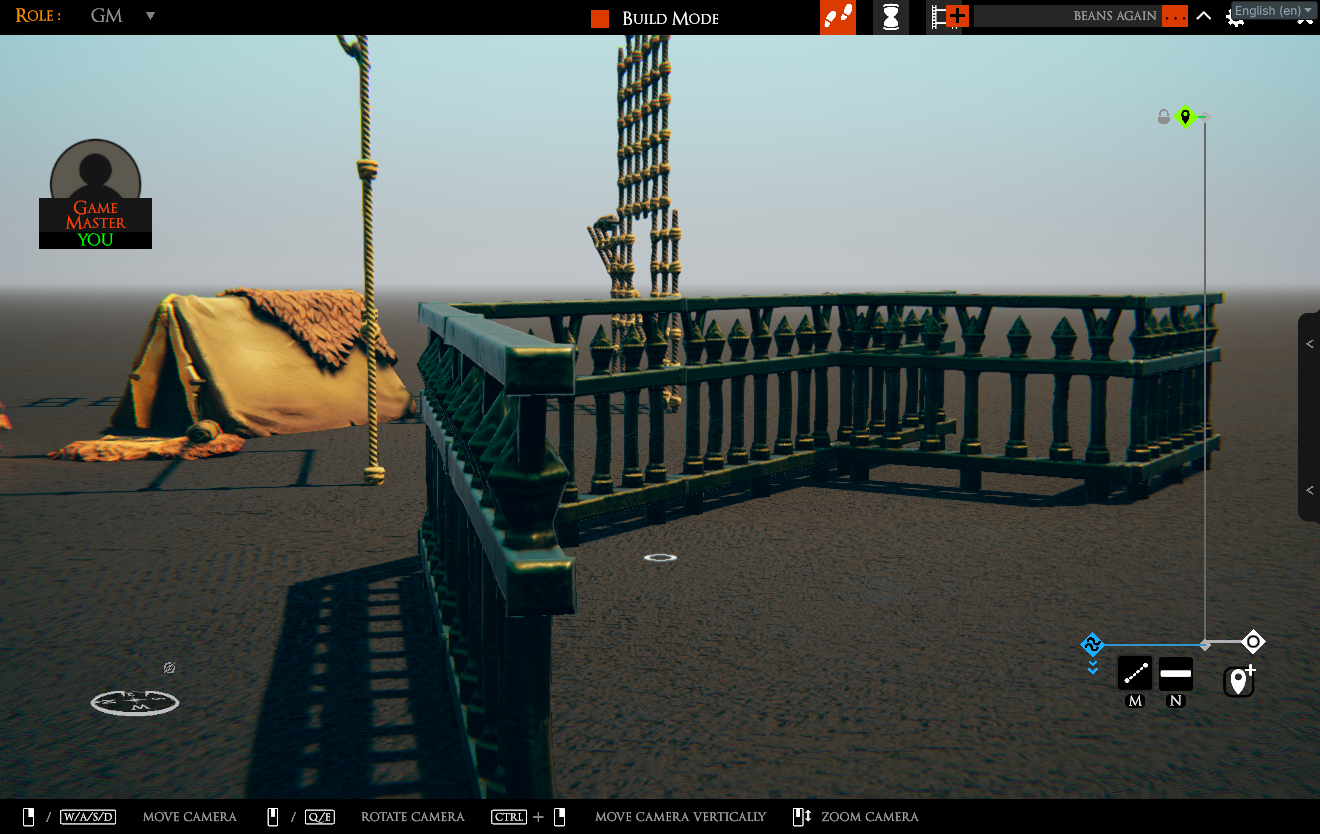
We will keep finding and fixing more annoyances like this throughout the month.
Until next time,
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 432 + Patch Release Notes
Heya folks,
Good news from Steam. They gave the “seats” feature the go-ahead. So now we continue setting up the production servers and getting ready for a release. I will get you the release date as soon as the team has had the next seats meeting.
So that’s great, and we also have another few bug fixes for you:
- We have fixed a case where returning to the main menu broke the build grid.
- We’ve fixed a potential issue with the “cut region” toggle not working right after returning to the main menu
- Updating a unique-creature’s position or values no longer collapses its entry in the unique-creature panel.
Have a great day!
BUILD-ID: 14359448 - Download Size: Win / Linux 2.8 MB / Mac OS 5.9 MB
TaleSpire Dev Log 431 + Patch Release Note
Heya folks, After much gnashing of teeth, the seat feature is in for review with Steam. Now we wait and fix anything they decide needs tweaking. We’ll let you know as soon as it’s through review and ready for release.
In the meantime, I want to get stuck in our long-awaited “Month of Bugs,” where I just try and fix as much random stuff as I can.
I can’t guarantee it’ll be the specific bugs that you most want to be squashed, but there will (finally) be some visible work from me after a few months of quiet grumbling.
We are kicking off with a little patch courtesy of @chairmander, who fixed these while administering the public bug-reporting site.
- Fixed a couple of cases where “Waiting on GM” was not updating to reflect changes in the player’s rights
- Fix a case where clicking on client-portrait was not focusing the active creature
- fix a couple of typos in an alert message and a tutorial
- fix a log message
Alrighty, I’ll get back to work. I hope you’re all having a successful day.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 430 - April Bi-monthly banter available on youtube
Yup, just a quick one to drop the recording of Friday’s stream. I hope you are all doing well.
p.s. As we mentioned the possibility of an additional dog on the next stream, here is a down payment on that:

Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 426
Heya folks, I hope the first week of the year is treating you well.
Things are going well over here. I feel well back into the swing of things now, so it is a good time for an update on what I’m doing.
Before Christmas, I had been pushing hard to get creature modding shipped, but clearly, I didn’t succeed. I thought I could hack around some of the tricky cases and get something made to see us through the holidays. If that had worked, my January would have been rewriting all the hacks into reasonable code.
As I failed to hit that target, I felt I had a couple of options.
- Continue the crunch and try and get the hacks to work. And then immediately rewrite them all.
- Just bite the bullet and do it more correctly, with the downside being that it would take more of January to do it.
I chose option two.
I chose that as my personal goal this year is to get better balance and organization in my life, something I have always struggled with. If I’m in doubt[0], I always find it easier just to work as I know what I’m doing with code as opposed to… well, everything else. But you can only do that for so long before cracks appear elsewhere.
This choice is feeling good for me so far.
That’s quite enough of the human meat issues; let’s talk technical stuff instead!
Content Addresses
Until now, most of the content you interact with in TaleSpire has been identified by a UUID. This gives us a (hopefully) globally unique identifier (name) for each creature, tile, prop, etc.
When you copy a slab, those IDs are included in the weird string that TaleSpire produces, and when you paste it back in, we use the IDs to find the data for the tiles/props/etc that you are pasting.
Now imagine how it will be with mods. A person may copy a slab with tiles or props made by the community or (soon) may be hosted on a repository that Bouncyrock does not control. How can TaleSpire find the data it needs only using the UUID from before?
There are a bunch of possibilities. One is that we could host a central address book that lets TaleSpire look up an ID and find the content pack and repository that contains it. This, however, means registering all content and IDs with use, centralizing information, and giving us too much power over creators. Instead, we are borrowing from the web and moving to URIs.
With the new scheme, every piece of content has a content-address:
Here is an example one: :46be6663d03843b6bb320a97716e5ace#72fbaa19-806d-4816-8d7f-91f17a459b93
Without the scheme, this identifies a piece of content named 72fbaa19-806d-4816-8d7f-91f17a459b93 in the internal content-pack 46be6663d03843b6bb320a97716e5ace (An internal content-pack is one that is shipped as part of the game)
The # is the start of a fragment, often used in URLs to point to some content within whatever thing the main part of the URL was pointing to. That’s precisely what we are doing, too.
Here is a different one: repo://talesbazaar.com/api/7d745de08e494e7ea7dce871519c09f0#d0bd95b7-0ef3-4144-a1ee-63aeedc93707
This doesn’t work yet, as we haven’t yet published the community repository REST API specification. But, once we do, a site like talestavern.com or talesbazaar could implement it, and then TaleSpire would be able to fetch content from places that are entirely out of our hands (We think this is critical for the longevity of TaleSpire).
- The
repo:scheme tells us it is a public repository. - The
talesbazaar.com/api/portion tells us the location of the endpoint (httpsis always used, so that doesn’t need to be specified in our URI). - The
7d745de08e494e7ea7dce871519c09f0is a hex-encoded content-pack ID. It’s not globally unique, but it will uniquely identify a pack in the repository - Once again, the fragment
d0bd95b7-0ef3-4144-a1ee-63aeedc93707is the UUID of the content inside the pack we are fetching.
We have other schemes for mod.io, HeroForge, and we are even tinkering with fetching content from arbitrary web addresses. This is proving useful for icons that are hosted separately from the content itself.
This is just example syntax, but I’m experimenting with URIs like this: web://some-site.com/some-place/some-image.png#64,64,32,32
In this case, the “content-pack” is an image at https://some-site.com/some-place/some-image.png, and the fragment identifies a region of the image that is then used as an icon.
Async everywhere
TaleSpire grew out of a simple, single-floor, dungeon-building, TTRPG-esque game. Initially, all of its content was built in, and there is still code that assumes some resources are immediately available. Over the years, we’ve been moving away from that as we tackled HeroForge and the community mod browser, but there is plenty of old code around.
As you can imagine, modding breaks all of that!
I won’t be able to fix all these old assumptions this time. I will leave some for when we add modding for Tiles and Props, but still, it’s a lot of work.
Each time I finish a feature like the mod browser, I think, “Ah, yeah, now we’ve got all the bits we need to make the real solution,” and each time, something else comes up. I’m sure there will be something else I need to handle. I’ll be sure to let you know when it happens!
Progress
All in all, though, it’s going well. In a game that is so much about displaying and navigating content, it’s no surprise that changing the fundamentals of how content is addressed, obtained, and loaded touches a significant portion of the project.
I’m working through hundreds of files and tens of thousands of lines of code and doing so carefully, as I never want to break anything you’ve been building.
I think I’ll be through the first wave of TaleSpire refactorings in a few days, and then I’ll move on to TaleWeaver, where there is a TON of work to do as the internal content-pack formats have completely changed.
I’m very optimistic, though, and I’ll keep you posted as it all quickly gets closer to release.
Man, this got so long, and I haven’t even talked about the ways we intern the URIs to make them fast to work with at runtime or any of the other stuff we are doing, but that will have to keep for another day.
Have a great night folks,
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] and I’m always in doubt :P