From the Burrow
TaleSpire Dev Log 228
Since our move away from GameObjects, we have had to make our own batching, culling, and animation systems. One that I had left for a while was lighting, so it was time to tackle that.
First off, the deeply annoying news. Unlike with the BatchRendererGroup, which gave us a way to avoid GameObjects and populate the data from multiple threads, there is no similar thing for lights. In fact, when I looked into Unity’s ECS, they were just spawning GameObjects for the lights and updating their transform each frame to be in line with the entities that supposedly contained them.
This is a pain, but it’s the only option, so we needed something similar.
As always, the fact that TaleSpire is a user-generated-content game means we have a bunch of complexity. We don’t know in advance how many lights are about to be spawned. Worse, because we are back using GameObjects, we know that spawning too many per frame will cause serious fps issues. This means we need a progressive spawning approach and pools for reusing light that that been destroyed.
Also, spaghet scripts are allowed to update light color, intensity, position, and rotation on a per-frame basis. Now position and rotation updates can be jobified if we put the light’s Transform in a TransformAccessArray. However, color and intensity can only be set from the main thread… joy >:[
On each change to a zone, we rebuild all the batches, including laying out the lights again. We have jobs to:
- find out what tiles and pros are using lights
- collate the numbers of each kind of light
- write the details for each instance of each kind of light (in parallel) into various collections.
We push all of the current lights back into the pools for reuse and, over the course of multiple frames, spawn new lights or pull them from the pools.
Dynamic lights are updated by Spaghet scripts. If there is a change to the intensity or color, we push the index of the modified light into a NativeQueue. That queue is consumed on the main thread where we can apply the changes.
Getting all of this to play nice has taken me the last 3-4 days. There is still plenty of room for improving performance, but I need to profile using real-world scenes before making any more changes. Luckily we have fantastic community sites full of slabs I can use :D
Alright, the next stop is looking at little things that broke on the move to the new physics engine.
Seeya in the next log (which will hopefully take much less than a week this time :P)
TaleSpire Dev Log 227
This one is interesting to write as it’s fairly downbeat. However, it is part and parcel of making stuff, so let’s do it.
As mentioned in previous posts, we have known for a while that TaleSpire would not scale to bigger boards using their GameObject abstraction. There was a lot of song and dance from Unity about their upcoming ECS, and while it looked pretty promising, we miscalculated the timeframe it would take Unity to bring it to life. That meant that this year, as we tested again, we saw we needed a custom solution. That’s what I’ve been working on.
Now I have tried hard to always be clear about when the issues we have run into have been Unity’s fault and when they have been ours. In general, the responsibilities have been ours as we are using packages marked experimental and not in general recommended for shipping. However, today’s principal issue is, I believe, not on us.
To move away from using GameObjects we have been building on the BatchRendererGroup. This object lets you specify what needs to be drawn and then provide the matrices to lay these instances out in world-space. The matrix array you fill is a NativeArray and, as such, is fully compatible with the job system[0]. This meant that we have been able to parallelize the population of these arrays, which has resulted in the massive improvements in the performance spawning tiles we have seen in previous dev-logs.
When you are using instanced rendering, you need to somehow get the per-instance data to your shaders. Traditionally in Unity, this is done using MaterialPropertyBlocks. You can associate a MaterialPropertyBlock with an object and, when it renders, that data is made available to your shader. When using BatchRendererGroup, this requirement seems to be filled by using GetBatchVectorArray (and co).
Now here is my portion of the fuckup. When I couldn’t get this to work in my early testing, I put it down to me not being too hot with Unity’s shaders, and that I would work it out later. Unlike the new stuff in Unity, the BatchRendererGroup is not marked as experimental as so I had the same confidence in the system that I do for other released parts of Unity. I put a few questions up on the forums and got back to work[1]. I rigged up a simple system where I looked up the data from ComputeBuffers using the instance-id as the index; this works fine without culling enabled[2].
The problem is that GetBatchVectorArray does not (as far as I can tell) work with the classic rendering system in Unity. This is not stated in the documentation, but in the docs for an experimental package called the ‘Hybrid Renderer,’ it mentions some things that can be construed to mean it only works with the new scriptable rendering pipelines.
UPDATE: While writing this log, I’ve seen that my bug report against this method has been accepted. I will keep you posted on how this goes.
This sucks. Worse, we know the old version won’t work; we are months into the rewrite with no way to go back. Frankly, it was rather distressing.
Now those of you who know a little about Unity might be wondering if we could just make something custom using DrawMeshInstanced or DrawMeshInstancedIndirect. The problem is that things drawn with those methods are not culled, and this is a problem as realtime lights/shadows require rendering the scene from multiple vantage points. Without culling, you end up rendering everything for each camera regardless of the direction it’s facing. This massively hurts performance. The BatchRendererGroup was excellent in this regard as it allowed us to implement the culling jobs ourselves.
One thing that the BatchRendererGroup does have is a flag that lets you specify that you only want to use it to render shadows. Another little detail is that TaleSpire’s shadows don’t need to respond to the tile drop-in/out animation we implement in the vertex shader. This gives us the possibility to keep using the BatchRendererGroup for shadows and keep the culling advantages.
However, that still leaves actually drawing the scene. The only thing I could think of was that I’d need to implement this myself. I’d use all the batching code we have written to layout data on the GPU, I’d write a GPU-frustum culling implementation that matched the one we use on the CPU side, and use DrawMeshInstancedIndirect to dispatch the draw calls.
Now I’ve never written this kind of thing before, but it felt like the only feasible option. Over a few days, I got this written and was finally able to cull our scenes again without horrible flickering.
Now the scary thing is that this was not part of the plan. It’s cost us a lot of time and how it scales is currently unknown. What I do know is now we have a whole pile of extra complexity to manage and improve. Not great.
However, there are some up-sides:
Currently, we have to use the same meshes for rendering, occlusion checks, and shadow rendering. I wanted to use different meshes for shadows and occlusion checks as this allows us to use lower-poly meshes (helping performance) and close tiny cracks the fog of war shouldn’t be able to see through. I was implementing that as part of the GPU-occlusion system. When I delayed that feature to after the Early Access release, we delayed the ‘separate shadow mesh’ feature too. With our new system, we can trivially use different meshes, so these improvements are now on the cards for Early Access.
As mentioned recently, most of Unity’s API has a max of 500 instances per batch when using non-uniform scaling. DrawMeshInstancedIndirect does not as all the data is already on the GPU. This means we have the potential to have much larger batch sizes. Currently, we batch on a per-zone basis, so we are a little limited, but it will not be hard to take zones that have not changed in a while and combine their batches. It’s something I’ll look into when I get back to improving performance.
Thirdly, we now have a bunch of tile/prop data on the GPU that we can easily write compute-shaders to operate on. This gives us more options for future developments.
So all in all, this has been pretty horrible. I’m very grateful that the community is so supportive and that the Eldritch Foundry update was so well received. That was a serious boost in a tough couple of weeks.
However, we are still very far from done. By my estimates, I was at least a month behind my personal goals before this escapade, so I’m not sure where we are now. Luckily we’ve been vague with deadlines, but we will need to sit down and look at the plan again.
What a year!
This dev log is long, so I’m gonna leave talking about lighting to the next post.
Seeya there
[0] This is important as, traditionally, most of Unity’ apis are only valid to call from the main thread.
[1] There is such a lot of work to do for Early Access that often I can’t afford to stress on issues that can be worked out another day. The important thing is to be making progress somewhere as often another day I’ll have had time for the solution to come to me.
[2] Culling means some instances are not being drawn and so the instance-id for a given tile can be different from frame to frame.
TaleSpire Dev Log 226
A quick tip when dealing with BatchRendererGroup. The instance limit per batch is 1023, but the UNITY_INSTANCED_ARRAY_SIZE limitation still applies[0], and so on desktops, this will likely cut your max batch size down to 500. This matters if you rely on instance-ids. I saw some very odd stuff when a single batch went over 511 instances; what was happening was that Unity was splitting the batch in two, one for the first 511 instances and one for the last one. This meant the instance-id for the 512th instance was 0 rather than 511, and this naturally resulted in incorrect behavior when using it to index into a buffer.
That was an afternoon of pain explained after a quick trip to the frame profiler, I was so concerned that my batching code was wrong that I didn’t consider the instance-ids not being what I expected. I can’t wait to know more of Unity’s internals as these issues are such a pain and seem avoidable.
Another node that I added last week is the random node. It can produce random floats, int, and vectors of each. It uses a simple stateless random function I’ve used in shaders before, which means it would be terrible for security, but is perfectly fine for visuals. The node has an option called ‘Update Mode’ that might be worth mentioning.
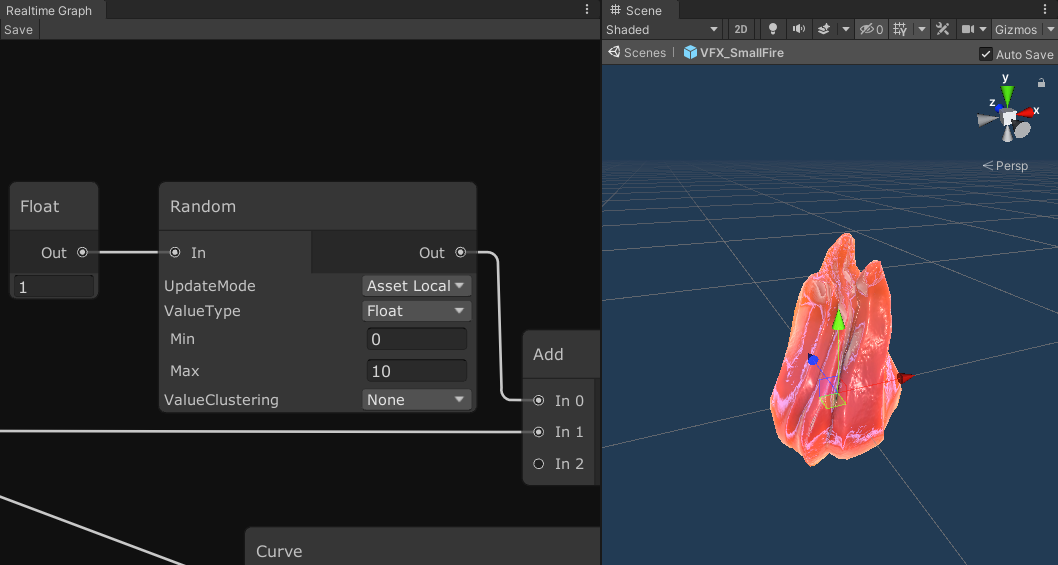
By default, if you give the node the same input (the seed), you are going to get the same result on the output. You will probably feed time into the input to get different results each frame. However, if you are using global time, then the output will be the same for all instances of this script running on all assets this frame. That might not be what you are going for! This is where the ‘Update Mode’ comes into play. You can set it to global, which gives the behavior described above, or you can pick one of two ‘local’ options, which both modify the seed in a way that will give different results. The ‘Local’ option means that it mixes in the tile’s unique id, so now the result will be different from other tiles running the same script. Note, though, that each asset within a tile can have a script, and maybe you don’t want those assets to get the same result from the same node. To handle this case, you have ‘Asset Local’, which also mixes the asset’s index into the seed along with the tile’s id.
Alright, back to work. Seeya!
[0] Unity’s use of constant-buffers for its object-to/from-world matrices and constant-buffers have a max guaranteed size of 65k. See section 1.4 over here for some interesting details.
TaleSpire Dev Log 225
Hey folks. For the last few days, I’ve been looking at batching again. Unity has an interesting limitation in that the max batch size is 1023. This seems to be an artifact of some decision long ago, however, we need to make sure we don’t try and make batches bigger than this. Making our code respect this is a delicate operation as it’s very multi-threaded code and the access to the data are often not protected by Unity’s safety systems (for performance reasons). This means I’ve been taking it very slowly, it’s going well, and I hope to have it finished soon.
As that is quite a short update, here is something from last week.
There is a node in Spaghet for choosing a mesh from a list. We use this for the stop-motion style effect of the fire. It looks like this in the graph.
{kind=link}
While fixing bugs in the implementation, I had to fix things both on the TaleWeaver and TaleSpire sides, and the process got very tedious. At some point, I decided to re-prioritize work on the modding tools and hooked up Spaghet such that it works as a live previous in TaleWeaver. Here it is in action. Notice that every time we save, the changes are immediately applied.
This sped up the process a lot! I was able to find some mistakes in my animation packing code and fix those before getting back to batching.
Alright, that’s the lot for this update.
Peace.
TaleSpire Dev Log 224
Hi everyone, last week was intense but productive. I’ve been down at Ree & Heckbo’s place, working on the engine. We had hoped to start integrating our branches, but my stuff still was not ready, so instead, we just kept working, making use of the collaboration advantages that being in the same room gives.
As there has been a bunch of stuff happening, I’m gonna spread it over a few posts.
Let’s start with something random: line-of-sight.
Line of sight checks came up in conversation in the community recently. The issue was that people have issues because one creature can block the line of sight to other creatures behind it. This is one of those things that sounds like it makes sense but just doesn’t feel right in-game. Any gaming using miniatures is always an approximation of the fantasy setting, and so sticking to it like it represented reality often doesn’t make sense.
Let’s take a concrete example. A giant is blocking the view to a goblin behind its leg. This sounds fine, but imagine the scene as it would play out in ‘real-life’. The giant would be towering above you, and as it walks, you catch glimpses of the goblin as it darts about trying to get a shot on your comrades. This fidelity is lost if we treat the table as ground truth.
Instead, it’s better to ignore iter-creature relationships when checking line-of-sight.
This poses a minor implementation issue that is worth exploring. Back in the alpha, we checked line-of-sight using collision rays. This worked, but it was inaccurate as you can only perform so many checks per frame. Back then, we checked less than 10 positions per creature, and both false positives and negatives were common. People rightly asked for a more accurate line of sight.
In response, we changed the approach to rendering the whole scene from the creature in question’s perspective. We rendered tiles and creatures into a cubemap using colors as IDs. We then used compute shaders to gather the results and report back what colors (and thus creatures) we visible. As you can see, this introduces the issue that any creature that is entirely obscured by another creature will be considered invisible.
To fix this limitation, we are going to need something new. The idea is to render the scene without creatures into the cubemap, then we will render all the creatures, but they will not write their depths (in-fact, we will probably discard all their fragments). This means that we should get a fragment shader call for every fragment in each creature that isn’t discarded by depth. We can then write the visibility info from the fragment shader into the result buffer, hopefully giving us the data we need.
This will also help fog-of-war, which uses the same visibility cubemap. (more on fog-of-war another day).
I’m gonna jump back into code now, more dev-logs coming when I take breaks!
Ciao
TaleSpire Dev Log 222
Heya folks.
Ree has been working full steam on the flying mechanic, and it’s looking pretty damn nice. You should get your hands on it very-soon™ if all goes well.
Work on assets has been going well too. We have some good stuff we hope to show there soon-ish also.
Before the weekend, I tried to get more dice working. However, the D12 was spinning relentlessly, so I just put that down for a bit. I feel like we are past the big hurdles with that part of the physics integration, so it should be a case of just hunting down those issues.
I also started on porting the animated fire to the new system. This requires some relatively simple changes to the batcher but also means we need to recreate some scripts in spaghet. Here is the noodly goodness as it stands now.
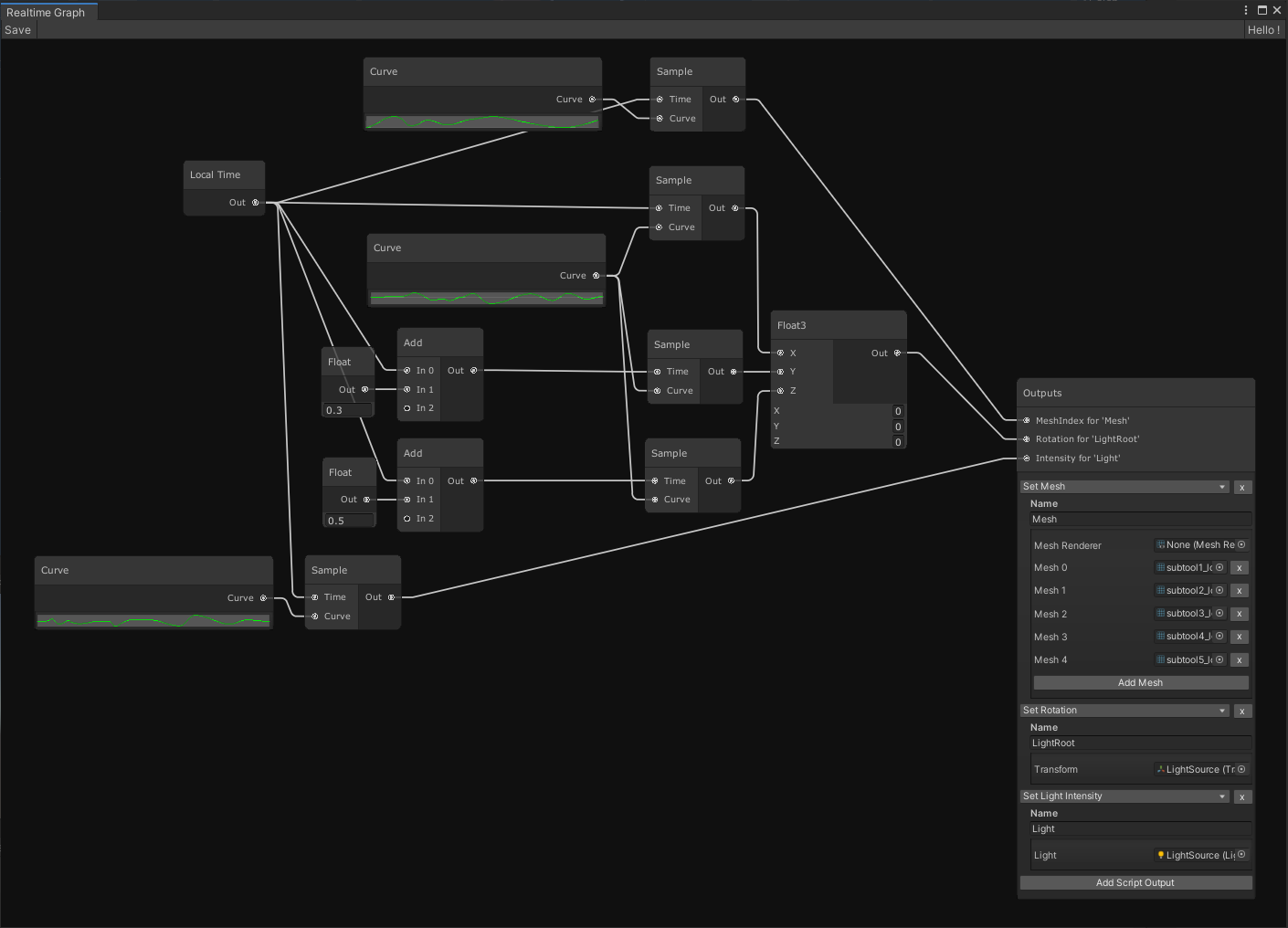
This will definitely be cleaner when we support collapsing subgraphs into function-nodes, but it’s not too bad even now. We are sampling a few curves in order to:
- pick the active mesh
- rotate the object which holds the light
- adjust the light’s intensity
For the curious, this compiles down to a short sequence of operations.
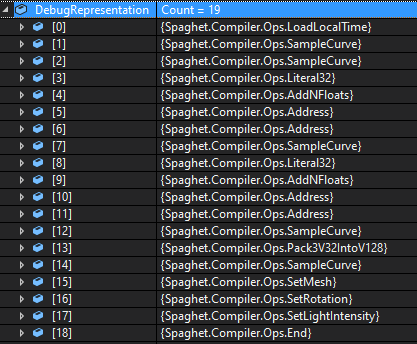
I still need to switch from local time to global time and add a random-number node to add some timing variation between each fire instance. I believe I still need to do a little work to handle some cross-frame state, but this hopefully won’t throw any spanners in the works.
Tomorrow I’ll pick up where I left off and try to get this lot running in TaleSpire. Except for lights, which are their own can of worms.
Seeya then.
TaleSpire Dev Log 221
Hi everyone,
Integrating the new physics engine is going well. I wrote a component that converts old-style colliders and rigid-bodies into the new style.
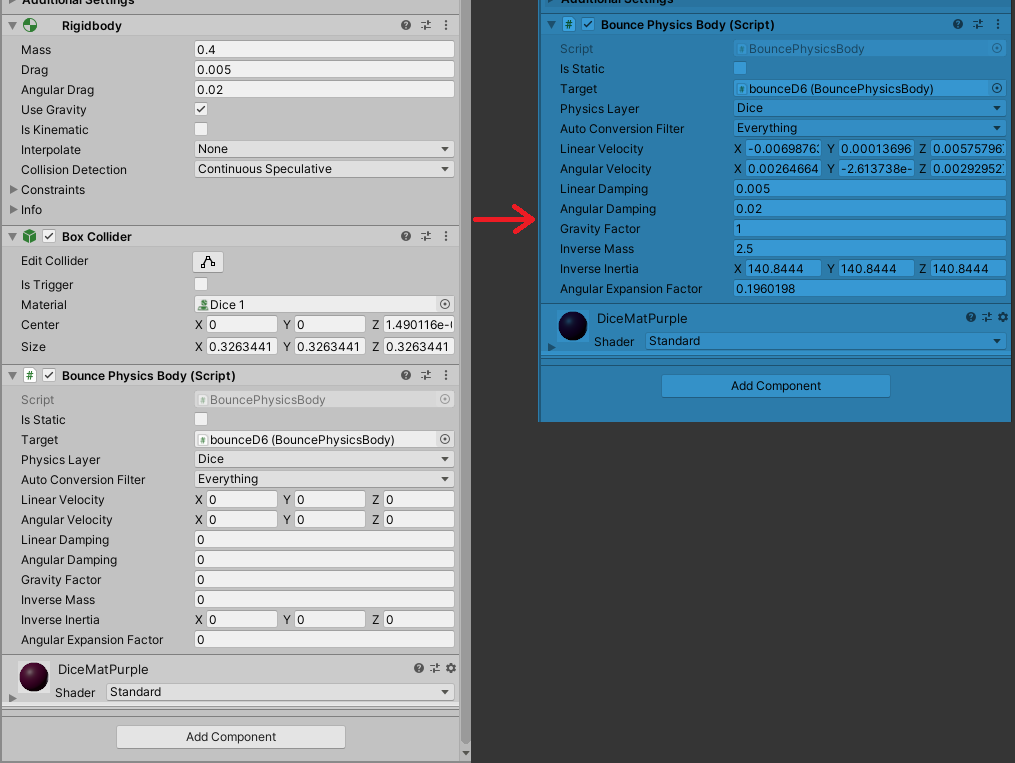
Sorry about the weird colors here. Unity today decided that I last renewed my license tomorrow (yup), and so right now, it thinks I’m unlicensed and gave me the light editor theme[0]. The blue tint on the righthand-side lets me know when I’m in play mode, which is super helpful. It looks a lot less baby-blue when used with the dark theme :P
I’ll pretty the UI up in time. For now, seeing everything is helpful.
It took me a while to work out where to get some mass related values right, so the dice rolled strangely, but now it’s a little better.

Behind the scenes, a lot is going on, not least of which is that the physics is running with a fixed-timestep. This shouldn’t be a big deal as a fixed-timestep is mandatory for stable physics across framerates. However, this is not fully supported in Unity’s ECS, so I was concerned that it would be difficult.
Luckily for us, it was not[1]. The physics engine is pretty great at giving you control, so I loop running the simulation for the required number of steps. If you have read about fixed-timestep before[2] you’ll know that you need to interpolate the results as the final step. The physics engine doesn’t have that support for that out of the box, so we added a job to collect that information and apply it as we write the transforms back to the GameObjects.
With that done, I need to replicate the parts of the old physics API that we use. If I can get dice rolls working again then I should have replaced most of what we need.
Have a good one folks, Peace.
[0] yup I do know about the latest version making the dark theme free, but upgrading is risky and we are on a tight schedule right now.
[1] The interpolation is not hard, but the Unity folks have a lot more to support that we do, so we get to only handle the simpler case.
[2] The best known fixed-timestep explanation can be found over here. It’s a good one.
TaleSpire Dev Log 220
Phew, a few days away from the dev-log there. I got really caught up in some changes that were a real grind.
I’ve been working on the behavior of uncommitted changes. This work is taxing as you have a matrix of different states tiles might be in. Let’s take redo of delete for an example.
- You might be redoing an undo which has been committed
- You might be redoing an undo which has not yet been committed but the delete action it undoes has been committed
- You might be redoing an undo where neither the undo nor redo have been committed yet
And that’s one action in isolation. What about the delete of assets which were made by undoing a separate delete. The matrix of possibilities applies to all the actions involved in that sentence too. In short, making sure you get a reasonable result takes a lot of concentration (and bizarre diagrams :D ).
When I finally got it running locally well, I connected up a second client and immediately disaster. The result was very wrong. I’ll admit I started panic sweating at that point. Last time this happened, we had to delay the Beta. Luckily this time, the system is much simpler, and I have an extensive test suite to lean on.
I dusted off the tests (I may have neglected them for a while) and started digging into issues. The great news was that, whilst the tests did find a couple of bugs in the new code, the underlying board code was still working fine.
This helped me relax and focused my attention back into the code that handles the batching of uncommitted tiles. After some time in the debugger, I finally spotted a case where tiles were not removed from the uncommitted state when committed. This amounted to a constant being 1 instead of -1. With that typo fixed, it started behaving rather well.
With that terrifying detour done, I needed to get back into physics. I have had to write a lot of the physics code fairly reactively rather than with a solid plan, and so I hit the point where I needed to clean things up. This sucked. It was a painful combination of being very tedious but also critical to get right. Some days are just like this.
These last weeks I’ve really been feeling the pain of not being able to just rely on the game-engine in the ways we usually do. Because of our bad estimate of when Unity’s new ECS would be ready, we are having to make a lot of systems ourselves. This is fine in theory (I love making stuff), but it’s meant losing at least a month of dev time that we did not expect. That’s always difficult, but our timeline was already tight. It’s pretty stressful.
Anyway, panic/rant aside, things are progressing. The thing on my plate now is hooking regular Unity GameObjects into our physics setup. We need something that takes current-gen Unity Physics components and makes equivalents in a format suitable for their new physics engine. We can then write some code to manage copying the values to and from the new physics engine to keep it all in sync.
If all that goes well then hopefully I’ll be rolling dice again soon!
Thanks for stopping by folks,
Seeya in the next dev-log
TaleSpire Dev Log 219
Today has been spent working on the behavior of uncommitted action.
Whenever you add or delete tiles, we need to perform the action on the other players’ boards. To get the right result, the actions need to be applied in the correct order. This is done by sending all of these actions to a player, which was automatically designated as the ‘host’. They then relay the action to everyone, which gives us an order. We call an action which has been given an order a ‘committed action’.
Given that we can only apply the actions once they have been committed, we are in this annoying position where we need to wait for that roundtrip before we see a change from our keyboard/mouse click. That feels bad[0], so we needed to do something about it. By the time of the beta, we had made a system that could update the board’s visuals for our uncommitted changes so that the change looked immediate. It was complicated, but it was made much more so by the fact that we had to spread some changes over many frames due to Unity not being able to keep up with spawning without impacting frame-rate.
Now that we have taken control of batching, we can happily spawn thousands of tiles a frame with no issues, and this lets us drop the performance workarounds. I’m now rewriting the code that handles applying visual changes for uncommitted actions.
It’s going pretty well. I have uncommitted actions working for adding tiles and undo/redo of the same. I have made good progress on delete and, although it’s significantly more complicated, I’m pretty confident I’ll have it working tomorrow. If I can get this done in two days, that’ll be pretty great as the last version took months to get right. [1]
As soon as this is behaving, I will be switching back to physics. The first task is to make the ground a physics object again, and then I will be looking at dice. I hope to have some familiar dice rolling gifs by Monday :)
Hope this finds you well folks.
Peace
[0] It might seem like not a big deal, but we had complaints about the responsiveness of undo/redo in the alpha, and back then, that delay was mostly due to performing the action on key-up rather than key-down. Input latency really matters.
[1] Of course, it’s not an apples-to-apples comparison as the codebase is already structured in a way where this would be possible. However, it definitely feels much simpler.
TaleSpire Dev Log 218
Heya folks,
Today I started out looking at the slab code again. The slab is the way we refer to a section fo tiles that have been copied. When you paste a slab string, that slab appears in your ‘hand’ in-game, and you can place it like a tile.
Recently we have been writing batching code, something that used to be handled by Unity. It got to the point where I needed something similar for the slabs, which I started yesterday. There are a couple of differences from the standard code batching code:
- We don’t want physics to be set up for the tiles/props
- We don’t want scripts to start running
- We need to update the position of every object in the slab every frame (as the player moves it)
This mainly involved taking the existing code, taking a chainsaw to the parts we didn’t need, and stitching together the remains. It’s still very rough, but I was able to try pasting in the slabs from the community… which of course crashed the game :P It was obviously not the fault of the community content, it was that it was a much more complete test that I had run up until then and it found a few bugs. One was a case where we had assets in TaleWeaver with a MeshFilter with no mesh specified. Another was that I hadn’t written the code to handle missing assets.
I got the code to the point that I could paste a slab. However, it feels pretty rough as the ground plane in the game doesn’t exist in the new physics system yet. I’ll be back working on the physics code soon, and then I can take another crack at this.
The rest of today has been spent looking into building code. I need to re-implement the stuff that handles things that have been affected by changes that have not yet been committed (confirmed by the host). It’s pretty hard going, but I’m hopeful I can make some decent progress this week.
I’ll leave ya with a view from the cabin one of our friends were kind enough to invite us along to over the weekend,
Ciao
