From the Burrow
TaleSpire Dev Daily 13
Another short update for today. I got the fog of war logic mostly hooked up but in a very dissatisfying ugly way. The job for tomorrow is to try and wrangle it into a more sensible form and then start testing and tweaking the fill.
The tiles are being revealed now but as we are replacing some parts of the projects others are pretty broken. An example side effect is that right now you can walk through hidden walls. This ends up being rather demoralizing as the harder you work the more broken things get. Of course the logic part of the brain knows we have done this shit plenty of times before and in a few days it’ll be good again, just gotta keep grinding :)
Until next time
Ciao
TaleSpire Dev Daily 12
Today has been spent replacing the old fog of war with the new code. This code has paths from and through many other systems so it feels like I’ve been pulling on threads to see what moves and then unweaving them.. flashbacks to running network cables in an old job :p
Like yesterday I don’t have solid stuff to show but it feels like it’s getting close. Tomorrow will start with testing followed by hooking the level loading into the fog of war stuff. This either means having each loaded asset write add themselves to the zone’s octree or (much more likely) we just serialize the octrees.
I also need to look into which zones are updated per frame. For a huge map you don’t want some zone a mile away updating things that don’t matter.
Thanks for stopping by, seeya next time
TaleSpire Dev Daily 11
Today I needed to take a little time to be a human so less coding was done.
Before that I did get flood fill working across subsections of the board (zones). The next task is storing the results for the given character and being able to switch between different character’s perception.
Those successes only appear as a couple of messages in the log right now, so instead here is a visualization of the octrees of different zones as the character moves through them
Peace
TaleSpire Dev Daily 10
I got less done than I’d hoped today but that’s alright. We had to plan out some finer details of how the fog of war should behave under different conditions and required a few changes in how we are storing places the character has already revealed.
I’ve hacked out the data structure for this and am writing on the worker that will run the flood fills.
Not really much more to say right now,
ciao
TaleSpire Dev Daily 9
I like these days. These days I get to give good news. And today’s news is that the constrained flood fill works!
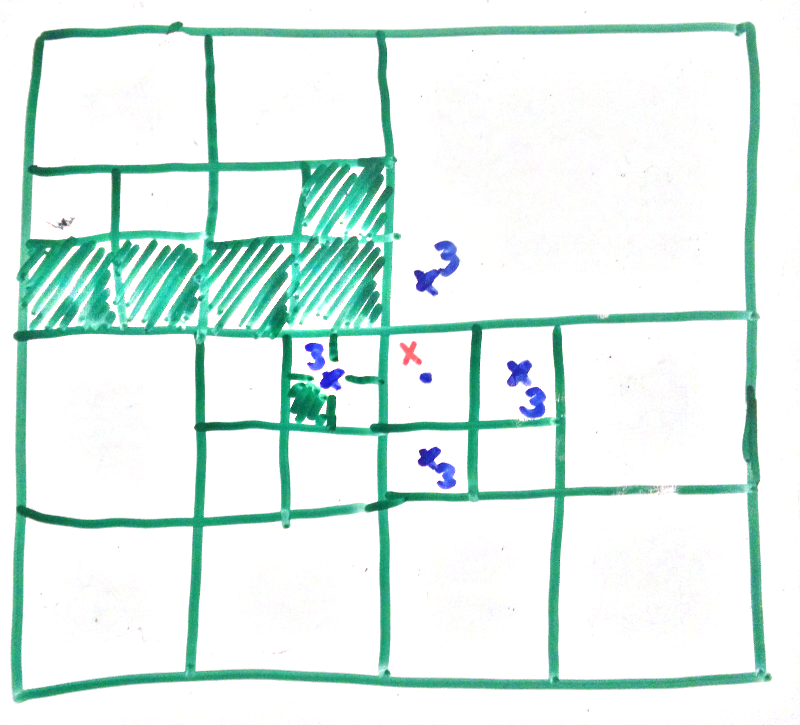
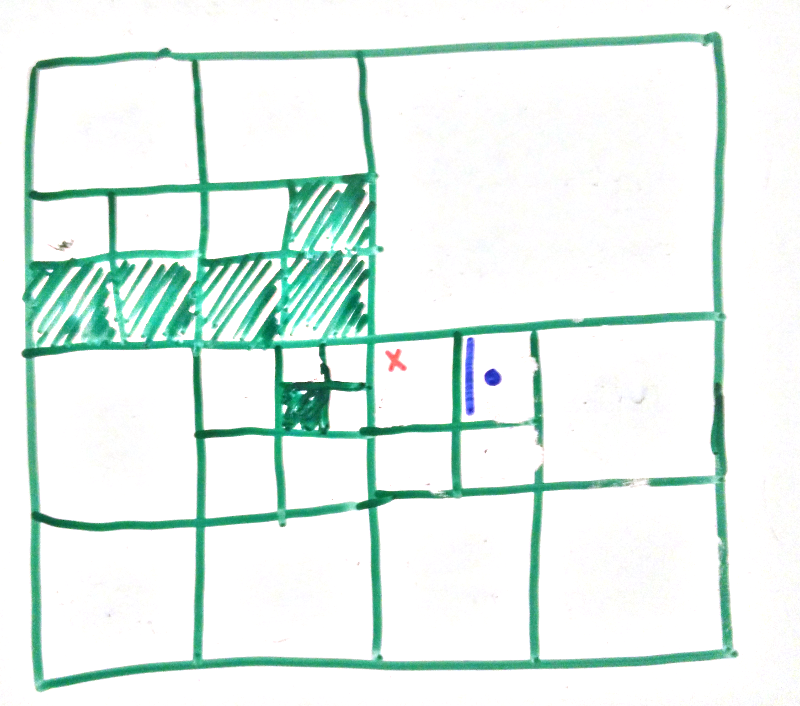
Let’s start with the pictures. In the next picture the white areas are all the fog of war we want to reveal if the character was at the red crosses. We can see that it hasn’t flowed into the blocked off room (even though the search does work vertically) as we have told it not to search above the eyeline of the character.
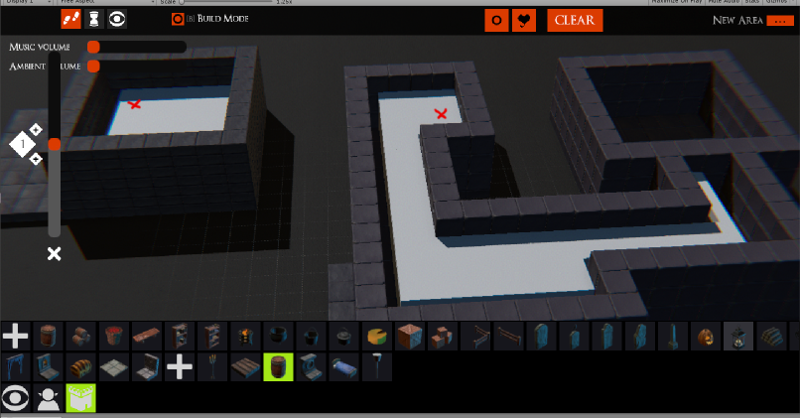
We can see this more clearly for this scene

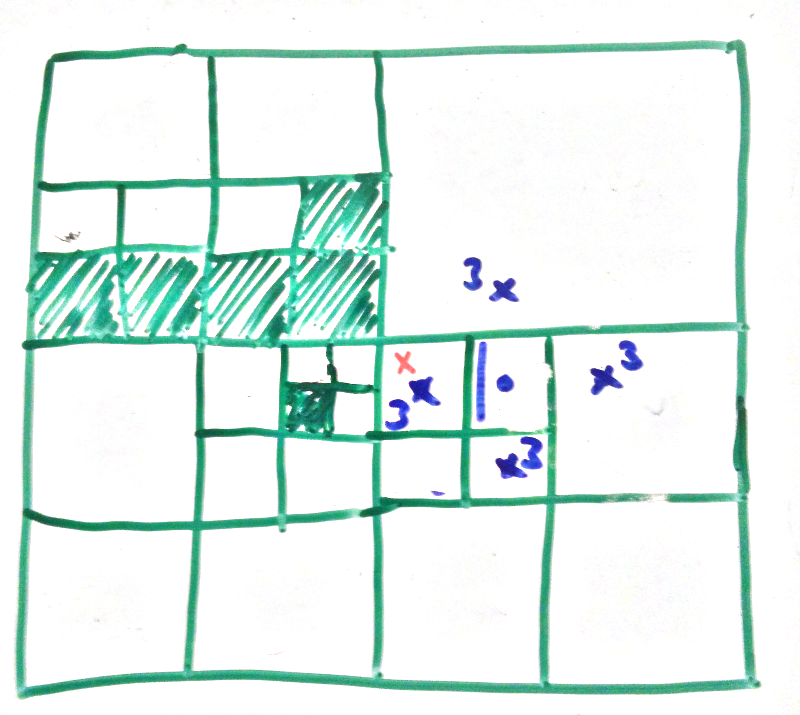
If we search from the green cross we get
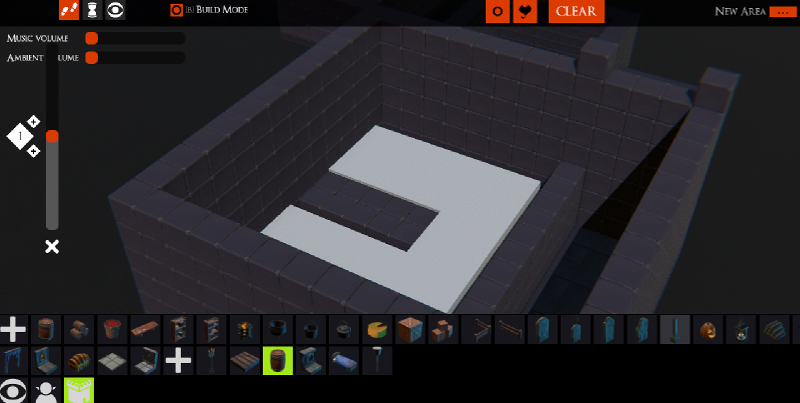
And from the red cross we get
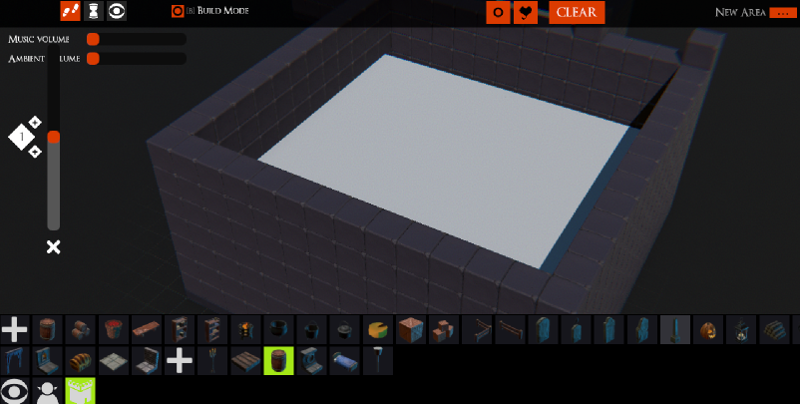
This satisfies the requirements we had so hooray!
My (albeit brief) googlings didn’t give me a guide to how to do flood fill on an octree so here is my approach. We are going to do it on quadtrees as that makes the diagrams simpler, but the extensions to 3d in this case are trivial.
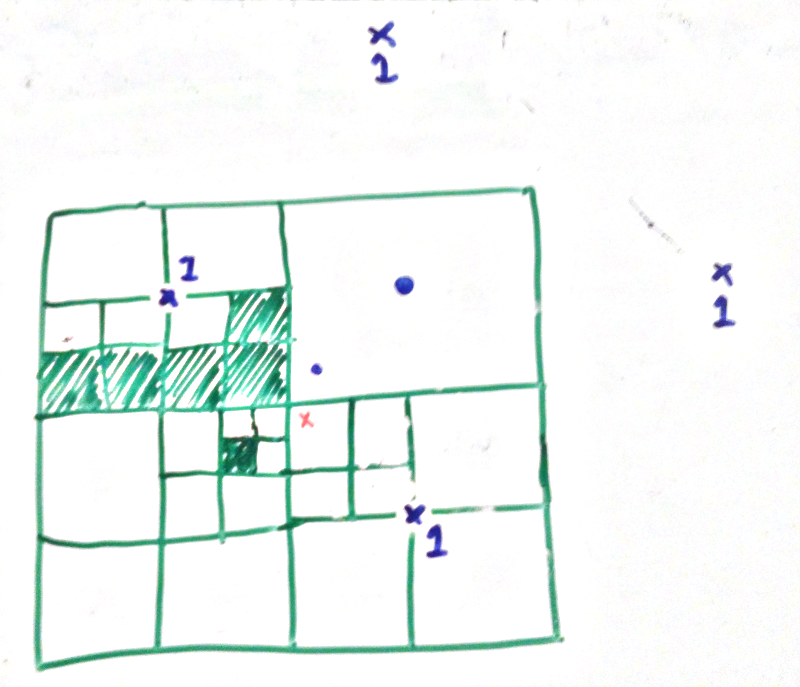
We start with our quadtree. The green colored areas are solid and the white are empty. The red cross is the starting point
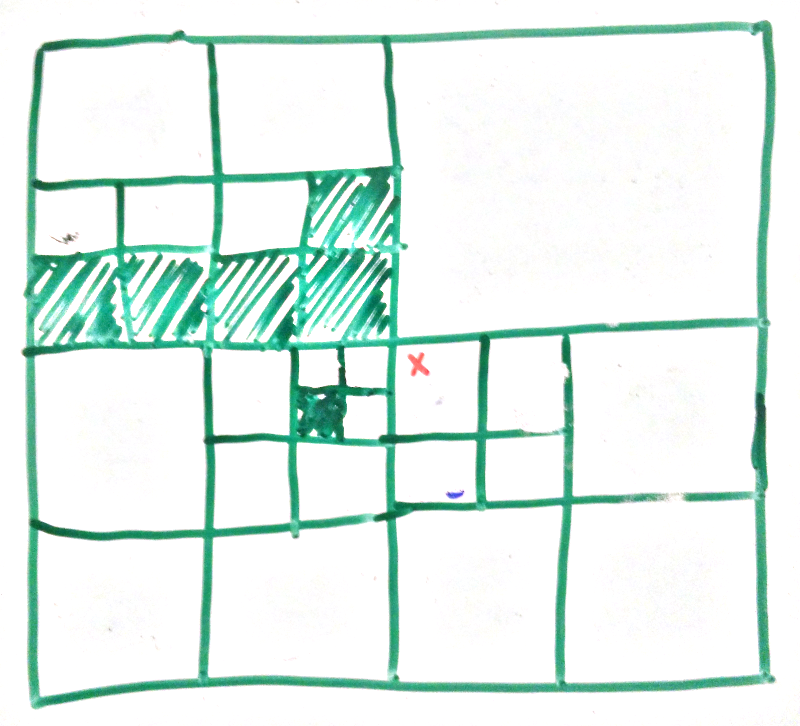
Our first step is to walk down to the deepest node containing our point. We will call the recursive function that does this WalkToPoint. We take with us:
- a list called
faces. We will explain faces soon but just know we can add things to this list and they will be processed later. - a list called
spaces. We add the empty nodes we reached to this list
When we get to the deepest node containing the point we check if it’s solid. If it is then game over the flood goes nowhere. If not then we add this node to the spaces list and then:
- starting at the center of the node pick 4 positions, one up, down, left and right from the center. The distance to the point must be the width of this node.
- add a
Faceto thefaceslist. The face contains the position, the depth of the current node (3 in our case) and the direction from that new position to this node.
So for the position we picked to the right we make a face this this:
{
Position: Vector2(),
Depth: 3,
From: Left
}
We add all 4 new faces to the faces list and return;
When we get back to the function that started the first step we go into a loop doing the following:
- take a
Faceout of thefaceslist - call
WalkToFaceon thatFace - keep doing this until the
faceslist is empty. - the
spaceslist now holds all the reachable empty nodes
Clearly WalkToFace is doing the bulk of the work so lets look at how it behaves for 3 of the 4 faces we enqueued in the first function. We are only looking at 3 as they cover this different behaviours our code has to handle
For the position on the right we start by walking towards the Position in the Face just like we did for the first point, however we are keeping track of what depth we are at and as soon as our depth matches (or exceeds) the depth in the Face we change our behaviour. In this case we have reached the deepest node already so we do the same as we did for the point, namely enqueue the 4 Faces, add the node to the spaces list and return;
The point above the first is a little different as before we hit the depth in the Face we reach the deepest node. No worries, just enqueue the 4 faces like the last 2 times and return.
Also note that in this case we have points outside the quadtree, what you do with those is up to you. In TaleSpire we have divided the board up into zones and each has it’s own octree so we pass those external points off the respective zone for processing.
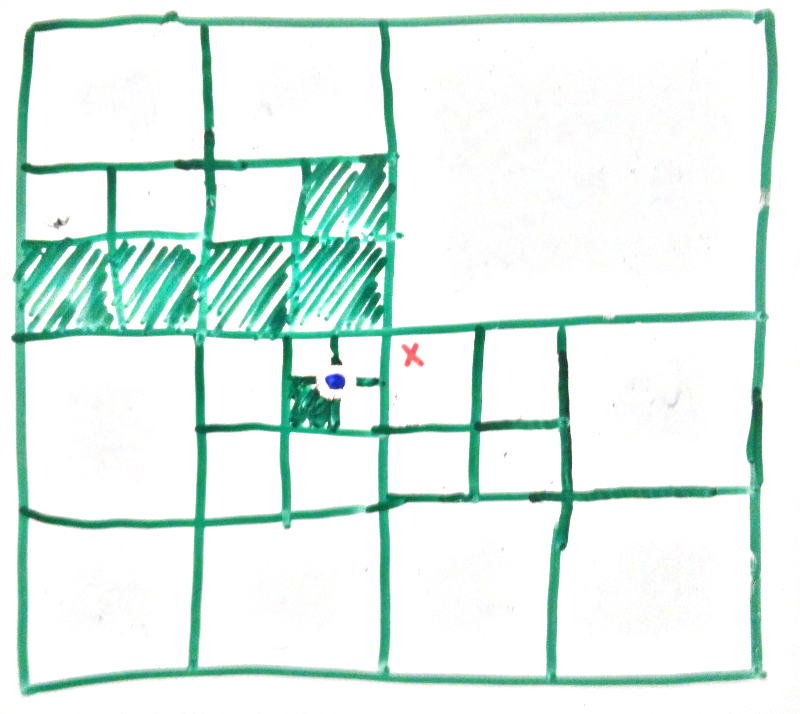
In this last case we walk to the depth specified in the Face, now we are here we still have more child nodes. This is where the From information in the Face is important. Remember that we said that once our depth >= the Face’s depth we change the behaviour. Now we stop picking nodes by the Position in Face and instead recurse into each of the child nodes on the side stated in the From field in Face. Doing this gets us to the 2 nodes marked with blue lines in the pic above.
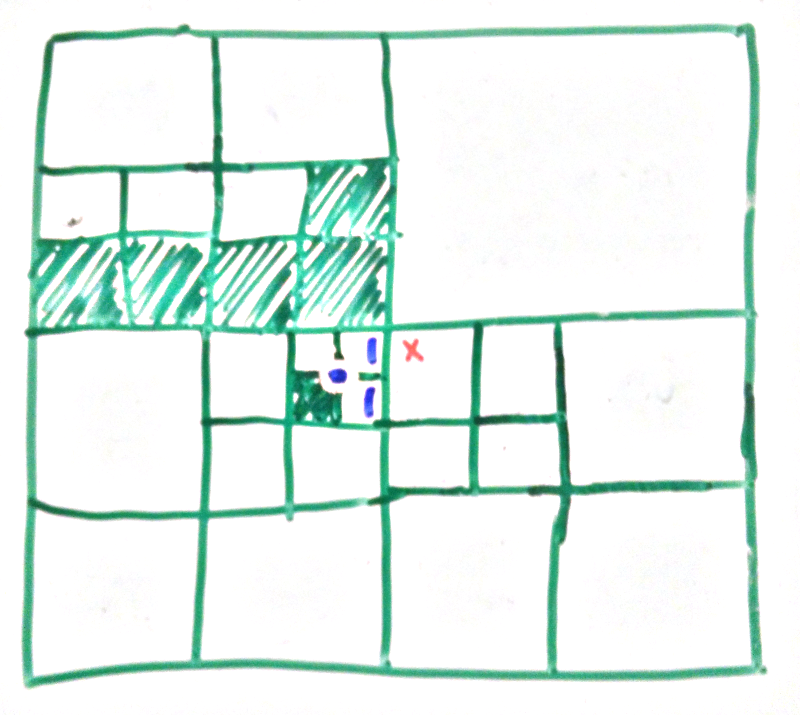
If that isn’t clear here is a different example. Here we are coming from the right so all the rightmost nodes (marked in red) are reached.
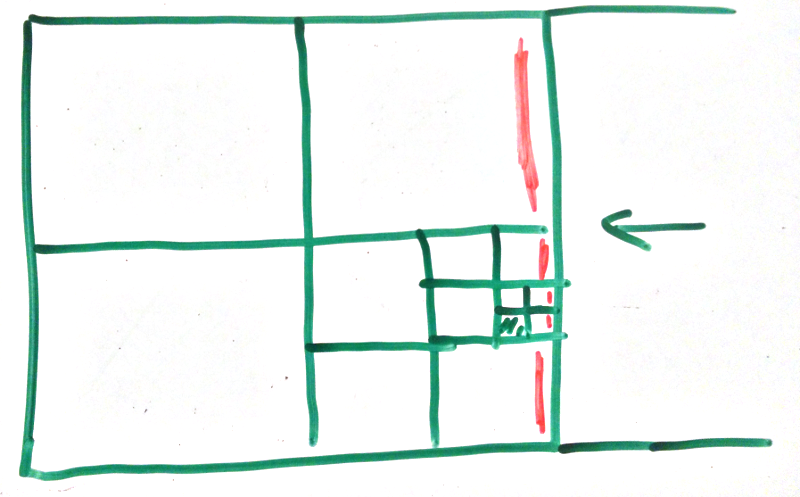
Anyhoo if we keep following the above steps we will flood to all the nodes we can reach from the initial point. Note the you mustn’t process any node that has already been added to spaces, but other than that we are good.
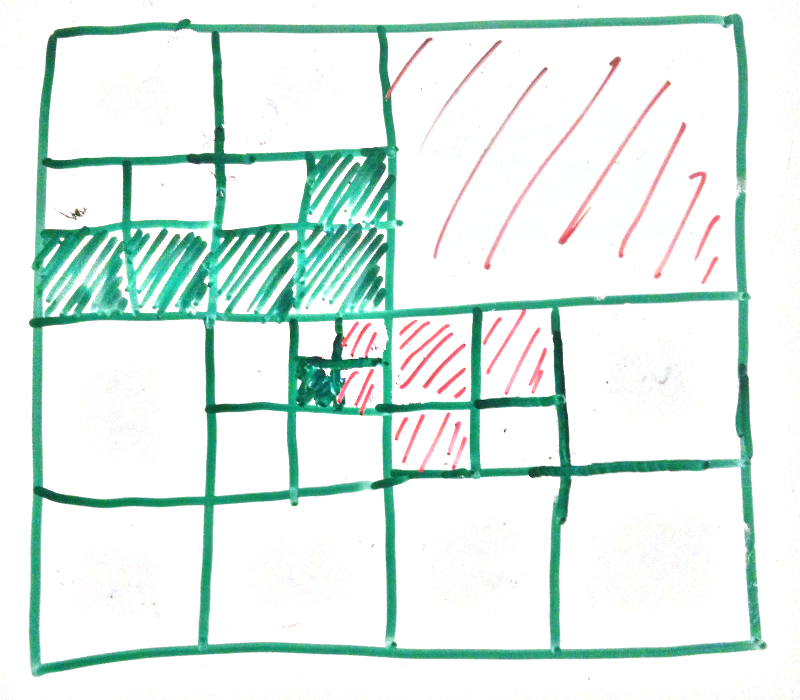
Doing this in 3D simply means handling 2 more directions.
There are lots of little places the speed this up, for example:
- track when all child nodes have been added to
spacesor are solid. Then mark the parent node as processed and never process again. - you don’t need to return all the way to the initiating function to process
WalkToFacecalls. Keep track of the position in thespaceswhen you started processing a given node. Some of entries in the list after that point will be the children trying to reach other, neighboring, child nodes. - Calculate the max number of
spacesthat could we enqueued in a single walk and preallocate thespaceslist so that it doesn’t have to grow when things are added. Less frequent allocations are almost always a plus.
But that’s enough for now. Saturday I’m going to get cross zone flooding working and Sunday will be spent hooking this up to actually show and hide objects. I also need to rewrite how I capture the collision info and handle deletions. I really wanted to get this done this week so the next week can be dedicated to refactoring how characters get placed and handle computing max walk distances, but I can tell already this will need a couple more solid days of work. Ah well.
Peace folks
TaleSpire Dev Daily 8
Todays daily is short.
FAILURE!
So far today I have failed to make a fill implementation I’m happy with. I know the exact approach I’m going for an have made some progress on the steps after extracting the reachable region, but the damn fill has been eluding me.
In the last few minutes I’ve started another way which, whilst will require a bit more bouncing around the tree, is a much simpler implementation.
Hopefully tomorrow it will be working and I can yak about that. Until then it’s just a day with a bunch of failures. No worries of course, failures small and large are pretty much a constant when coding new things so its just a sign of doing things :)
Goodnight
TaleSpire Dev Daily 7
Here we are again. This time I don’t have much to show as I spent most of the day at the whiteboard. So instead I’ll talk about the problem I’ve been mulling over.
When a character piece (henceforth just called a ‘character’) is placed on a tile we want to show every tile it could possibly reach, regardless of distance. We dont want to show things behind walls or locked doors. Also we need to do this quickly.
Actually let’s pause to clarify something. It is going to be tempting to redefine the problem given the issues that we are about to look at. You may not even like the idea of the behavior and want to change it for that reason. Please, for now, trust that we have tested this in game and it feels nice, so for now this is the problem we are trying to solve.
Alright, back to the snooker..
Before the game had floors it was effectively 2d, the approach then was to flood fill, performing raycast to see if there was an occluder (a wall) that would stop the progression. It might be rather wasteful but it worked well enough for a demo and you can get away with a lot of raycasts per frame when your game is as simple (in terms of how much stuff is going on) as ours.
However now we add floors and everything changes, now we have a third dimension to reckon with and everything gets much more expensive. One other interesting detail is although we have separate floors we also want the users to be able to make features that reach through to other floors. For example imagine a grand hall with a obsidian pyramid in the center, we want to show the whole pyramid from the ground floor even though it is several floors high as this gives the moment gravitas that would be lost if it you only saw a tenth of it.
One basic thing we did in the 2d version and will still do in the 3d version is divide the world up into zones. A zone is a 3d region of a certain number of tiles in the X and Z dimensions and some height (lets say 10 floors worth) from a given floor.
With this known we specify the subproblem as: Find every reachable place in the zone and which zones we can access from this zone.
Also it’s worth noting that the player will be moving the character frequently so the result should be cachable or very cheap to recompute.
In my mind we need to know what is solid and what is empty space. Let’s say the zone was 81x81 tiles in size and just as high as it is wide. The tiles are 1 Unity unit in size so that’s 81x81x81 units, assuming we only need to know if a unit cube is solid or not then a dumb solution would require us to store 531441 booleans (true or false) so say whether each part of the zone is solid or empty. Clearly for large boards this is untenable.
One common and reliable way to store 3d spatial data more efficiently is using an octree. It recursively subdivides space into 8 equal subspaces down to the required resolution. So (for a 2d example), rather than having the 2d array on the left with 36 slots we have the approach on the right with 10 slots as we don’t subdivide if there is no new information inside.
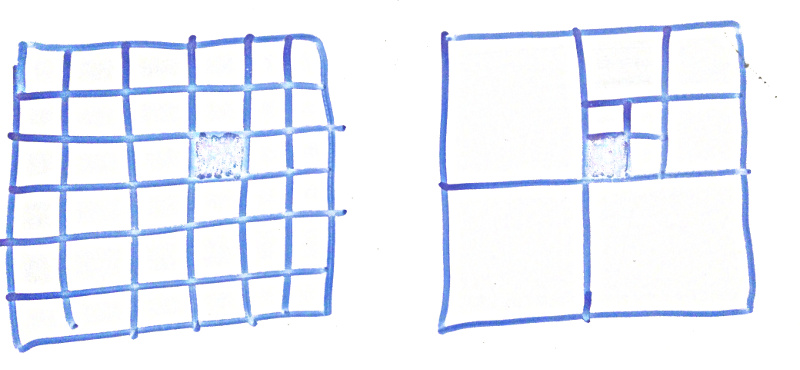
yup it’s not a totally accurate drawing but I hope ya get the idea
Each node in the quadtree has, either a marker saying it’s solid/empty or has 4 child nodes.
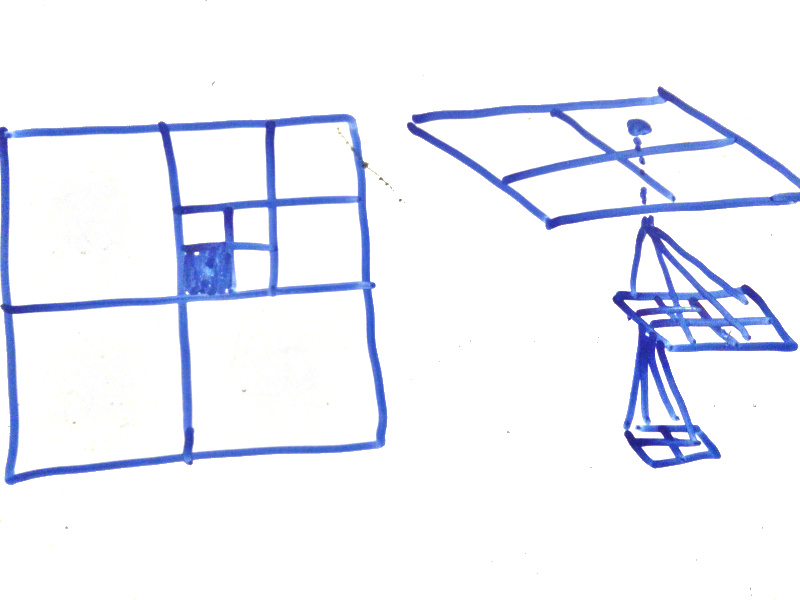
For octrees it’s the same deal but with 8 nodes and 3 dimensions.
So, now we have our data-structure we can fill it with information about what is solid and what isn’t. Then we could so something rather similar to the old flood fill, only this time we start from the character position, find what region in the octree they are in and walk to the neighboring regions.
Most of the time we move somewhere it’s going to be one of the places we have already searched so we can cache the result of the previous walk. We can also cache the octree itself.
So far so good, but there are issues:
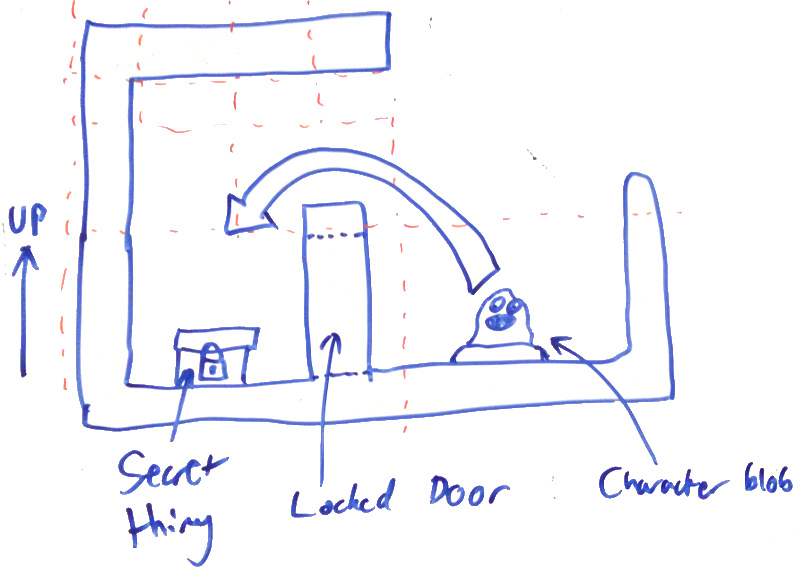
a. Our 3d search can search over walls we need to limit that but that will limit their b. Not having to search to work out what parts of the quadtree/octree are accessible would be cool. They have that built in recursive structure so can we leverage that? c. Tiles are place on the floor itself or on other tiles, can we propagate information between them on creation that could help us? could we serialize it when saving the level so we dont have to recompute on load?
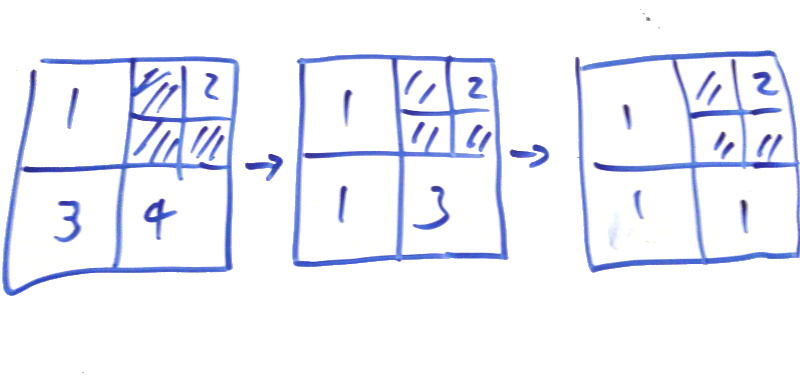
b gets rather tantalizing. If we could asign each node in the tree an integer id, we could then take the min of the neighbours and it would resolve to all nodes having the same id if they are reachable. The resolve takes time though, could we find a way to do this in 1 (or some fixed low number) of passes? Is it worth it?
Unrelated but important; if you want to be fast then cache locality matters. Could we store the data in a way that helps our intended access patterns (searching)? One example could be using a Z-order curve to linearize the data and using something like a skiplist to keep the data sparse.. again would this actually help? It all depends on our data and how we access it.
I’ve been asking a lot of questions as it frames the issue nicely, but I do have some WIP answers but explaining them will balloon this post even more so for now I’ll just say I hope to have something I can show by the end of Sunday. I’d also like to stress that these problems arent novel, there is a lot of literature and most games will be dealing with much more interesting cases than this.. still it’s fun to think about.
Until tomorrow, Ciao
TaleSpire Dev Daily 6
It was a slow day today. I carried on working on the fog-of-war system which is what works out where in a board a given character could get to. It’s being rewritten as the version we have demoed so far did not handle multiple floors.
The behavior needed is that, when a character is placed, everywhere that is accessible in the board should be visible. To do this we are splitting up the (occupied parts of the) board into zones and in each zone we have a structure that describes where is solid. This makes it cheaper to search the zone when ascertaining what you can see, as we don’t need to hammer Unity’s collision system all the time.
This fiddly thing is we want it to be fast and so I’m trying to balance cache locality of data with wanting a pretty sparse data-structure. I had wanted to make use of Unity’s new job system and there you need decent size chunks of ‘flat’ data. For that reason I had wanted to avoid octrees and look at simpler bucketing instead. My current approach is pretty crappy but I really need to get something working so I can start measuring.
The good part is that I added the Zones class and got the low res collision info from yesterday written into the Zone. Tomorrow I will try and not think about how bad performance will be and just write the search.. or if I cant then I will take the search back to the whiteboard :)
Until then, seeya
TaleSpire Dev Daily 5
Hey all,
The planning weekend went really well. We whiteboarded out the new visibility system and the code that handles where is walkable. The will no doubt be changes to the design but we can see how that goes this week. We also ran through the core user journey and planned out the UI, data requires and systems that still need making. Whilst I dont have specifics for you right now I am even more confident that you folks will have some form of early access in your hands this year.
I started the steam login integration. Thanks to steamworks.net the unity side was easy and the server side was just basically a get request so no issues there.
I do want to clarify that Steam will not be the only way to log in. We don’t want to force people into a specific platform so we will have a few options when the release comes out. It may be what we use for the alpha though, we shall see.
Right, I’m tired so I’m going to stop coding now and chill.
Peace
p.s On the left is a test of some generated lower res information to be used in the visibility system.
TaleSpire Dev Daily 4
Today I put aside the undo/redo work and focused on fixing little bugs instead. As I’m off to @jonnyree’s place this weekend I really wanted to get the recent stuff as stable as possible so we can merge it to master before I dive into another chunk of the project.
That mainly involved fixing some bugs around network IDs, a dumb mistake in serialization, and a bunch of little cleanups.
Hmm, there’s not really much else to say. Ah well, there are plenty of days like this.
Seeya folks, back on Monday with the new plans
Peace