From the Burrow
It's been a good week
Some other projects have been accepted into the lisp package manager.
I put out 2 new videos:
I have added graphing functions to Nineveh my ‘standard library’ of gpu functions for CEPL
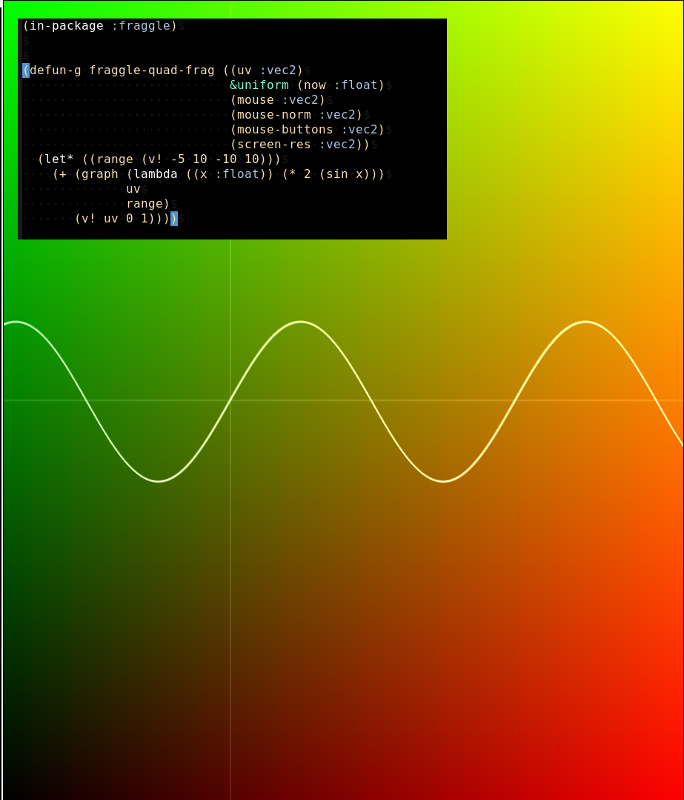
And I’ll be streaming here this Wednesday 18:00 UTC. The plan is to learn some graphic programming stuff by using lisp to take things apart on the stream. This week I’m going to start on the road to understanding noise functions by taking apart some gpu hashing functions. I’m a bit nervous but if it goes well I’m gonna try doing these weekly.
That’s all for now. Seeya.
The stocking of Nineveh
What a week. I’m a bit exhausted right now as I’ve been pushing a bit, but the results are fairly pleasing to me.
GLSL Quality
First off I did a bunch of work in making the generated GLSL a bit nice to read. The most obvious issue was that, when I returned multiple values I would created a bunch of temporary variables. The code was all technically correct but it didn’t read well. So now like this:
(defun-g foo ((x :float))
(let ((sq (* x x)))
(values (v2! sq)
(v3! (* sq x)))))
can compile to glsl like this
vec2 FOO(float X, out vec3 return_1)
{
float SQ = (X * X);
vec2 g_G1075 = vec2(SQ);
return_1 = vec3((SQ * X));
return g_G1075;
}
Which is fairly readable. 1 temporary variable is still used, but that is to maintain the order of evaluation that was expected.
return is one of areas of the compiler with the most magic as we generate different code based on the context the code is being compiled in. It could be a return from a regular function (like above), or it could be from a stage in which case we need to turn it into out interface block assignments etc. This meant it took a bunch of testing to get it correct.
Compiler cleanup
For a while I’ve been trying to clean up the code around how multiple return values are handled. I had a few false starts here (which ended in force-pushing away a day’s worth of work) but it’s done now. They are still plenty of scars in the codebase but the healing can at least begin :p
Bugs in release
I then found a bug & a regression in the code I had prepped for the next release (into the common lisp package manager). As the releases are not made on a fixed cadence I wasn’t sure how long I had so I dived into that. It turned out one of those cases where even good type checking wouldn’t have helped. I had removed some code that looked redundant but was actually resolving the aliased name of a type.
Compile in every direction
With that done I had sat down for some well earned farting around. Last week I had knocked up a simple shadertoy like thing[0] so I went back to working through that.
I got to this part where it was recommending going and implementing various curve functions from folks like IQ & Golan Levin. So dutifully I started.. but I was getting this nagging feeling that I should have more noise functions. So after porting some functions from the chaps above I found [this article] (https://briansharpe.wordpress.com/2011/10/01/gpu-texture-free-noise/) on texture-free noise.
Needless to say I got hooked on that, and then finding out out he had a whole library I decided that I needed it, all of it, in lisp :)
So that was the weekend. I polished up my naive GLSL -> Lisp translator and got cracking porting. Having this much code pouring in was a really good test-case for the compiler and so I got to clean up a few more bugs in the process.
One interesting addition to the compiler was to allow floating point numbers as strings in the lisp code. It looks like this: (+ (v4! 1.5) (v4! "1.4142135623730950488016887242097")) the reason for this is that some floating point numbers used in shaders are used for their exact bit-pattern rather than strictly for the value itself. This optional string syntax avoid the risk of the host lisp using a different floating point representation a messing up the value in some way.
The first pass of the import is done. Next is cleanup and documentation but that is less critical. My standard library Nineveh is looking slightly better stocked now :)
Validation
One thing that felt great was noticing that, in the naive GLSL -> Lisp translator and got cracking porting. Having this much code pouring in was a really GLSL noise library, there were cases where it would be nice to switch out the hashing function used in a noise function. In the GLSL it was done with comments but I realized this was a PERFECT place to use first class functions. So here it is:
(defun-g ctoy-quad-frag ((uv :vec2)
&uniform (now :float)
(mouse :vec2)
(mouse-norm :vec2)
(mouse-buttons :vec2)
(screen-res :vec2))
;; here is the hash function we pass in ↓↓↓↓↓↓
(v3! (+ 0.4 (* (perlin-noise #'sgim-qpp-hash-2-per-corner
(* uv 5))
0.5))))
In that code we call perlin-noise passing in the hashing function we would like it to use. And here is the generated GLSL.
// vertex-stage
#version 450
uniform float NOW;
uniform vec2 MOUSE;
uniform vec2 MOUSE_NORM;
uniform vec2 MOUSE_BUTTONS;
uniform vec2 SCREEN_RES;
vec3 CTOY_QUAD_FRAG(vec2 UV);
float PERLIN_NOISE(vec2 P);
vec2 PERLIN_QUINTIC(vec2 X2);
vec4 SGIM_QPP_HASH_2_PER_CORNER(vec2 GRID_CELL, out vec4 return_1);
vec4 QPP_RESOLVE(vec4 X1);
vec4 QPP_PERMUTE(vec4 X0);
vec4 QPP_COORD_PREPARE(vec4 X);
vec4 QPP_COORD_PREPARE(vec4 X)
{
return (X - (floor((X * (1.0f / 289.0f))) * 289.0f));
}
vec4 QPP_PERMUTE(vec4 X0)
{
return (fract((X0 * (((34.0f / 289.0f) * X0) + vec4((1.0f / 289.0f))))) * 289.0f);
}
vec4 QPP_RESOLVE(vec4 X1)
{
return fract((X1 * (7.0f / 288.0f)));
}
vec4 SGIM_QPP_HASH_2_PER_CORNER(vec2 GRID_CELL, out vec4 return_1)
{
vec4 HASH_0;
vec4 HASH_1;
vec4 HASH_COORD = QPP_COORD_PREPARE(vec4(GRID_CELL.xy,(GRID_CELL.xy + vec2(1.0f))));
HASH_0 = QPP_PERMUTE((QPP_PERMUTE(HASH_COORD.xzxz) + HASH_COORD.yyww));
HASH_1 = QPP_RESOLVE(QPP_PERMUTE(HASH_0));
HASH_0 = QPP_RESOLVE(HASH_0);
vec4 g_G5388 = HASH_0;
return_1 = HASH_1;
return g_G5388;
}
vec2 PERLIN_QUINTIC(vec2 X2)
{
return (X2 * (X2 * (X2 * ((X2 * ((X2 * 6.0f) - vec2(15.0f))) + vec2(10.0f)))));
}
float PERLIN_NOISE(vec2 P)
{
vec2 PI = floor(P);
vec4 PF_PFMIN1 = (P.xyxy - vec4(PI,(PI + vec2(1.0f))));
vec4 MVB_0;
vec4 MVB_1;
//
// Here is that hashing function in the GLSL
// ↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
MVB_0 = SGIM_QPP_HASH_2_PER_CORNER(PI,MVB_1);
vec4 GRAD_X = (MVB_0 - vec4(0.49999));
vec4 GRAD_Y = (MVB_1 - vec4(0.49999));
vec4 GRAD_RESULTS = (inversesqrt(((GRAD_X * GRAD_X) + (GRAD_Y * GRAD_Y))) * ((GRAD_X * PF_PFMIN1.xzxz) + (GRAD_Y * PF_PFMIN1.yyww)));
GRAD_RESULTS *= vec4(1.4142135623730950488016887242097);
vec2 BLEND = PERLIN_QUINTIC(PF_PFMIN1.xy);
vec4 BLEND2 = vec4(BLEND,(vec2(1.0f) - BLEND));
return dot(GRAD_RESULTS,(BLEND2.zxzx * BLEND2.wwyy));
}
vec3 CTOY_QUAD_FRAG(vec2 UV)
{
vec4(MOUSE_NORM.x,MOUSE_BUTTONS.x,MOUSE_NORM.y,float(1));
return vec3((0.4f + (PERLIN_NOISE((UV * float(5))) * 0.5f)));
}
void main()
{
CTOY_QUAD_FRAG(<dummy v-vec2>);
gl_Position = vec4(float(1),float(2),float(3),float(4));
return;
}
I’m stoked at how natural the function call looks in the resulting code. Also it’s extra func that the function passed in has 2 return values and everything just worked :)
For completeness here are a couple of the other functions involved
(defun-g perlin-noise ((hash-func (function (:vec2) (:vec4 :vec4)))
(p :vec2))
;; looks much better than revised noise in 2D, and with an efficent hash
;; function runs at about the same speed.
;;
;; requires 2 random numbers per point.
(let* ((pi (floor p))
(pf-pfmin1 (- (s~ p :xyxy) (v! pi (+ pi (v2! 1.0))))))
(multiple-value-bind (hash-x hash-y) (funcall hash-func pi)
(let* ((grad-x (- hash-x (v4! "0.49999")))
(grad-y (- hash-y (v4! "0.49999")))
(grad-results
(* (inversesqrt (+ (* grad-x grad-x) (* grad-y grad-y)))
(+ (* grad-x (s~ pf-pfmin1 :xzxz))
(* grad-y (s~ pf-pfmin1 :yyww))))))
(multf grad-results (v4! "1.4142135623730950488016887242097"))
(let* ((blend (perlin-quintic (s~ pf-pfmin1 :xy)))
(blend2 (v! blend (- (v2! 1.0) blend))))
(dot grad-results (* (s~ blend2 :zxzx) (s~ blend2 :wwyy))))))))
(defun-g sgim-qpp-hash-2-per-corner ((grid-cell :vec2))
(let (((hash-0 :vec4)) ((hash-1 :vec4)))
(let* ((hash-coord
(qpp-coord-prepare
(v! (s~ grid-cell :xy) (+ (s~ grid-cell :xy) (v2! 1.0))))))
(setf hash-0
(qpp-permute
(+ (qpp-permute (s~ hash-coord :xzxz)) (s~ hash-coord :yyww))))
(setf hash-1 (qpp-resolve (qpp-permute hash-0)))
(setf hash-0 (qpp-resolve hash-0)))
(values hash-0 hash-1)))
All credit of implementation goes to Brian Sharpe for this excellent noise library
Peace
OK I’ll stop now and spare you more details. I’m just so happy to see this behaving.
Have a great week.
Ciao
[0] https://github.com/cbaggers/fraggle/blob/master/main.lisp
Trials and Tessellations
Tessellation works! I was able to replicate the fantastic tutorial from The Little Grasshopper and finally get a test of a pipeline with all 5 programmable stages.
This took a little longer than expected as my GPU complained on the following shader
Error compiling tess-control-shader: 0(6) : error C5227: Storage block FROM_VERTEX_STAGE requires an instance for this profile 0(13) : error C5227: Storage block FROM_TESSELLATION_CONTROL_STAGE requires an instance for this profile
#version 450
in _FROM_VERTEX_STAGE_
{
in vec3[3] _VERTEX_STAGE_OUT_1;
};
layout (vertices = 3) out;
out _FROM_TESSELLATION_CONTROL_STAGE_
{
out vec3[] _TESSELLATION_CONTROL_STAGE_OUT_0;
};
void main() {
vec3 g_G1327 = _VERTEX_STAGE_OUT_1[gl_InvocationID];
vec3 g_GEXPR01328 = g_G1327;
_TESSELLATION_CONTROL_STAGE_OUT_0[gl_InvocationID] = g_GEXPR01328;
float TESS_LEVEL_INNER = 5.0f;
float TESS_LEVEL_OUTER = 5.0f;
if ((gl_InvocationID == 0))
{
gl_TessLevelInner[0] = TESS_LEVEL_INNER;
gl_TessLevelOuter[0] = TESS_LEVEL_OUTER;
gl_TessLevelOuter[1] = TESS_LEVEL_OUTER;
gl_TessLevelOuter[2] = TESS_LEVEL_OUTER;
}
}
As far as I can tell, the above code is valid according to the spec, but my driver wasn’t having any of it[0]. This meant I had to do some moderate code re-jiggling. You can’t just add an instance name to the blocks as then you get:
Error Linking Program 0(13) : error C7544: OpenGL requires tessellation control outputs to be arrays
Grrr. This makes total sense according to the spec though, so grr goes back to error C5227. FUCK YOU C5227.
Anyway that got fixed and this happened

With that done I made sure the same worked using CEPL’s inline glsl stages and tested a bunch.
This left me at an odd point. CEPL has a lot less gaps in the API that it used to[1], it feels kind of ready for me to use.
So I sat down with The Book of Shaders and got started. I simply can’t give that project enough praise, it’s wonderfully written and remains interesting whilst also pushing you just enough to really digest the details of what they want you to learn. I made a little shadertoy substitute[2] and started doing the exercises. I have to say I’m pretty proud with how fun it all felt, it’s been a lot of work to get something that is lispy but doesn’t feel hampered by being the non-native language, so those hours of play were very vindicating.
Within a very short time The Book of Shaders is getting you to amass a collection of helper functions for your shaders. I already have a (very wip) project called Nineveh for this purpose, so it’s time to start working on that again! I want a kind of ‘standard library’ for CEPL, somewhere you can find a pile of implementations of common functions (e.g. noise, color conversion, etc) to either use to at least use as a starting point.
There are often cases where libraries like this fall short as you want a slight variation on a shader. Say for example you like their FBM function but want one more octave of noise. I’m hoping macros can help a little here as we can provide something that generates the variant you need.
This is likely naive but it’ll be fun to try.
Right, that’s my lot for now. Seeya!
[0] I was meant to be using the compatibility profile too so I’m not sure what was up
[1] See last weeks post for what remains
[2] There’s about 50 lines not shown here which handles input & screen events.
(in-package :ctoy)
(defun-g ctoy-quad-vert ((pos :vec2))
(values (v! pos 0 1)
(* (+ pos (v2! 1f0)) 0.5)))
(defun-g ctoy-quad-frag ((uv :vec2)
&uniform (now :float)
(mouse :vec2) (mouse-norm :vec2) (mouse-buttons :vec2)
(screen-res :vec2))
(v! (/ (s~ gl-frag-coord :xy) screen-res) 0 1))
(def-g-> draw-ctoy ()
:vertex (ctoy-quad-vert :vec2)
:fragment (ctoy-quad-frag :vec2))
(defun step-ctoy ()
(as-frame
(map-g #'draw-ctoy (get-quad-stream-v2)
:now (* (now) 0.001)
:mouse (get-mouse)
:mouse-norm (get-mouse-norm)
:mouse-buttons (get-mouse-buttons)
:screen-res (viewport-resolution (current-viewport)))))
(def-simple-main-loop ctoy
(step-ctoy))
Checking in
So this week I don’t have much technical to write about, the main things I’ve been doing are
- Bug-fixing/refactoring
- Getting everything into master and then finally
- Getting the next release ready.
This month’s release will bring a huge slew of changes into the compiler, starting with all the geometry shader work I’ve been doing. I’ve also landed the new backwards compatible host API for CEPL which brings multiple window support among other things.
In the next 2 weeks I want to have finished my latest cleanup of Varjo and added support for tessellation stages.
After this I’ve reached an interesting place with regards to CEPL as I think the major features will be done. I’ve still got a few things I want support for before I call it v 1.0:
- Scissor
- Stenciling
- Instanced Arrays
- Multiple Contexts
And each of those seem like fairly contained pieces of work. Even though there are things in GL I haven’t considered supporting yet (like transform feedback) I don’t think I’ve ever felt this close to CEPL being ‘ready’.. It’s an odd feeling.
After that I’d like to focus of stability, performance and on Nineveh which is going to be my ‘standard library’ of GPU functions and graphics related stuff.
Until next week,
Peace
Geometry Shader Shenanigans
When I gave that talk a few weeks back I said, rather naively in hindsight, that geometry & tessellation shaders should work.. man was I wrong there. It turned out to be rather fiddly to find a balance that felt lispy, worked with my current analogies and worked across all GLSL version (or at least failed gracefully).
Lets start at the beginning.
Passing values between GLSL stages
To pass values from stage to stage in GLSL starts simply, you declare something as out in one stage and in in the next e.g:
out vec4 foo; // in the vertex shader
in vec4 foo; // in the fragment shader
Nice and simple. It also works for arrays of values.
Next we add a geometry (or tessellation) shader. Now we are working with primtives (or patches) so the outs from the last stage become an array of ins in the geometry stage.
out vec4 foo; // in the vertex shader
in vec4[2] foo; // in the geometry shader
The length of the array is dictate by the size of the primitive, so lines are length 2, triangles are length 3, etc.
But how about if the out was an array?
out vec4[10] foo; // in the vertex shader
in vec4[2][10] foo; // in the geometry shader
Simple right? I thought so and I updated my compiler to work with this. I kept having this nagging feeling though, something about interface blocks. Turns out I should have listened to the feeling sooner. Support for arrays of arrays only arrive in GLSL in v4.3 and before that you needed to use an interface block:
out VertexOuts
{
vec4[10] foo;
}
out VertexOuts
{
vec4[10] foo;
} gs_in[2];
Which seems ok, but it has subtleties to it that make this hard to abstract for all GLSL versions. Lets have a look at the lisp.
First a vertex shader:
(defun-g test-vert ((position :vec4) (uv :vec2))
(values position normal))
the outputs from the above are a vec4 which is used as the gl-position and a vec2 which is passed to the next stage. Here is a valid fragment shader to go with this:
(defun-g test-frag ((uv :vec2) &uniform (tex :sampler-2d))
(texture tex uv))
So far, so simple. Next let’s look at a geometry shader that would match that vertex shader’s outputs. We will assume we are rendering triangles.
(defun-g test-geom ((uv (:vec2 3)))
...)
Makes sense right? We just array the inputs. However we know that our interface block is going to cause problems. In this case uv isn’t really vec2[3] it’s in blockName { vec2 }gs_in[3]. We have a mismatch between the abstraction and reality. However it’s a useful lie, it takes the GLSL behavior and makes things more consistent and thus easy to understand, so if we can keep it I’d prefer to.
The answer (at least for now) is to make an ‘ephemeral’ type, this is a type that can’t exists in GLSL for real, but one that our compiler can handle.
So this:
(defun-g test-geom ((uv (:vec2 3)))
(let ((a uv)
(index 1))
(aref uv index)
..))
becomes something like:
..
in IN_BLOCK
{
vec2 uv;
} gs_in[3]
void main()
{
int index = 1;
gs_in[index].uv;
..
}
Notice that int index = 1 ended up in the GLSL but there is no a = <something>, that is because of that ephemeral type. The reason that it has to be ephemeral is that until we use aref we can’t access the uv slot inside the block. Also you cant write IN_BLOCK tmp = gs_in[1] or IN_BLOCK[3] tmp = gs_in as whilst interface blocks may look like structs, but they dont’ behave like them and those two example as simply illegal in GLSL. It’s a damn shame really as otherwise this would be much easier!
One other option we could have gone for instead of this ephemeral array business we could invent a ‘primitive’ type. So the geom shader could be:
(defun-g test-geom ((uv triangle))
(let ((a uv)
(index 1))
(aref uv index)
..))
But then test-geom is no longer a stand alone function, we would need to wait until test-geom was used in a pipeline to know what slots triangle contained. One of the beauties of CEPL is that all gpu functions are simply functions until they are used in a pipeline, they can be used as stages or just be called from other gpu functions. If we use triangle then we can’t compile this gpu function ahead of time, which would suck as that feature currently lets you find and fix bugs faster. On top of this triangle would also have to be ephemeral as there is no triangle type in GLSL
The same also goes for requiring the user to define the interface between vertex & geom shaders as structs. You still need the ephemeral & you require the user to repeat themselves.
This is one of those cases where every option is kinda sucky but the first one described feels the least sucky, and that is the one I have gone for.
Implement it
The above took a few days of experiments and pain to get ironed out, and then it needed to be implemented. As usual working in areas of the compiler that haven’t been touched for a while uncovered bugs and general weaknesses that needed fixes.
Another thing that was playing a lot on my mind was that one of the features CEPL has is support for is defining a stage as raw GLSL and using it in a pipeline, so whatever I made needed to not break that. Having users is awesome and I really want to make sure I don’t fuck up their workflow if I can help it. For example one person is already using the GLSL stage support in CEPL to use Tessellation shaders, which is something I’ve never used! The fact that they can do this makes me happy and eases the pain whilst I slowly find nice lispy ways of doing the same.
Oh, I almost forgot..
Primitives!
As we are in the world of Geometry & Tessellation we need to talk about primitives. One of the things I love about Varjo is that it can pass information from stage to stage so the user doesn’t have to write the same stuff multiple times, we should be able to do the same with primitives. I wanted to be able to take the OpenGL draw-mode and pass it through the compilation. This allows Varjo to not only write some of the GLSL automatically (e.g. layout(triangles) in; in the Geometry stage) but also to know the length of the array’d interface block going into the geometry stage. Having little details like this checked is worth my time as then Varjo can give much nicer and more targeted errors that GL can.
I’ll skip the details on this for now as this post is already getting long.
Where are we now?
We are here

I finally got these damn things working. Here we are using a geometry shader to draw the normals of the sphere.
There is still a bunch of stuff to do and there are some aspects that really pushed the limits of how ‘lispy’ stuff could be made. I’ll save that for another post. I’ll simply say thanks for reading and leave you with the pipeline for drawing the lines in the above.
Ciao
This lisp code:
(defun-g normals-vert ((vert g-pnt) &uniform (model->clip :mat4))
(values (* model->clip (v! (pos vert) 1))
(s~ (* model->clip (v! (norm vert) 0)) :xyz)))
(defun-g normals-geom ((normals (:vec3 3)))
(declare (varjo:output-primitive :kind :line-strip :max-vertices 6))
(labels ((gen-line ((index :int))
(let ((magnitude 0.2))
(setf gl-position (gl-position (aref gl-in index)))
(emit-vertex)
(setf gl-position
(+ (gl-position (aref gl-in index))
(* (v! (aref normals index) 0f0)
magnitude)))
(emit-vertex)
(end-primitive)
(values))))
(gen-line 0)
(gen-line 1)
(gen-line 2)
(values)))
(defun-g normals-frag ()
(v! 1 1 0 1))
(def-g-> draw-normals ()
:vertex (normals-vert g-pnt)
:geometry (normals-geom (:vec3 3))
:fragment (normals-frag))
makes this glsl:
("#version 450
in vec3 fk_vert_position;
in vec3 fk_vert_normal;
in vec2 fk_vert_texture;
out _FROM_VERTEX_
{
out vec3 _VERTEX_OUT_1;
};
uniform mat4 MODEL_62CLIP;
void main() {
vec3 return1;
vec4 g_G1550 = (MODEL_62CLIP * vec4(fk_vert_position,float(1)));
return1 = (MODEL_62CLIP * vec4(fk_vert_normal,float(0))).xyz;
gl_Position = g_G1550;
vec3 g_G1552 = return1;
_VERTEX_OUT_1 = g_G1552;
return;
}
#version 450
layout (triangles) in;
in _FROM_VERTEX_
{
in vec3 _VERTEX_OUT_1;
} inputs[3];
layout (line_strip, max_vertices = 6) out;
void GEN_LINE(int INDEX);
void GEN_LINE(int INDEX) {
float MAGNITUDE = 0.2f;
gl_Position = gl_in[INDEX].gl_Position;
EmitVertex();
gl_Position = (gl_in[INDEX].gl_Position + (vec4(inputs[INDEX]._VERTEX_OUT_1,0.0f) * MAGNITUDE));
EmitVertex();
EndPrimitive();
}
void main() {
GEN_LINE(0);
GEN_LINE(1);
GEN_LINE(2);
}
#version 450
layout(location = 0) out vec4 _FRAGMENT_OUT_0;
void main() {
vec4 g_G1553 = vec4(float(1),float(1),float(0),float(1));
_FRAGMENT_OUT_0 = g_G1553;
return;
}
Lisping Elsewhere
From Sunday to Wednesday I was away on Brussels at the European Lisp Symposium. It’s an opportunity to see good talks but more importantly to me it’s a catch up with some folks I haven’t seen in a year and nerd out.
Aside from that I’ve been cracking away at getting sketch working using CEPL under the hood. It’s rendering using lisp shaders now and live recompile works great. There has been a slight performance drop as sketch used buffer object streaming to upload the vertices and I’m not doing that yet. In fact CEPL doesn’t expose glMapBufferRange at all so first order of business is fixing that. After that I want to make a vertex-ring it’s going to be an object that encapsulates the buffer object streaming pattern and will make using it seamless.
I have also been working on fixes to Varjo that will finally get Geometry shaders working. The task for the last few days has been rewriting how Varjo handles return & making Varjo use interface blocks for passing data between stages. The reason for working on return (apart from it being buggy) was that in geometry shaders your primary task is to ‘emit’ extra geometry rather than ‘returning’ transformed data via the out vars.
I’m hoping that this weekend I can get those two things coded and tested. After that I need to look at the Geometry shaders themselves, I know there are some ugly details around ins & outs so wish me luck.
Tired but happy
I’m tired right now but also really happy with the reception the video got.
I’ve had a number of PRs to CEPL & Varjo with fixes for various things. Of special note is a chap called djeis97 who has been given me a pile of help with issues in my geometry shader generation. He’s been using the inline glsl features of CEPL too which is awesome.
In order for geometry shaders to work properly I need to do the following:
- Improve CEPL’s handling of arrays
- Generate interface blocks between shader stages
- Fix some hacks around
return&outvalues - Add some helpers for emitting vertices.
I’ve made some progress on the arrays in the last week and will be starting on interface blocks asap.
I’ve also had one chap who works on a project called sketch decide that he has had enough with dealing with opengl directly and wants to build his project on top of CEPL. This is exactly the kind of project I’ve wanted to see built with CEPL, stuff that has a clear set of trade-offs and makes making stuff super simple. His current approach supports multiple windows however, and CEPL did not, so I have been getting that in place. This has meant (even though Im not implementing yet) looking at multiple GL contexts and threading.
CEPL has no business with your threads and expects you to use them wisely, sketch however was built on top of sdl2kit which handles threading for you. This mismatch with CEPL is a little problematic and, as I don’t yet have any libraries for helping with the threading situation, I’m going to make a shim to make sdl2kit drive CEPL. It’ll be butt ugly but will hopefully be enough for now.
It’s the European Lisp Symposium in Brussels next week so it would be awesome if I had something new to give a lightning talk on..or even just to show of with :)
At some point I need sleep too.
Ciao!
Traveling Again
Turns out I booked a bunch of small trips last year and they all are around now. Sorry for the late update.
I got back to coding yesterday and have been working on the compiler. Since the talk I have some great support from djeis97 and jobez on issues in CEPL & Varjo. One big thing I realized was more broken that expected was Geometry Shaders, so that is current top priority.
The prerequisites for fixing this are better array support in Varjo & support for interface blocks, so whilst traveling I was reading the GLSL spec again. Last night I added checks to make sure you are not trying to access an uninitialized variable and then started on adding lisp’s make-array function.
As I currently don’t track const‘ness in Varjo I can’t validate a bunch of the array rules that the GLSL requires. However those are errors that will be caught by the driver’s own glsl compiler so I’m not worrying about those too much yet.
That’s all for now Peace
Tweaking
As I wrote so late last week I haven’t got too much to add here, however I have made progress on tweak.
The goal is to be able to inspect & change data easily while the program is running. You wrap a form in (tweak ..) and you get a small window (rendered using gl via nuklear) which allows you too mess with the value.
For example given this:
(defparameter *some-val* 10)
You can write this in the main body code
(tweak *some-color*)
And you get this:
And if you scrub the value it immediately applies to the form you are tweaking. You can define different tweak ui’s for different lisp types so extending will be easy. I still need to add a couple of helpers for that though.
Other than that I made a little companion library to SDL-TTF which allows people to render text straight to CEPL textures. So this:
(with-font (font "/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf")
(text-to-tex "Yo!" font (v! 1 0 0 1)))
Gives you a texture with the text.
That’s the lot I’m afraid. Time for sleep.
Late again
I have traveled to see family this week so sorry for the late writeup.
This week went pretty well. I went through the PBR example I had been using line by line making notes and then tried to match my implementation to theirs.
I had made some progress but still the colors looked washed out, something must have been putting the color values way out of wack. Finally I saw it, I had been adding a color I should have been multiplying. A facepalm and a tweak later color started looking like this

I’m still not convinced that the example’s approach for creating the final color is correct, however this is plenty good enough for now.
With that done I revisited my UI code (which uses nuklear) and found that it was broken…shits.
A bunch of git archaeology told me the issue was related to my GL context caching. Double shits
..and then that the crash occurred because I had made CEPL’s handling of the context more robust. At this point a drink was in order, but after that, fixing!
The result was that I hadn’t been unbinding VAOs correctly when rendering and so then subsequent buffer unbindings had been captured in the VAO. This sucks but was a 1 line fix and CEPL is much better for it.
Theres other stuff going on buts they are not worth yakking about right now.
Seeya