From the Burrow
TaleSpire Dev Log 358
Morning all,
I’m currently working full-steam on getting a beta build of the group-movement feature to all of you.
Yesterday I gave the lasso prototype to some folks for private testing. The feedback was generally positive, but naturally, they found some new bugs and highlighted some annoying behaviors.
I’m now working through that list, fixing the critical stuff. Hopefully, I can get those done today.
I’ll then write up the usual beta guides and tutorial videos so we can hit the publish button!
I won’t promise a date, but we are close.
One big spanner in the works is that I need to have some work done on my car, which may keep me out of the office most of the day. We’ll just have to see how that goes. If I’m stuck in town, I’ll use the day to work on server code, which is easier to work on from my laptop.
Have a good one folks, Ciao
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 357
Yesterday my goal was testing the group movement with multiple clients and, as mac support is progressing, I decided to use that for the testing.
To do this I updated our native plugin to support the lasso and broke out the profiler to check that the implementation was going to be viable on Apple Silicon. Luckily enough it ran perfectly, but as I looked at the profiler I got curious about the somewhat poor performance on medium sized boards. This led me into a day of prodding, profiling, and remembering how much I hate dealing with XCode.
The TLDR is that the M1 iMac currently struggles to render the shere amount of stuff we regularly put in our boards.
That of course won’t be the end of the story. I bumbled my way through getting an XCode build of TaleSpire that allowed for GPU profiling and the captures contains reams of data giving clues as to where we can speed things up.
We are going to need to do a lot of experiements but the work we do there will probably benefit lower-end PCs too.
There is more I can ramble about, but I’ll get to that when I’m working on mac support again so I’ll spare you that for today.
Alright folks, now I should get back to testing.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 356
Hey folks.
I’m back again with a group-selection update. In short, progress is very good.
I spent a couple of days finding a control scheme that felt good. I wanted the interaction to be based around a single modifier. You hold down a key (in my test, x), then you left-click and drag to draw the lasso. You can also single-click on a creature to add/remove them to/from the selection. It sounds simple, but I managed to go in circles a few times, ensuring that switching between single creatures and groups felt natural. It’s easy to add extra modifiers and make things feel like a tool. I’m happy to have somewhat avoided that.
Having spoken to Ree, we’ve also discussed trying another approach to the lasso control. I’ll talk about that more as it develops.
With the behavior taking shape, I turned to performance. I knew from the start that the regular C# implementation would be too slow. I wrote the code assuming that I’d be switching to compiling with Burst and using native collections. My initial tests[0] showed that updating and meshing a sizable wobbly lasso took between 14 and 17 milliseconds, which is hilariously bad[1]. By compiling with Burst, that was chopped down to a few milliseconds.
From there, I bucketed the lasso segments spatially so that intersection checks had to consider fewer segments. With this and a few more techniques, I dropped the time required to around 0.3 milliseconds.
The next part of the optimization was moving the whole process (including setting up the Unity mesh) into jobs. I spent quite a while playing with different configurations[2] until settling on what we have now. The lovely thing is that, in the typical case, the jobs are finished before the main thread needs the result. This results in the main thread only having to spend ~0.01ms on updating the lasso and mesh.
While there is definitely more I can do to optimize the lasso code, it’s plenty good enough for now[3]. It was then time to work on other actions that groups of creatures could perform. If you’ve been on our discord, you’ll have seen some clips of that work. If not, then here you go!
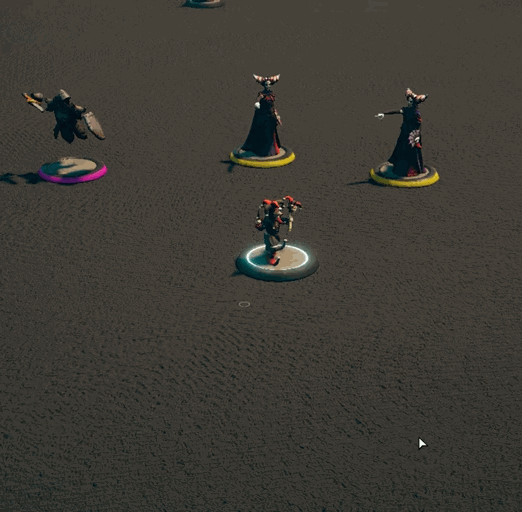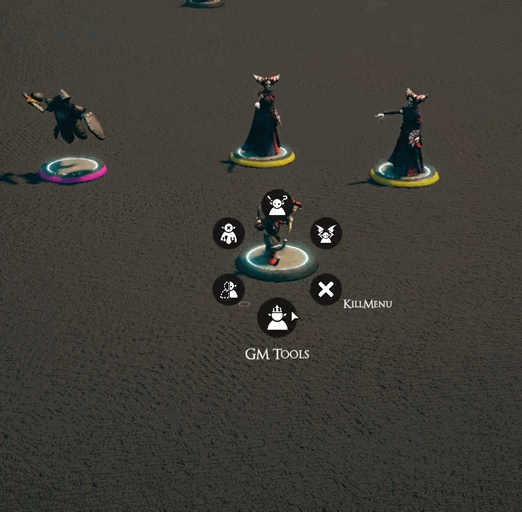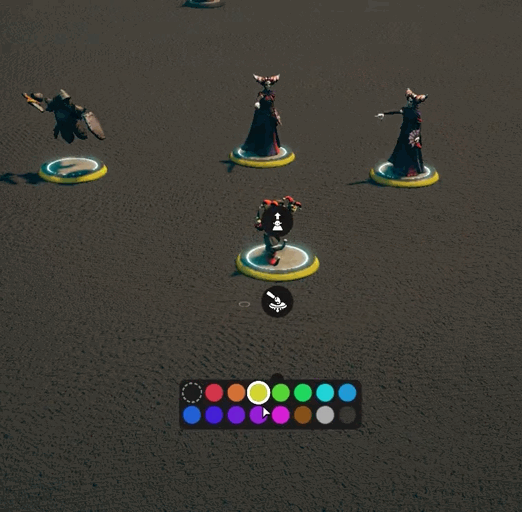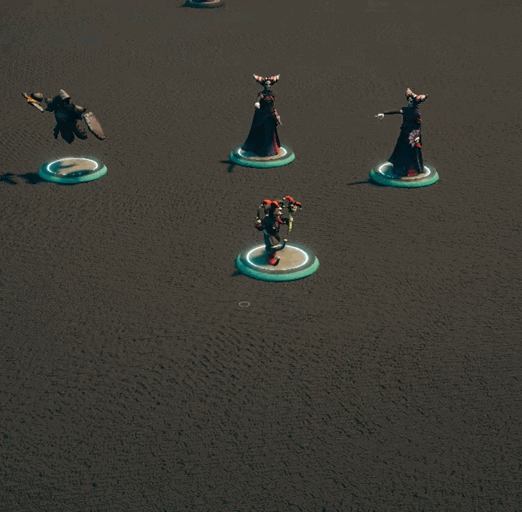
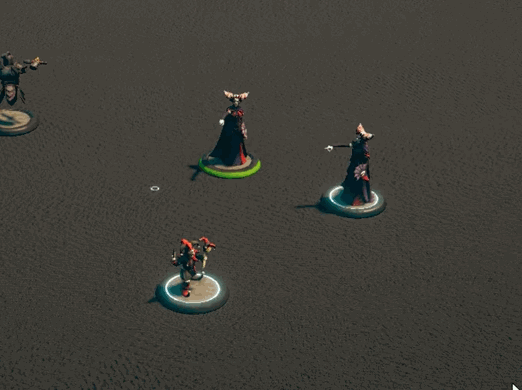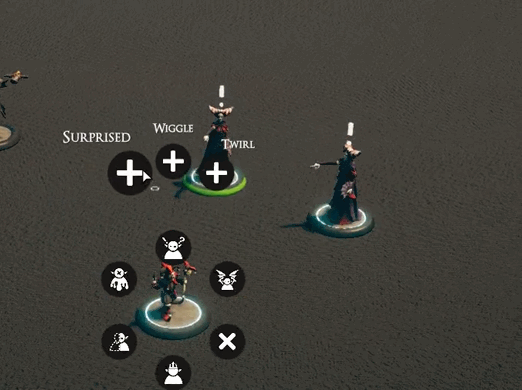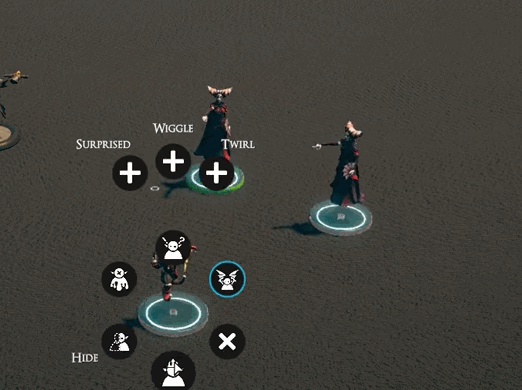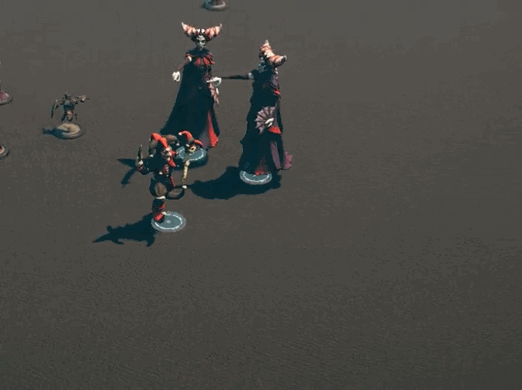

I’m not trying to support everything out of the gate, but some things just felt like they needed to be there.
Well, that’s all from me for now. While I have started looking into performance improvements needed for the macOS release, I’ll leave the details of those for another day.
Have a good one!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] I’m talking about timings, but it is very misleading. The time needed to update the lasso depends on many things, such as the lasso length, the number of self-intersections, etc. For narrative reasons, I’m going to mention numbers, but the only thing to really take away is that they got better :)
[1] For those not familiar. To run at 60fps, you need to be done with everything for a frame in 16.6ms. Spending that time just for a lasso is naturally unworkable
[2] For example, I experimented with running the meshing of separate lasso chunks in parallel. This was promising, but the overheads undid the benefits I saw from the concurrency.
[3] There are lots of other things to optimize before this one creeps back to the top of the list :)
TaleSpire Dev Log 355
Hey everyone.
As hoped, a lot of things came together today, so I’m thrilled to be able to show you this:
The lasso is finally working!
I’ve still got plenty to do, but I’m very confident about what remains.
First off, I need to clean up the implementation. Some things are still hacky and/or inconsistent with other tooling[0].
After that, the big priority will be performance. The current implementation is abysmally slow, but this was expected. I wrote it in an exploratory manner but made sure not to write code that would be hard to optimize later on[1]. If the code is slow in the ways I expect, then a combination of Burst, threading, and some spatial hashing will solve it. But we’ll see once the code is profiled.
After that, the feature should be in the cleanup phase. Tweaks, bug fixes, and testing will be the order of the day[2]. Of course, the visuals for the lasso need making, but they should not impact any other part of this feature.
And that’s the lot for today. Tomorrow is going to be another fun one for me, though not as visually dramatic :)
Have a great one folks!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] I’m being a bit nebulous as explaining it would be clunky without code examples [1] To me, this mostly means keeping to simple constructs and not writing “clever” code. [2] I’ll also be porting the c++ portions to macOS. But I think there is less than an hour of work to do there.
TaleSpire Dev Log 354
Heya folks! I’ve been quiet this last week, so let’s remedy that now.
Group Movement
The hard work for the lasso is now done! By this, Ι mean that we can draw out a lasso and get pixel-perfect info of what creatures are underneath it back from the GPU.
The text at the bottom of the video shows the IDs of creatures as they get selected. I was trying to show the pixel precision, but it’s not sure clear. The red lasso graphic is not final (which is probably obvious)
I am now resurrecting Ree’s group-movement code and wiring up the lasso selection. If all goes well, Ι hope to have something to show by the end of tomorrow.
After that, the focus is on cleanup, testing, and a proper shader for the lasso itself.
At that point, we’ll get this into a Beta. While in Beta, I’ll be focussing on bugs and performance.
macOS support
This is looking good. Ree has worked out the shader problem, but some legwork is still needed to fix it.
I’m pretty confident we’ll have macOS support in Beta within the next couple of months.
Other stuff and things
Based on this dev-log, you’d be totally justified in thinking not much is going on. While the opposite is the case, it would, unfortunately, be unfair to natter about it just now, so Ι won’t. I am really hoping to be more forthcoming in the next dev stream.
| As for the dev-stream, we can’t set a date yet as Ree is currently off sick. So no news on that yet either : |
Not the most satisfying way to wrap up a dev log Ι know. That’s why I haven’t written until Ι could at least show the lasso progress.
Can’t wait to share the rest with you,
Have a good one.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 352
Hi again,
This is a quick one to show you progress with the lasso.
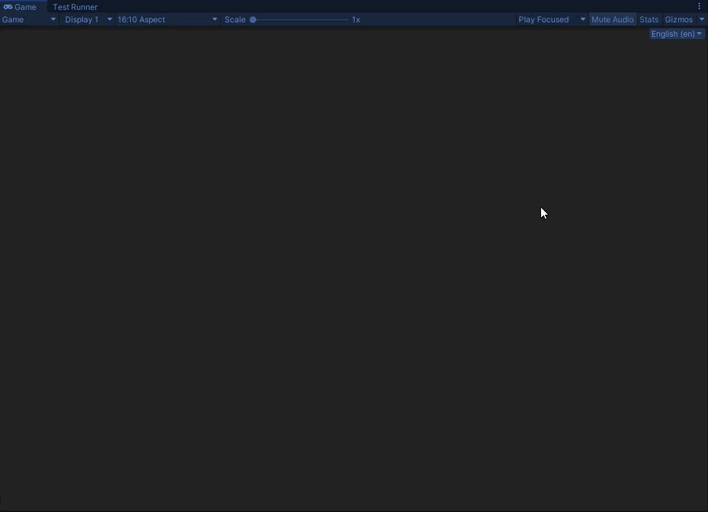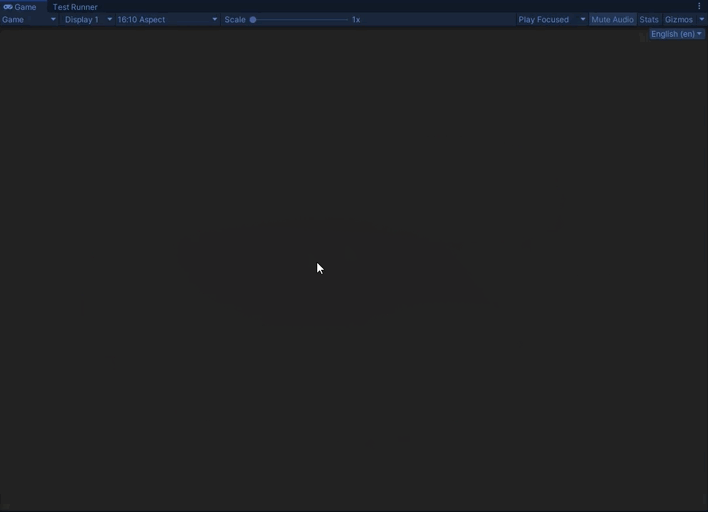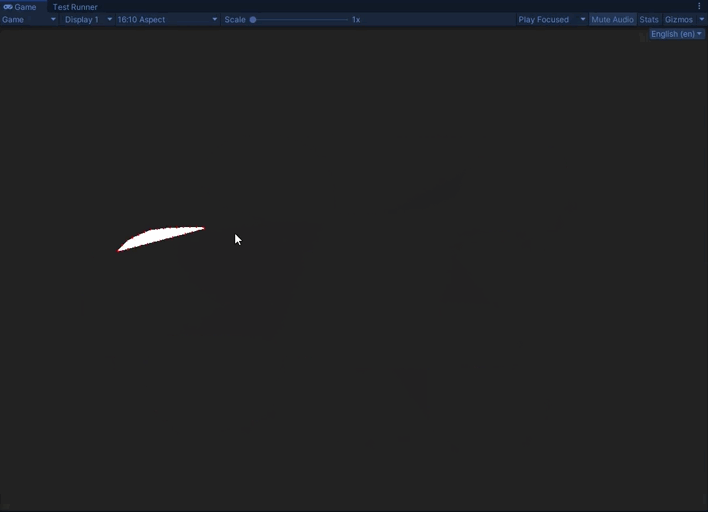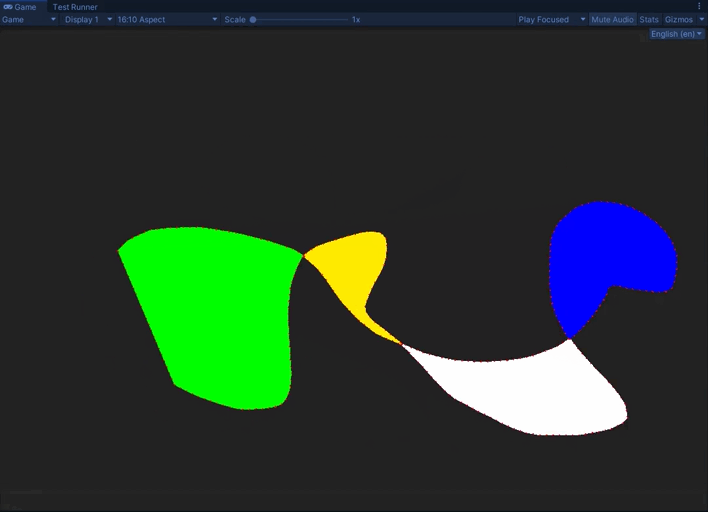
As you can see, we can now generate the mesh that fills the lasso. The visuals are all for debugging and not how it will look in-game.
Now I have this, we can start using it with the rendering portion of the selection code.
I would be starting on this first thing tomorrow. However, I had a nasty discovery today at the dentist, so I’m back there tomorrow to get it fixed. The odds are that I will be in a decent amount of pain afterward, so I’m not expecting to get any work done.
Sucks, but the alternative is worse.
Alright, I’ll check back in when I’m coding again.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 351
Hey again folks,
With AOEs shipped, I’ve returned to the lasso tool for the group-movement feature.
Previously I worked on decomposing the lasso path into simple polygons[0]. This was required for the next step, which is using a technique called “ear clipping” to make a mesh of the selected area.
If you are interested in how it works, then this video is an excellent place to start. It’s very simple, but I still managed to make it take a day :P
I made a separate project for the experiment to speed up compile times. This video shows the test code in action:

An additional requirement for ear-clipping to work is that no three consecutive vertices are colinear. It’s a bit faint, but this clip shows that when the verts are in a line, the result is one triangle rather than two.

Now I have this working, I will clean up the code, so it is ready to combine with the previous lasso work. I’ve been careful to write the code in a fashion that lends itself to porting to Burst. As a single lasso path can result in multiple polygons, I will use Unity’s job system to mesh them concurrently.
That’s the lot for today. It’s been wonderful seeing the response to AOEs. Hopefully, it won’t be too long until I can get this into Beta.
Ciao.
[0] I am not yet satisfied with my approach, but it’s good enough to allow me to write the rest of the lasso implementation.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 350
Heya folks!
It’s been a good week for feature work, so let’s get into it.
AOEs
With Ree back from vacation, he has been let loose on making AOEs. He’s made a more low-key variant of the ruler visual for the AOEs that is tintable. So yes, we will have color options for the AOEs on launch (this is landing in Beta in an hour or so). He’s made it so that, as well as the keybinding, you can right-click on a ruler and click a menu option to turn it into an AOE marker. He’s also made it so that the distance/angle indicators only appear when hovering the cursor over the AOE. This keeps the visual noise to a minimum
You can see a little of it in action here (although the visuals are not finished yet)
The latest round of playtesting has revealed a couple of things we don’t like:
-
The pixel picking for the AOE handles works great, but it’s too easy to get handles stuck inside tiles. So we are looking at augmenting the AOE picking with something that feels more forgiving. I’m currently prototyping this and will be continuing tomorrow.
-
For rulers, it feels right to see the handles through walls. For AOEs, it rarely does. We need to change that behavior before release.
Group movement
As for me, I spent most of the last week staring at squiggly lines diagrams like these:
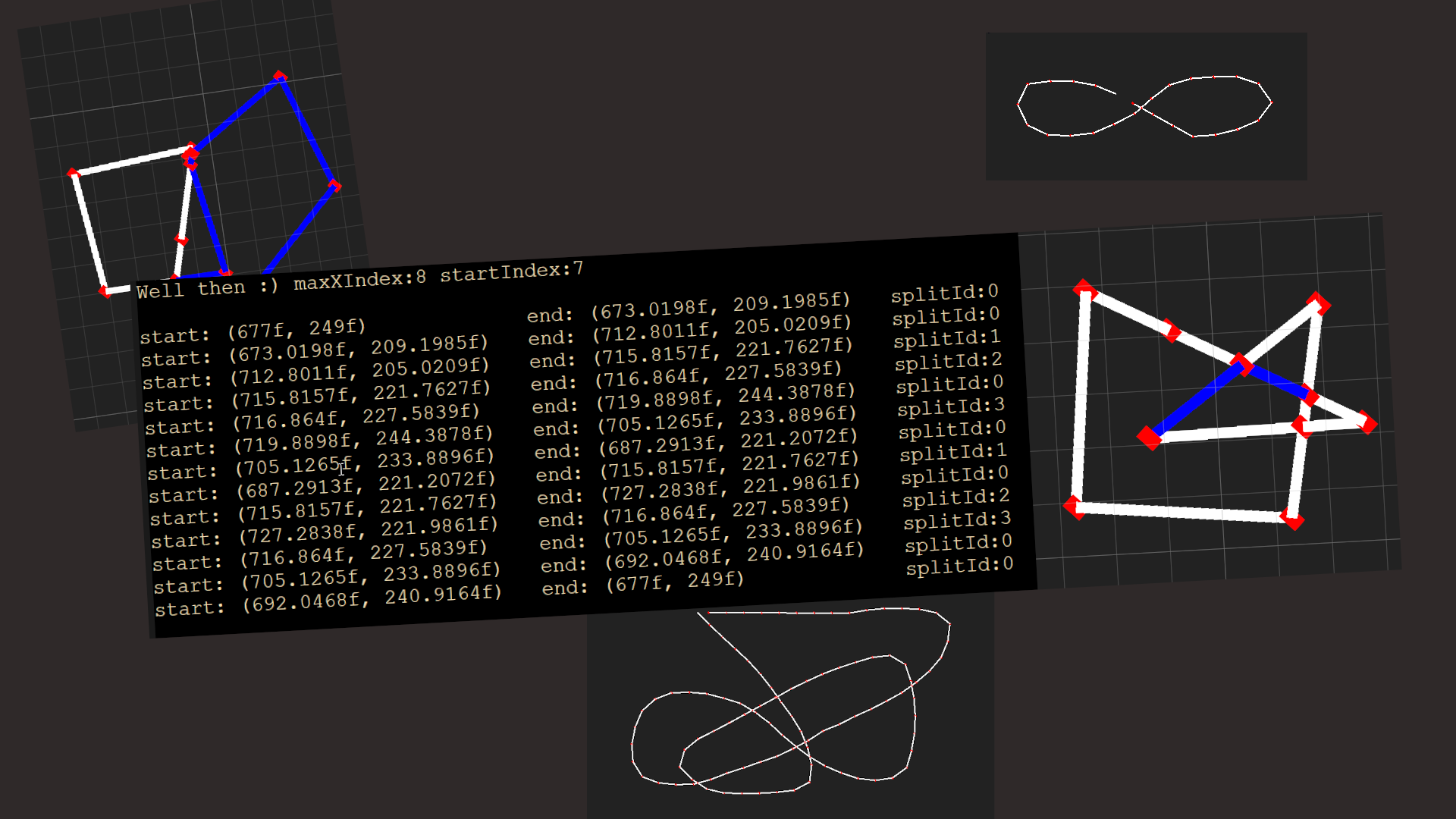
My goal has been working on a good way to divide them into simple polygons (see my last dev log for the overview of what we need this for).
I have an approach that is quick and works in many cases…

…but not all of them

The above gif shows two holes between the two polygons. Now, this isn’t uncommon. You are probably very familiar with what happens in graphics applications when you use lasso-select and self-intersect a bunch.

This behavior sucks for TaleSpire though. Actions like this should have 100% predictable behavior and trying to anticipate self-intersection behavior should be unnecessary.
This means I need to have another go at the polygon decomposition. However, what we have is plenty good enough for continuing with our experiments, so I’m going to leave it for later.
The next step is to write the ear clipping code that creates the mesh from the simple polygon. I’m back working on AOEs for now, but I think I’ll be done there soon.
Wrapping up
Well, that is probably the best place to leave it for now.
Hope you are having a great week. Hope to see you in the next dev-log.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 349
Heya folks!
With AOEs in Beta, and Ree working on the visuals, I have turned to the next feature we want to ship: group-movement.
A good while back, Ree got this feature pretty much to the finish line. We were just missing a selection method that felt good. For our tests, we used the same rectangle section tool from the building tools.
As much as you lovely folks tried to tell us the selection would be fine, we are still very stubborn about the feel of TaleSpire, and so you’ve had to wait. More recently, however, we think we’ve figured out how to make a pixel-perfect lasso tool that updates in real-time. So we are currently working to find out if it’s correct. The general idea is that we can render the on-screen creatures to the picking buffer, reusing the depth buffer from the scene render. By setting the depth test set to “equals” and turning depth-write off, we early out of all hidden fragments (which helps with performance).
I’ve tested the rendering portion, and it’s doing what I expect, so I’ve turned to the lasso itself. We need to make a mesh that is like this…

…but filled in. This means triangulating an arbitrary polygon. Luckily there are techniques for this, such as ear clipping (the linked video is ace) but many only work on “simple” polygons. Simple, in this case, means no “holes” and no self-intersection. There are algorithms out there that can handle these complex cases, but after drawing a lot of squiggles in my notebook, I think Ι can make something more efficient[0]. That is my goal for the next few days. After that, it should be mostly copying and modifying existing code to get the results back from the GPU.
That’s all from me for now. I’ll be back when there is more to show :)
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] In the game, we are building the polygon incrementally over many frames and don’t have to handle “holes.” So I think a decomposition to simple polygons can also be spread over many frames. After that, the ear clipping approach can be applied.
TaleSpire Dev Log 348
Heya folks,
Work on AOE[0] feature has been going well. In fact, if all goes to plan, we should have a Beta in your hands by the weekend.
The goal for the Beta is to test the basic functionality. What we have is as follows:
- While using a ruler, a GM can press a key[1] to turn that ruler into an AOE
- Players and GMs can use the Tab key to view the names of the AOEs
- GMs can right-click on the handles of an AOE or bring up a menu that lets them delete or edit the AOE
- AOEs are saved in boards.
- They are also included in published boards.
For now, the visuals of the AOE are exactly the same as the rulers. This will probably change before the feature leaves Beta.
Yesterday was spent making a fast way to place and update the names above the AOEs. The result is a slightly generalized version of the code I use for bookmarks and creatures. Now that I have this, I’d like to go back and try replacing the creature and bookmark implementation with this new version, but that’s a task for another day.
As you can see, the names in the above videos are just dummy values. Today I’ll be adding the code for setting and changing names. I expect that to be a quick job so getting the Beta out by Saturday seems feasible.
I guess we’ll know soon enough!
Until next time,
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] AOE = area of effect [1] The keybinding is configurable in settings