From the Burrow
TaleSpire Dev Log 282
Heya folks. For the last five days or so, I’ve kept saying to myself that i’d write the next dev-log “as soon as I finish this task,” aaaand here we are :P
So let’s dig into some of the stuff I’ve been poking at.
Feature-Request Site
The #feature-requests channel on our discord has been incredibly useful. Still, a while ago, we gained enough of you lovely folks that we’ve outgrown it as a viable solution for managing feature requests.
Since then, the moderators have done a ton of work exploring options we have for moving that somewhere more appropriate. We are not opening it today, but we’ll soon be moving it and the roadmap over to HelloNext.
We’ve going through every request from talespire.com/faq and the last feature roundup and entering them into that system.
We are not ready yet, but we will put the #feature-request channel in read-only mode when we are. This way, nothing is lost, but new folks won’t be confused about where to post.
We will have more news about this in the coming weeks.
Bookmarks
Back in the code, I’ve been experimenting with bookmarks. Bookmarks are markers that have been given a name. We want you to be able to easily search and jump to any bookmark in the campaign.
I started with making a basic panel to hold the bookmarks so we could start experimenting with behavior. In the pic below, neither the logic nor the graphics are final. But you can see I was messing around with how to visualize bookmarks in the current board.

From this, we decided that the bookmarks should be integrated into the boards panel, with the boards acting like folders. You can see the WIP of this in these images.


This is going well. The next step is to add some new functionality to the server to support things like campaign-wide bookmark search.
Internal systems documentation
Along with this, we’ve also needed to start looking at housekeeping.
We have a growing codebase, and to keep things running smoothly, we need both Ree and I to be able to drop in easily and get working. To help with this, we are making some internal documentation.
While doing this, I’ve found stuff that I’m reluctant to document as they require some cleanups. Some of which have been on my todo list since the release.
To that end, I finally dove back into the serialization code and got the API to a nice place. This touched a large amount of code and so that it took a couple of days to update everything and get it passing all the tests again. We really don’t want to start breaking boards at this point.
From now on, I’m going to try to put aside one day a week where I only work on things that benefit us behind the scenes.
To get good performance, we have had to make alternatives to some of Unity’s systems, and our versions lack the visuals and tools that make working with them enjoyable. Focusing here will make our lives easier and thus make it easier to get fixes and features to you.
NDI
One day last week, I needed a change of scene, so I decided to look back into ndi support. I was hopeful that my knowledge of Unity has increased since last time, and I thought I could get it closer to shippable.
Alas, the plugin now requires .NET Standard 2.0, and for various reasons, TaleSpire uses .Net Framework 4.* (Damn Microsoft’s naming schemes to the pits of hell). Switching TaleSpire to .NET Standard 2.0 broke several things[0], so suddenly, this task stopped being a nice way to unwind.
This will have to wait for another day.
Unity on Linux [WARNING: NOT OFFICIAL SUPPORT - PLEASE READ BELOW]
Multi-platform support is NOT coming yet. But it is our long-term goal, and when it does, we want all your mods to work there too. Part of this means getting an understanding of how Unity’s AssetBundle format works on these platforms.
Also, I prefer working on Ubuntu, so it was a great time to try out the Linux port of Unity.
The tests went well. I was able to get a rather broken version of TaleSpire running on Ubuntu and prove that we can use AssetBundles that were made for Windows in the Linux build (because of how we handle shaders internally). Next, we’ll have to do a similar test on macOS and see how it behaves.
There is still a lot of work to do to make the build work properly. I’ll mention just two for now.
We use Window’s ‘named pipes’ feature to handle custom URL schemes. We will need to make something similar. This was a real pain to get working on Windows, so I expect no less elsewhere :P
The pixel-picking system makes use of a custom c++ plugin we made to be able to get results back from the GPU without hangs. We will need to write variants of this for each platform.
Now, I’m sure a few of you have been yelling at the screen to just use wine/proton to support Linux, and we are well aware of these. TaleSpire seems to work great out of the box with Proton, except for the custom URL scheme. This, too, can be fixed, but we’d want to fix that wrinkle in the experience before we’d consider supporting it.
Also, we simply aren’t ready to take on the extra work that supporting multiple platforms requires. We will get there, but it’s something for another day. For now, I’m excited to see the path ahead.
Bugs
As usual, there are also bugs to be looked at. We still have cases of board corruption being reported, and so these take top priority. Not all of them turn out to be corruption, but they still are worth squashing.
I think that’s most of it
We naturally have plenty of other things brewing. This post was just my stuff, and the rest of the team has been just as busy. We also have things cooking that we aren’t ready to talk publicly about. It’s gonna be fun :)
Until next time folks,
Have a good one!
[0] Including the custom URL scheme and some HTTP connection stuff
Talespire Dev Log 281
layout: post title: TaleSpire Dev Log 281 description: date: 2021-06-23 10:09:09 category: tags: [‘Bouncyrock’, ‘TaleSpire’] —
Hi folks.
At the time of writing, I’m about to push an update. In the changelog, there is a line that looks like this:
This patch also contains a change that will hopefully improve performance for machines with high numbers of cores.
I wanted to talk about this change as I think it will be interesting (and maybe counterintuitive) to some non-programmers out there.
Here is the change: I’ve told TaleSpire to use fewer cores.
!(dun Dun DUUUUUUUUn)[/assets/videos/gopher.gif]
Let’s set things up so I can explain why.
So TaleSpire uses a job-system. A job-system (in this case) is something that you give a chunk of code to run, and it runs it on one of your machine’s cores[0].
This is good as we can queue up lots of work and let the job-system work out where and when to run that code. This often gives us nice performance improvements as we are using all the cores on our machine.
As a programmer, your job then involves writing code in such a way that it can be run concurrently. For example, let’s say you work in catering and you need to make 20 of a certain kind of sandwich, and you have 5 workers. In this case, the ‘job’ is making one sandwich, and with a bit of orchestration, we can have all 5 workers making sandwiches concurrently.
Recently I upgraded my PC to keep up with how TaleSpire is growing[1]. I was very lucky to get a Threadripper CPU with 24 cores[2] which you would think would make TaleSpire much faster, but in some places, it didn’t. In this next image, you can see that running the physics got slower.
!(overhead)[/assets/images/overhead.png]
Weird right?! The version running on more cores took over three times longer.
Why? The overhead of orchestration.
Let’s imagine our sandwich situation again, but let’s say we broke down the steps of making a sandwich even further. So one job is to fetch the bread, another job is to butter the bread, another job is to bring the filling, etc. Now, imagine we still need to make 20 sandwiches, but we have 100 workers. As you can imagine, things get messy.
Not only does instructing each worker take time, but the workers also share access to limited resources (like access to the one fridge). Furthermore, the workers need to sync up to actually assemble the sandwich, and this coordination also takes time.
This is a long way of saying that, at some point, the overheads of managing workers can outweigh the benefits of having more. And so we come right back round to the physics situation.
I like that we can spread the physics work over multiple cores, but I need to limit how many so we don’t get lost in the overhead. As I don’t yet know the right way to restrict the worker count just for the physics, I’ve temporarily lowered the max worker count.
This will be increased again when I understand how to control this stuff for each system I care about.
That’s all I’ve got for this post. Thanks for stopping by, and I hope you have a great day.
[0] This is an approximate description. We could say it runs it on one of the worker threads. But given that they are locked with affinity, and we don’t want to have to explain software threads, this will do for now. [1] I run dev builds of TaleSpire, which gives more information to me, but the cost is that these builds run much slower. [2] With hyperthreading, that’s 48 logical processors
TaleSpire Dev Log 280
Heya folks,
We are currently working on the last things before we’ll be ready to ship the ‘props on bases’ feature. This is a super exciting one, and I expect it to be used and abused in very interesting ways.
Last night, however, I took a little detour to look at a bug that has been around since the chimera build. Lights that turn off when you get close to them.
Our lights attempt to be the same as the standard Unity lights, except without using Unity’s GameObjects for performance reasons. This means that, like Unity’s lights, ours use a different material depending on whether the camera is inside or outside the light’s area of influence[0].
The lights seemed to be turning off because we were not always updating the material at the right time. Let’s get into the weeds a little.
To avoid using GameObjects, we use CommandBuffers to render the light meshes at the right point during the frame. For dynamic lights[1] we have to rebuild the queue each frame[2] as the light’s position or properties are being changed, but for static lights, it’s different. Static lights, by definition, aren’t changing, so we have a separate CommandBuffer for them which we only update when the board is modified.
An important detail here is that you can’t just update an element of the CommandBuffer. It has to be cleared and rebuilt
This approach has a very dumb mistake in it, though. When the camera moves, the material the light is using might need to be changed. I’m not sure why I didn’t notice that while writing the system, though I expect I was rushing for Early Access and forgot. Regardless, this needed fixing.
Internally the TaleSpire board is split into zones, and we apply operations across these zones in parallel. Each zone communicates with the light-manager to enqueue its lights into the CommandBuffers of lights to be rendered[3]. What I tried to do was have one CommandBuffer for static-lights per zone and then only update them dependent on the camera position[4].
This worked, but I noticed something annoying when I looked at the profiler. The update time for the static lights was fine, but the rendering took a significant hit.
This is my test scene. It’s 4096 static lights. I’ve not added anything else so as not to confuse things.
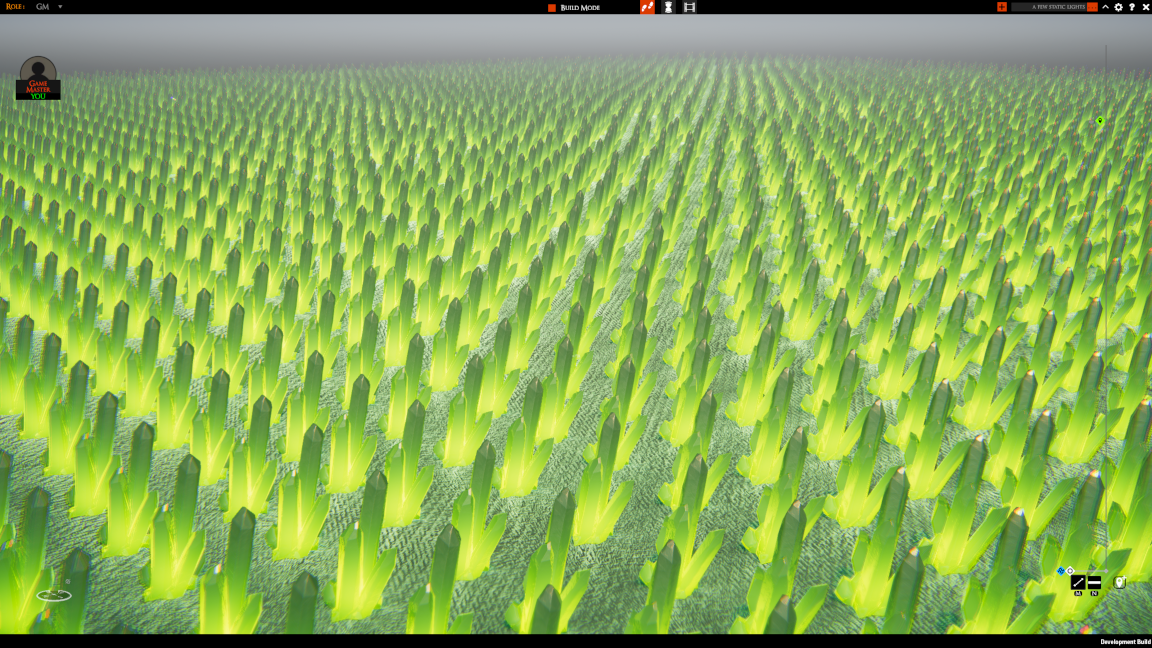
Here is what we have for light rendering before the fix (so with one CommandBuffer for static lights):
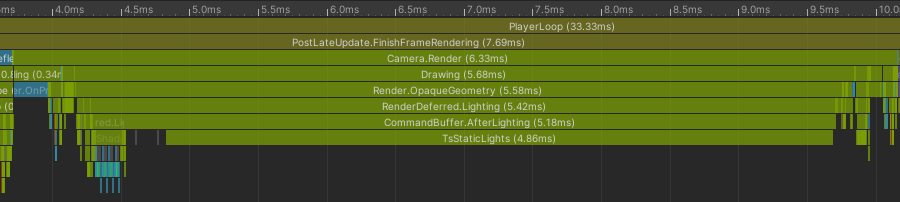
And here is the same scene, same camera angle, etc, but with one CommandBuffer per zone:

Doesn’t that suck? Even though the amount of work to do is the same, the overhead from many CommandBuffers made things take significantly longer[5].
I still hope to ship the fix for the lighting bug this week, but I’m going to have to look at it after we ship the ‘props on bases’ feature, as it’s clear I’ve got more experiments to do.
There is still plenty to try. What I’ll probably start with is switching to three CommandBuffers. One for dynamic lights, one for static lights from zones that have had to update recently, and a final one for static lights from zones that haven’t been updated in a while. This way, we minimize the overhead from CommandBuffers while also minimizing the number of lights being rewritten to the CommandBuffer each frame.
Alright, that’s all for now. Can’t wait to be back with more.
This is gonna be a fun week.
Seeya!
[0] More or less. This is close enough to be able for this discussion. [1] Dynamic lights are lights being moved or animated by scripts on the tile/prop [2] Yup, there are places we can optimize here, but this log skims over that detail as we are focused on static lights [3] This isn’t the exact architecture, so don’t sweat these details. We just want to talk about the issues. [4] Of course, this is really about the camera position in relation to the area influenced by any of the lights in the zone. [5] I’d recommend not caring too much about the wall-clock time in this case. Of course, 2 ms matters, but this is also running on a fast CPU. What really stings to me is that it was significantly faster before.
TaleSpire Dev Log 279
While we work on the ‘props as creatures’ feature we talked about the other day, I’ve switched tasks to look at some bugs hitting folks in the community. To that end, the next patch will have the following:
- A fix for a memory leak in copy/paste
- Cases where exceptions should have caused TaleSpire to leave the board but didn’t.
- Fixes in the board loading code to make it more robust
- A fix to the campaign upgrader, which was having errors
The campaign upgrade issue was a regression caused by me when I changed how some internal data was structured. I should have double-checked the upgrader before pushing.
I also am tracking another regression that is causing issues with picking tiles and props when in certain positions. I’ve got a solid idea of where these issues lie, so I’m hopeful that I can get this fixed today.
Once that is done, I’ll push out a patch.
Hope you are all doing well,
Peace.
TaleSpire Dev Log 277
Heya folks,
For the last few days, I’ve had an urge to work on bugs, so I put down the creature improvements and dipped back into the issue tracker.
The first bug I ended up fixing was one I spotted while working on other things. It turned out that long error logs were not being truncated when uploaded to the server, which caused the transfer to fail. This was a nice quick one to fix.
Next up, I was curious about a long-time bug where static lights would flicker briefly when placing new static lights[0]. The code was fiddly as the way I was iterating through the assets was good for performance but not for readability. In the end, it came down to some mistakes where I was writing the GPU data for the lights[1].
The last thing I did yesterday was to fix a bug in hide-volumes where, if you make them too small in any dimension, they became unclickable. This was simply that the physics engine doesn’t handle boxes where the size in any given dimension is zero. I’ve modified the tool so that you can’t make hide volumes that small anymore.
Today I focused on one specific bug. As the excellent report shows, there are cases where copying large slabs caused the game to crash. A board was provided, which, along with the instructions, made it trivial to reproduce the issue. The problem came down to an oversight I made while trying to reuse code.
The batching for slabs is heavily based on the code for batching a single zone. This worked great, but I had missed the fact that the batches allowed a max of 13000 instances per kind of object. This was far more than is needed per zone, but for certain slabs it’s not hard to go over that limit (50x6x50 single grass tiles, for example). To handle this, I wrote a new struct where the internal array did not have this limit at the cost of some additional allocations.
All these fixes are now merged, and so they should ship in the next update.
Until next time, Peace.
[0] Static lights are ones that do not animate. The crystals are good examples of this. [1] I tried to expand on the explanation here, but it got too unwieldy to explain without lots of surrounding code
TaleSpire Dev Log 276
Hi folks!
After the Norwegian national holidays, I poked around fixing the bugs which caused the board corruption that hit some folks a few weeks ago. Part of the fix involved adding an extra piece of runtime data per tile/prop in the board.
This did not affect the size of the saved data, slab size, etc. However, as this did mean an extra 12 bytes of data per tile/prop at runtime, I spent a while looking at reducing that. From now on, we’ll refer to the tile/prop as a placeable.
The data in question was the world position of the origin of the placeable. Positions of props are snapped to the nearest hundredth of a unit, so we don’t need the full range of float values. This means we could opt for a different representation. Half-float does not have the precision we need when values are greater than around 1000, but we could multiply the value by 100 and cast to and int (essentially storing as fixed-point), the values happily fit within the range of a short so that would take the size increase down to 6 bytes.
Also, all placeables exist inside zones, so we could store the position relative to the zone. A zone is a cube 16 units across, so that means we only need 16 * 100 = 1600 values per component or 11 bits per component. That’s ~5 bytes for the three components.
I also looked into other runtime values stored placeable, which could be stored differently now that we have the origin position per placeable. However, I won’t overload this update by going into all that.
After all the poking, I could make things smaller, but it didn’t result in more placeable data per cache-line, so I didn’t think the extra costs would be worth it. I’ll definitely re-examine this when I switch to more of an SOA format for some of the data.
Other than this, Ree and I took some time to plan some changes to the persisted per-creature data. We are adding the data for a bunch of features in one go, even though it’ll take a while to implement the rest of each feature. This is because upgrading the file format takes a lot of care in order to avoid screwing things up.
We will be adding the data for:
- Persistent emotes
- Four more stats per-creature n
- The ability to add props to bases and use them as creatures
- Polymorph
- Extra color data for things like chat bubbles
You’ll be hearing a lot more about those as work continues :)
Have a good one folks!
TaleSpire Dev Log 274
Hey again folks!
Progress is slow but steady for me this week.
On Monday, I started adding support for multiple asset-packs to TaleSpire. This is required for future modding support. We knew this was coming, of course, and so a lot of the work had already been done. The main task was deciding how the asset-pack id would be stored in TaleWeaver, writing it into the correct places in the index, and updating TaleSpire to search for packs in a given directory and load them.
The TaleSpire part will still be improved as we don’t want to load all packs the game can find immediately. Each campaign might be using different packs, and loading unnecessary ones waste local and GPU memory.
Other than some board restores, my focus for this week is on the layout code in TaleSpire. The runtime data has a known issue that can make it very fragile to mistakes in asset-packs. The wrong change there can currently corrupt boards. It’s been easy enough to tiptoe around it for now as it’s only us providing assets, but this is unacceptable for modding, so it needs to be fixed. [0]
Naturally, this touches a whole mountain of code, so it’s going to keep me busy for a bit, but it’s gonna be a huge relief to get it done.
That’s all for me for today.
Seeya around folks :)
[0] The changes should not have any visible impact to the game or to the board format. It’s only changing how we juggle the data behind the scenes.
TaleSpire Dev Log 273
Heya folks.
I spent the end of the week looking into the bug with markers which meant they didn’t spawn when joining the board.
This went well and allowed me to clean up a bit of the implementation behind the scenes. However, this also meant I bumped into a bunch of other bugs related to GM blocks. I’ve got through a few of those now, with only one remaining that is stopping me from shipping[0].
The patch fixing markers will come soon. One thing that will be missing from the initial patch is that published boards won’t include markers. This will be fixed later shortly (probably later in the week).
I would also like to start hashing the board state that lives in the database (markers, unique creatures, etc.) and skipping the download if the local cache has the latest data. It’s not critical, but every little helps.
In the last update, I mentioned that I was sent a published-board and some instructions to replicate a nasty board-breaking bug. Once I had this, I was able to repeatedly delete parts of the board and then test if the bug still occurred. I was able to get the large board down to a small chunk of tiles that still triggered the issue. I then started seeing something odd. Occasionally the delete would corrupt the tiles, and occasionally it wouldn’t. I slowed down and took more note of how I was following the steps, and I realized that if the selection box only just enclosed the tiles, the delete didn’t corrupt anything. However, if I used a huge selection box that encompassed the slab, then delete would corrupt the slab. This told me exactly where the problem was.
The board in TaleSpire is divided into 16x16x16unit zones. When we apply changes to the board, we often do so in parallel across the zones. A delete typically needs to scan through all the tiles in the zone to see which ones intersect the selection bounds. However, if the entire zone is enclosed by the selection bounds, we know that every tile must be too. This allows us to implement delete more efficiently in those cases. The bug was in this optimized version of delete. It wasn’t an exciting bug, just a simple case where I wasn’t incrementing an index at the right time[1], but plenty enough to cause havoc.
I then had to update the tests. First, I added a test for this specific case. But then I updated the fuzzer as that should have been capable of finding this on its own. The problem was simply that the bounds for the deletes being generated were not large enough in all dimensions to enclose zones[2]. With these fixes, we are now covered if some regression were to recreate this problem again in the future.
That’s all for now, folks. I’m excited to get the marker fixes out as I’d really like to get working on the marker panel soon.
Peace.
[0] it’s a bug which means that if you modify a sector of a board, then the gm-blocks in that sector aren’t synced to other gms when they join the board.
[1] There was a similar mistake in the undo code for this kind of delete.
[2] The model we fuzz against is a 1d board, this meant that we only ever needed thin selection bounds. It doesn’t hurt to use larger ones so we do that now.
TaleSpire Dev Log 272
Hi everyone,
I had somewhat of an extended weekend as I had forgotten I had some real-life things happening on Monday. All in all, it was lovely to decompress few days, and I’m stoked to get started again.
And we are in luck. A wonderful member of the community has managed to create a board that reproduces one of the nastiest bugs we have right now. For a long time, there has something that can trigger data corruption when cutting a board region and then undoing that cut. However, what has been confounding us is that it has not been possible to replicate the problem consistently. Several lovely folks have got us close, but there was always something that made it very trial and error.
We now have been given a published board with three-step instructions on how to break it.
Needless to say, this now makes this bug tractable. The start will be a lot of trial and error as I try and trim this board down to the smallest thing that still shows the bug. Then I’ll dive into the data and see what is going on.
Board corruption bugs are the ones that upset me more than any others, so I can’t wait to squash this one.
Hope you are all doing well!
Ciao
p.s. In writing this, I’ve already been able to find out that the issues are not related to cut specifically, but delete. I’ve also halved the size of the board that produces the issue. We are on our way :D
TaleSpire Dev Log 271
Heya folks,
A quick update for today. It’s been a great week for bug fixes and content.
The art team just landed the ‘Siege of the Cackling Horde’ pack. I saw the trailer the same time as you folks, so I was giddy :D Sometimes being involved in a thing means you have seen the whole messy process of bringing it to life, and it’s hard not to see the flaws. Just seeing the result is wild as you get to be surprised by it all. I love it.
The next bugs I’ll be tacking are around markers as they are not syncing correctly at the moment. I hope to have them working again early next week.
I’ve also got a server patch to finish, improving how we handle changelogs and client error logging. The latter is just about organizing the data we already have, but it should mean I can track down erroring boards without having to bother as many players.
However, first, it’s the weekend. So I wish you well and will see you next week with more fixes and features!
Peace.