From the Burrow
TaleSpire Dev Log 390 - Symbiotes Documentation
Heya folks,
Part of getting ready for the first Symbiotes release is finalizing the documentation. Or rather, I should “was” as that is now done!
We know that a bunch of you in the community are developers who might be interested in peeking at this even before the feature is available, so we have put the docs and examples public early.
You can find the documentation at https://symbiote-docs.talespire.com/ and the examples are at https://github.com/Bouncyrock/symbiotes-examples
The documentation is also a valid Symbiote. That can be found here: https://github.com/Bouncyrock/symbiotes-docs
We have intentionally not added calls that modify board or campaign state in this first API version. That allowed us to avoid the impact of such changes on the backend. However, we will be significantly expanding the API into those areas in the future.
Major props go to @Chairmander, who has been driving the entire documentation process. Left to my own devices, the first version would have been much more bare-bones!
You should also see a little patch going out in the next 12 hours. This will be the patch that adds UI that we will use during future maintenance periods.
Well, that’s all for today!
Ciao
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 389
Morning all!
It’s Saturday, so this will just be a short log.
Yesterday I completed the implementation of the maintenance UI. It needs a little more testing, but I expect to be shipping that Monday. This won’t affect you yet, but we’ll get to use it during the next server upgrade, which is also coming very soon. Pavel has done fantastic work taking the very basic thing I had built and putting us on the road to serious infrastructure that will stand up to the tests ahead.
I also got to chat with some lovely folks in the broader ttrpg community both about Symbiotes and what they were up to. it’s always a blast to see how much is happening out there.
Alright, time to get some work done in the garden.
Ciao!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 388
‘Allo folks.
Yesterday I continued working on the update UI and some details with Symbiotes that drag us that last little distance towards release.
Symbiotes has to be the most feature with the most creep we’ve ever had. It started with “let’s just get a web-view in here,” evolved to “let’s add a basic API in here so creators can interact with TS” to a place where we were really drilling down into the details of the programmer’s experience, writing extensive documentation, and making something we can truly support and grow over the years[0].
I’m much happier with this result than I would have been with the original plan, but I regret how much time it took. However, we are wrapping up the last few outstanding things:
- Finishing the v1 UI
- Prodding the legal folks to get the TOS updated.
- Fixing little bugs and annoyances as testing reveals them
We have also been chatting and working with other creators to be sure that the first version is helpful for real projects. I’ll talk more about that another day.
Anyhoo, back to what I was actually doing.
First off, I expanded the manifest to support icons for the symbiotes. The manifest is a file you write to tell TaleSpire about the symbiote, including what features to inject.
Here is a sample manifest:
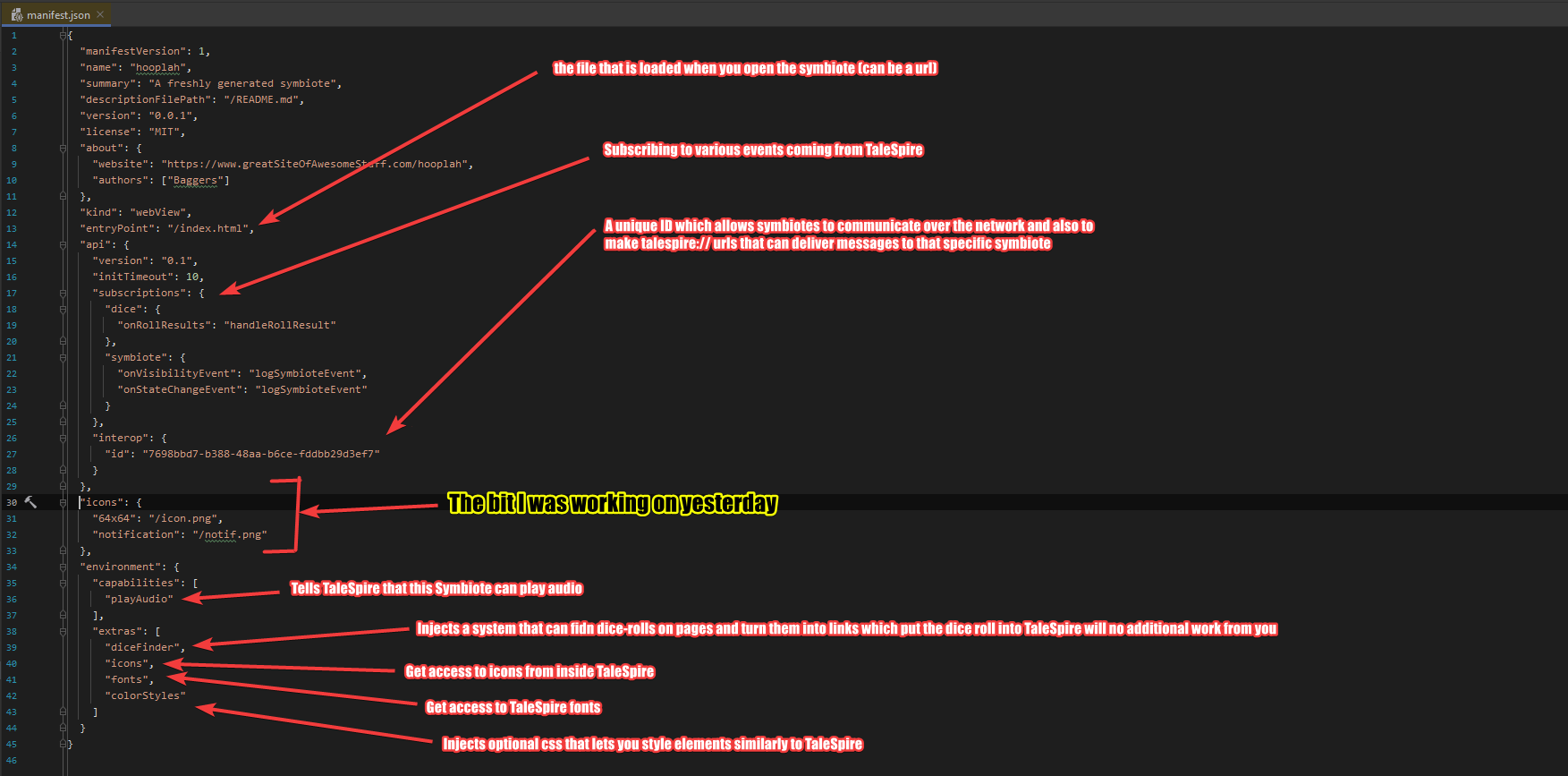
As you can see, I was focused on icons. We currently support a couple of kinds:
- A 64x64 pixel icon which is used for the symbiote in menus and such
- A smaller, greyscale icon that will be used for notifications
We can add more size options in the future as we need those, whether for nicer integration in mod-stores or higher DPI displays. But for now, this will work just fine.
I also fixed a bug in the formatting of talespire:// URLs generated by symbiotes. Let’s take a second to talk about that feature.
You folks probably have already seen that external programs can do certain things via talespire:// URLs. Importing boards, setting the dice tray, and so on have URLs that integrate with TaleSpire. It’s super helpful, and we wanted you to have that too, so we allow you to generate a URL specifically for your symbiote like this:

You can then put whatever text you like after the final slash (as long as it’s a valid URL) and it will be delivered to your symbiote when the URL is processed.
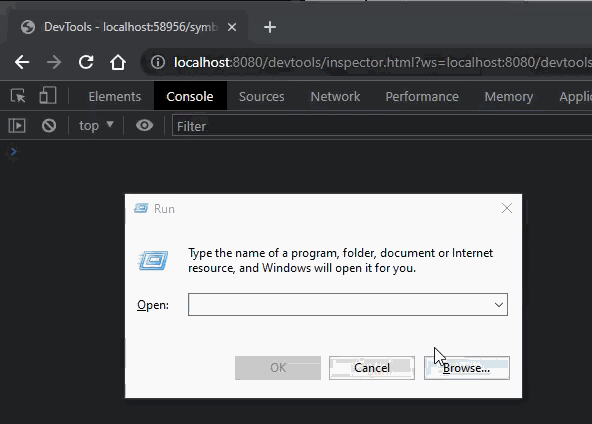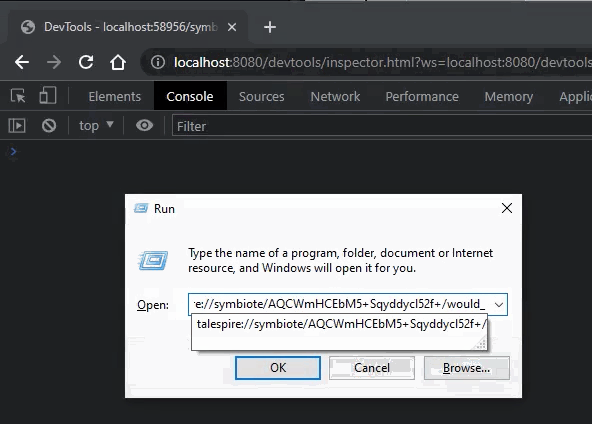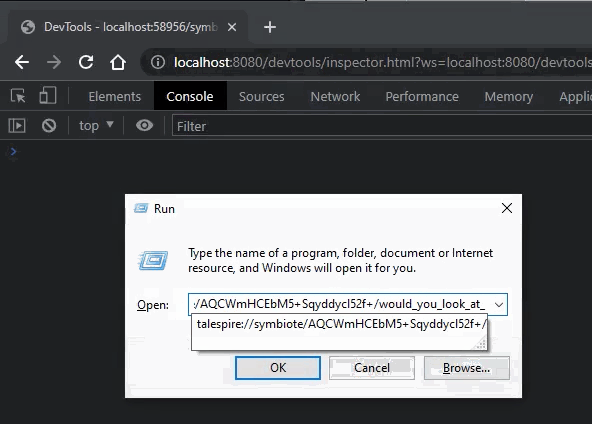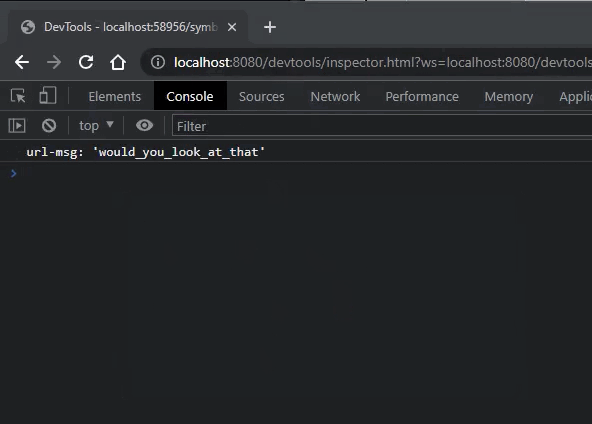
The console you are seeing is part of the dev tools in Chrome. When you enable dev mode in the Symbiote settings, you can connect to and debug your symbiotes trivially. I’ll talk more about this in another dev log.
Right! I gotta get back to work, so I’ll stop writing for now.
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] Not just supporting more features but supporting entirely different kinds of symbiotes.
TaleSpire Dev Log 387
Hi folks,
I’ve been enjoying a dip out of public view for the last month. I had two weeks off (which I spent fixing up stuff at home), and then I’ve been quietly plugging away at TaleSpire. It’s been nice, but I’m back to the dev logs again.
A lot has been happening, but today’s dev log is short to get me back into the rhythm.
Yesterday was spent working on UI, which will show before and during maintenance. We’ve got a lot of stuff to ship this year, both front-end and back-end, and we want to work towards that being less janky.
It’s nothing exciting, but here is the ticker that appears periodically before maintenance to let you know what is upcoming:
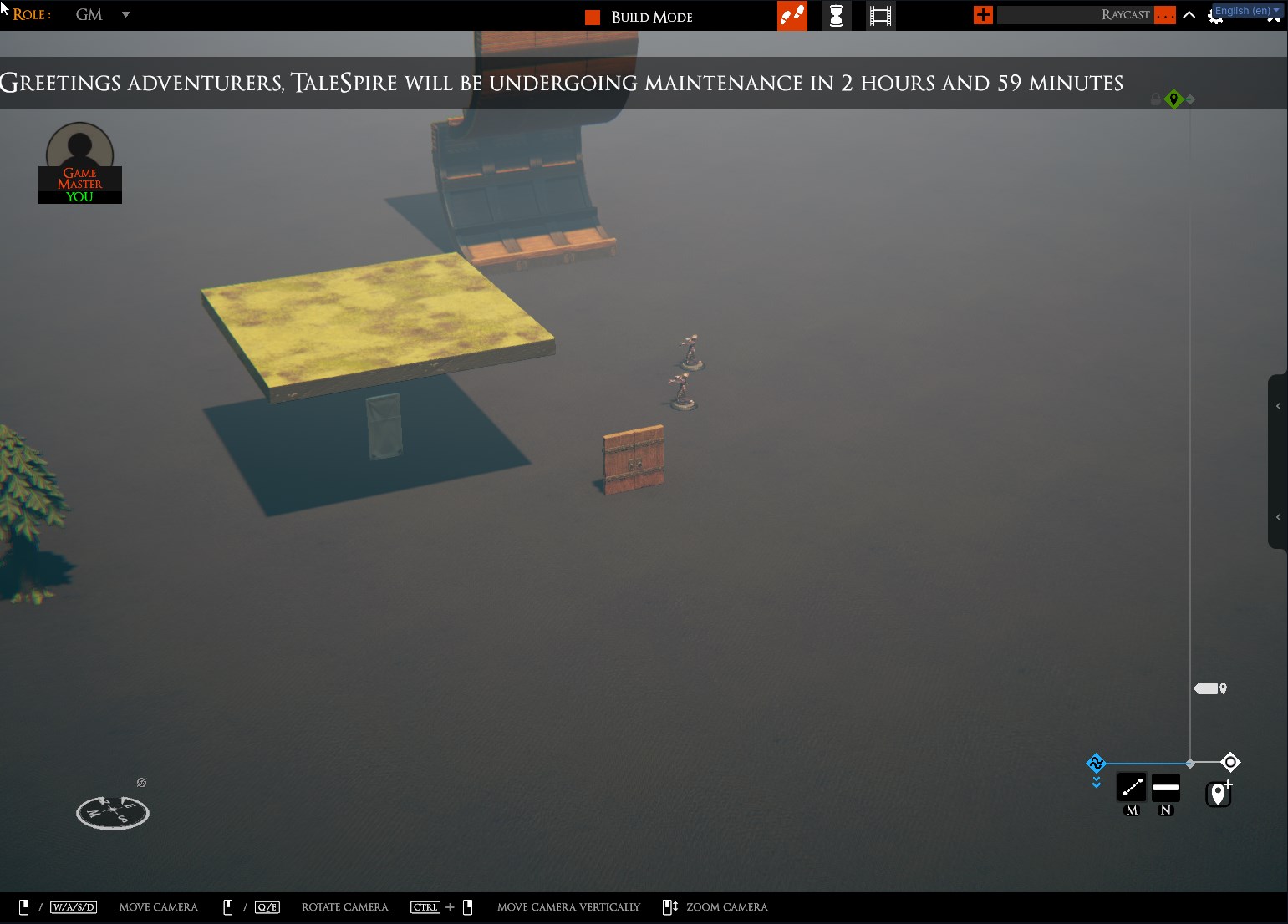
The ticker shows briefly once an hour for the few hours leading up to the event. It transitions to a permanent message bar in the last 20 minutes and then finally into a modal window for the duration of the update itself.
Naturally, there is also UI on the login screen.
Symbiotes are dangerously close to being released. We will have an alpha as soon as we can pull together the last UI and legal bits. If you are wondering how it took so much longer than we were saying previously… yeah, that’s a tale too. I’ll get that down in a dev-log in this next week.
Anyhoo, I best get back to it.
Ciao
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 379
Heya folks!
I’m back again with an update on what I’ve been touching this last week.
Symbiotes
Chairmander and I kicked off with a long meeting to design the manifest. We took some inspiration from other projects but ensured the file grew naturally in step with what Symbiote features are being used. This amounted to talking through user stories, though we didn’t think explicitly about that then.
After the designing, it was time to work!
I knew quickly that if a Symbiote failed to load, I wanted some UI in the panel to show that. I’ve previously mentioned that I wanted to support different kinds of Symbiote (as in, not just web-based ones), and this felt like an excellent place to use another type.
Knowing what I wanted and getting it were two different beasts, though. I spent many hours going in circles until I found an approach I liked. The details of the solution aren’t particularly exciting. Still, the upshot is that we can now support not just different user-made symbiotes, but we can technically support hot-loading the infrastructure for entirely different kinds of Symbiote. This won’t matter for a while, but I’m happy to have that worked out.
We are still improving the API Symbiotes have access to. As of today, we have calls for the following:
- fetching the initiative list and the currently active member
- sending chat messages both as players and as creatures
- putting dice into the tray
- fetching info about the currently active ruler
- fetching a slab string based on the current selection
- putting a slab into the hand (switching into build mode if necessary)
- unpacking slab strings to binary representation
- packing binary slab representation to slab string
- getting the data size of a given slab string
- sending a network message to the same Symbiote running on other clients
- fetching the ids of any parties
- fetching the ids of creatures in a given party
- fetching info about the active campaign
- fetching the board list for the active campaign
- fetching a list of the bookmarks in the active campaign
- fetching the distances units for the active campaign
- fetching the names of creature stats used in the active campaign
- fetching a list of the players in the campaign
- fetching a list of the players in the board
- fetching the id of your player
- checking if a given client-id is yours
- fetching info about a given player
- fetching a list of the connected clients
- fetching the id of your client
- checking if a given client-id is yours
- fetching info about a given client
- fetching the list of loaded asset-packs
- fetching info about the asset pack (including all tile/prop/creature info)
- fetching the list of unique creatures
- fetching a list of creatures owned by a given player
- fetching a list of currently selected creatures
We also let you subscribe to events such as:
- unique creature created/deleted
- dice roll results
- slab copy events
- asset pack loaded/unload events
- client join/left board events
- player joined/left campaign events
- player permissions changed events
- initiative list changed events
Next up, I’ll be experimenting with exposing a picker tool that sends the kind and id of the picked thing to the Symbiote.
We also will be handling documentation generation soon. With that and another big pass on the API, we will be nearing something we can ship.[0]
Community mod repository
I just put this section here to reassure you that slab sharing and mod.io integration have not been forgotten. They have had to wait a bit as pushed to find out what the Symbiote feature needed to be.
Performance
Ree is working on a cool feature that requires scanning over any tiles or props in a given area. We have some code for this that is used by the hide plane. However, it was not currently Burst compiled due to limitations on how generics work in HPC#.
I changed the logic so that a caller-defined visitor was passed chunks of data. The caller could then return jobs that processed these chunks with the help of some methods on the chunk.
The result was a significant performance improvement to the hide plane and code that could be used in more cases.
GameObject Alternative
The perf work above got me very motivated for more. So I sat with a pad of paper and started trying to design a jobified alternative to GameObjects we could use in some places.
I’m not looking to cover all the cases GameObjects do, but I want something that is more familiar than ECS (and more compatible with our setup) while being easy to integrate with jobs.
Not much to report here yet, but you’ll be hearing more about this in the future.
Physics
Next up, I worked on a bug in our physics library helpers which resulted in sphere-overlap checks not working.
My reason for the bug was that, at the time, the library we wrapped had no documentation, and the name of the field I was incorrectly using was bafflingly named[1]. That’s my excuse, and I’m sticking to it :P
macOS News
Some good news on the macOS front. The bug that has been blocking us has been fixed in Unity 2023.2 (which we don’t use) and is in review to be released in 2021.3, which is one we can upgrade to[2].
This is exciting! When that lands, we can finally get a good look at what we have and work out how to get the alpha of macOS support into your hands.
Backend
Work progresses rapidly on the backend. I was in some discussions about how we will be handling certificates and looked into our options. Nothing interesting to report, but it took some time, so it gets a spot here!
Wrapping up
More than ever, my dev-logs fail to capture the breadth of what is going on behind the scenes. Seeing so much moving from backend code stuff to community outreach is a joy.
Until next time!
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] You may have noticed that no calls change the state of the game directly or require server requests. This is very intentional for the first version. We will look into state-modifying functions in future updates to symbiotes (an example of such a function would be setting the initiative list)
[1] The field is called MaxFraction. Normally it holds a fraction of another distance. However, in some cases, this same field holds the distance directly and not a fraction. Very annoying.
[2] Those not in software development might wonder why we can’t just upgrade to 2023.2. The answer is that changes between major revisions can be substantial, so while technically we could switch, it means putting a lot of time into repairing systems broken by those changes. Also, software always has bugs, so we would be trading a known set of bugs for an unknown set, so the time it would take to get back up to speed is uncertain.
It’s very likely that we will make that jump eventually, but we will let you know when, as that will likely stop us from shipping new features for the duration of that transition.
TaleSpire Dev Log 378
‘Allo!
The latter half of the week has been 100% focused on Symbiotes.
In my last post I talked about starting to make a code generator that would take a JSON spec for the API and generate the C# and JS plumbing code required for communicating between the WebView and TaleSpire. That is now working, and it’s such a help.
It all but removes a class of user errors from the interconnect code as the boring stuff is generated. This also makes having slightly tighter but ugly encodings easier, as you don’t need to update all the plumbing code directly. Also, by generating C# structs, we get type-checking, further reducing the number of ways for me to mess up[0].
Once the generator was working, I was able to write the implementations for about a dozen of the required API functions for the first version in a couple of hours. This really reassured me that it was worth the work.
After this, I merged the slab-repository branch into the Symbiotes one. This is because one of the Symbiote API functions allows you to get the slab string for the current selection, and some of the work on the slab branch made that much easier.
We then ran into an issue we knew was coming: sometimes, the user’s JS can load in before the TaleSpire API has loaded. I added an option to the Symbiote manifest that allows the creator to specify a function that will be called on initialization and updated our setup code to support that.
With this all working, I got a build to Chairmander so he could continue his work, and I doubled back to the C# side of the Symbiotes feature. I spent a chunk of Friday cleaning up code so that all the JS and WebView-specific code lived together. As previously mentioned, I would like to see other kinds of Symbiote in the future, and the cleanup serves that potential future.
The next big todo is working on threading. I also need to get stuck back into slabs.
Anyhoo, that’s enough rambling for now.
I hope you are having a lovely weekend.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] Just as well, I’m a master at breaking code :P
TaleSpire Dev Log 377
Heya folks.
Since we last spoke, I’ve carried on with my main two tasks, slab upload, and symbiotes.
Slab Upload
Slab upload is going well. It’s always nice when something starts feeling like a feature and not a hack.
The progress isn’t exciting to show, though. It’s been things like:
- Side-load the slab data into the cache, so it doesn’t have to be redownloaded
- Show an hourglass cursor when the slab tool is waiting on a slab to download
- Tuning camera behavior so that transitioning in and out of publish mode does what is expected.
- Get tabbing between fields working as expected
- Subtle visual changes to screenshot view to improve the experience
- Add loading graphics to the entries in the community-mod browser to show that thumbnails are downloading
And so on.
I’ve still got a list of tickets to get through to get a good first version, but there don’t seem to be any show-stoppers.
The one (happy) distraction has been helping with the Symbiotes feature.
Symbiotes
Context: Symbiotes is an upcoming feature allowing community-made mods to dock on the right side of the TaleSpire window.
Our first version of this feature supports Symbiotes powered by WebViews[0].
We are providing an API that allows communication with TaleSpire. The messages between TaleSpire and the Symbiote travel over a simple interconnect provided by the WebView.
The code on either side of such a bridge needs to match and, from my experience, are places where simple user errors result in extremely annoying bugs. To deal with that, I prefer to write the API specification as a simple document, which is then used to generate the plumbing code for either side.[1]
And so that’s what I’m making. I have a JSON document specifying types, calls to TaleSpire, and the arguments and return types of those calls. I load that document, type-check it, and produce an intermediate tree of objects which describe the bridge.
Next, I’ll write code to walk over that tree to spit out the JavaScript and C# boilerplate code required.
Some of you may be asking, “why aren’t you using
Given that we are trying to ship mods quickly and that this approach doesn’t stop us from using a different serialization approach in the future, this is the way we are going for now.
Alright, enough rambling for today. Looking forward to sharing more with you soon.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] In the future, I want to explore supporting other languages/environments. [1] This is exactly what we do with our server-side API. The API is represented as an erlang data structure, and from that, we generate C# and erlang plumbing code. It’s been a huge boon.
TaleSpire Dev Log 374
Heya folks!
I’m away from my main dev machine today, so no gifs for ya, but there is some progress.
I’ve got to the point where I can select a region of the board, submit it as a slab to mod.io and bring it back into the game. So the essentials are there. It’s still janky, but I know what I need to do.
We’ve also continued working on Symbiotes (our mods that slot into the right-hand side of the game). We’ve got messages passing between mods and the game, so you can do things like send chat messages, set up dice rolls, and listen to the results.
We are busying ourselves experimenting with the API to work out what is clean and practical to get started with. We have more to show, but as that work wasn’t done by me, I’ll let that person write their own dev log about it :)
We definitely are pushing for mods to be out as soon as possible. Expect to see plenty of logs about this in the coming weeks.
Hope you’re doing well.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire Dev Log 373
Heya folks!
Last week was spent on the backend. A lot is going on, but I want to save that update for when the governmental paperwork for our potential new hire is complete. It’s taking ages.
Work has continued on Symbiote, our modding feature allowing you to dock webview-based mods on the right-hand side of TaleSpire. Luis and I have been testing the web-view library under Linux (via Proton) to ensure we can provide the same experience across Windows, Linux, and Mac. So far, we’ve got it working if we disable sandboxing, which isn’t ideal but might be how we ship the beta.
Continuing with Linux, we have progressed in getting talespire:// URLs to work out of the box. Until now, we’ve been relying on a great script from community members, but in some cases, it requires user input [0]. This was because some execution flags[1] involved are system dependent.
Luckily for us, after a bunch of digging, Luis realized they were in the environment variables! So now we are pretty sure we have what we need to make this work. Hopefully, more on this soon.
From Linux to Mac we also have some good news. Unity has replied to Ree, saying that the bug he submitted (and that is blocking us from shipping mac support) has been fixed and is rumbling through whatever internal process is needed before it is released. When the fix eventually ships, we will have to upgrade our Unity version, which hopefully won’t be too painful [2].
I’m mostly done with a feature that allows you to only show the tiles/props you are currently selecting. This can be handy for precise selections, especially when working out what to upload to a slab repository. You can see it in action here:
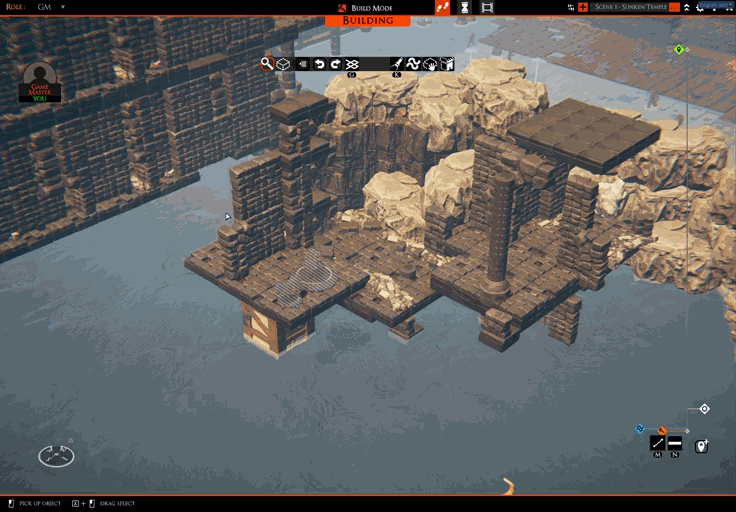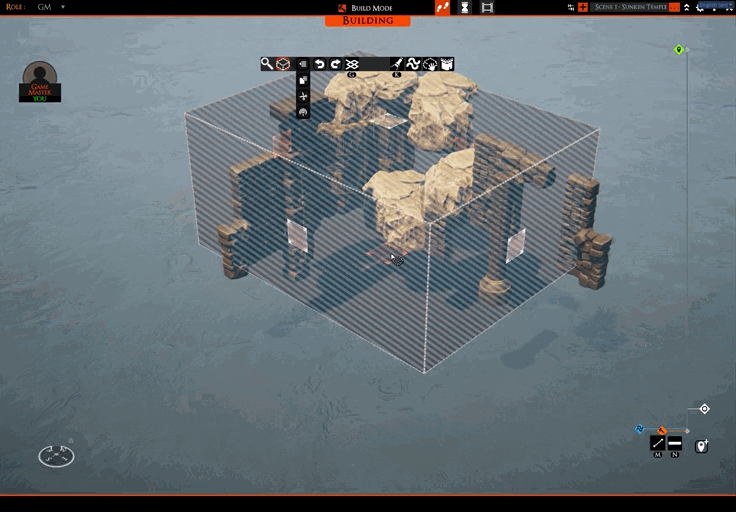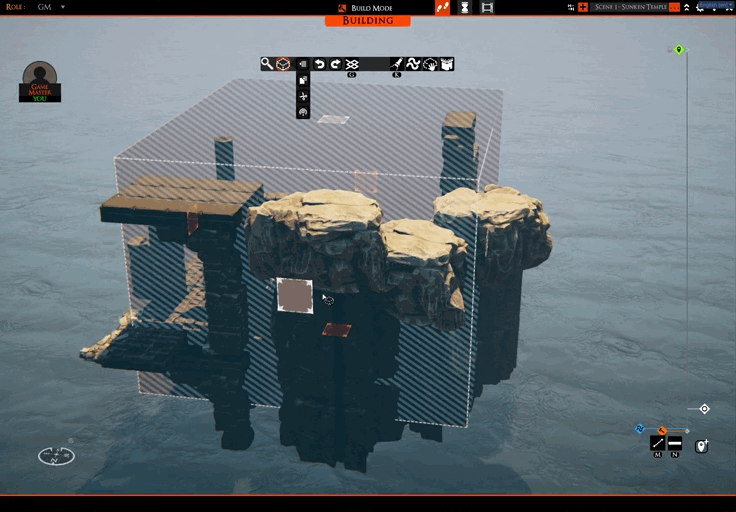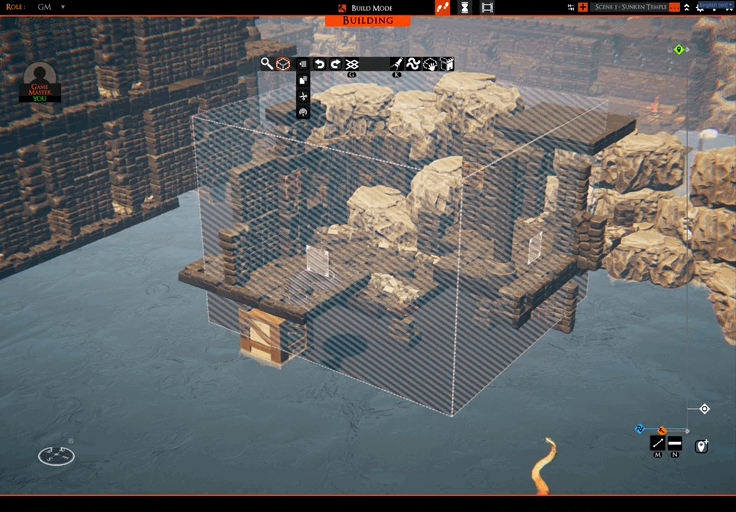
You may also have spotted this icon:
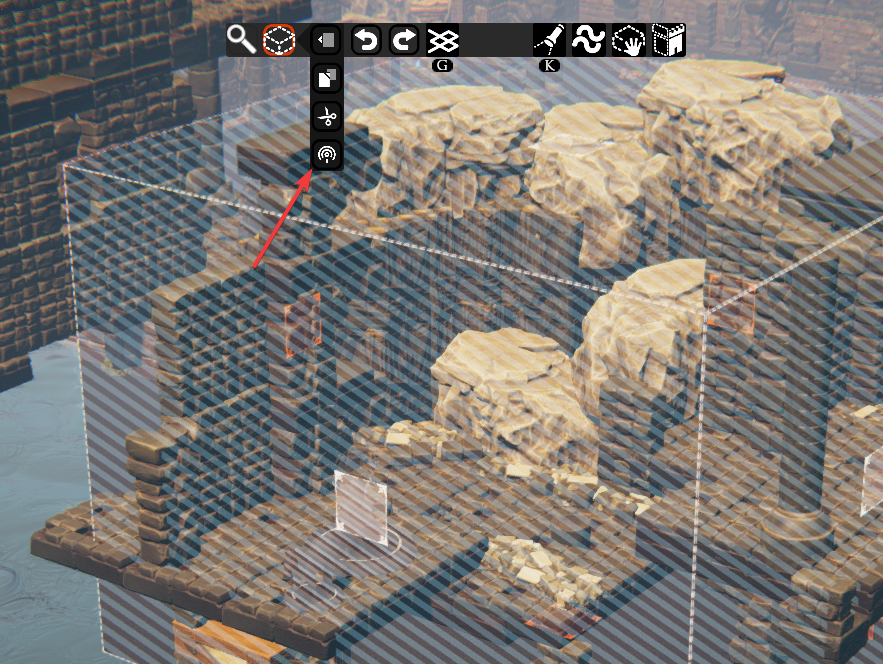
This is the “publish slab” button. Clicking it will take you to a mode where you can frame the screenshot for your slab and provide the required information. That mode will also be used for editing the info of the slabs you’ve already uploaded. It’s looking rough right now, but we have plenty of time to improve it. For now, I want to focus on shipping this stuff as soon as possible.
I’m running a bit low on caffeine, so other things will have to wait for another dev log.
Have a good one folks.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
[0] Also because it is run by Proton, so needs to be a Windows program.
[1] ESync or FSync
[2] There is a good chance that it will also fix the long-standing bug in the input system that stops us binding e to actions. That one is so weird!
TaleSpire Dev Log 371
It’s time for a video dev log.
While I have you here, I’m going to abuse this reach I have to pimp something non-talespire, and even non-ttrpg related.
A good friend of mine released a game last week, and I’m so stoked for him. It’s called Kandria, and it’s a 2d open world hack-n-slash platformer, with celeste’esce smoothness of control, and a story laden post-apocalyptic environment. If that sounds at all interesting please give it a look here.
And with that I’m off, Cheers folks!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team