From the Burrow
TaleSpire Dev Daily 3
Allo again,
Today wasn’t the most satisfying. I wanted to prototype the undo/redo scheme I had doodled out but some of how floors was implemented was making it difficult. Even though we are redesigning the floor system this weekend it was more work to work around the issues than just tweak them so, after a couple of hours reaching that realization, I spent a good chunk of the day yak shaving.
With that somewhat out of the way I had a go at implementing the scheme. I already has working local undo/redo, so the task was making it work with multiple people editing simultaneously.
One example issue (which I mentioned yesterday) can be summarized like this:
There are two GMs,
A&Band each have their own undo/redo history
- GM
Aplaces a floor-tile- GM
Aplaces a crate- GM
Bdeletes the crate- GM
Apresses undo
One possibility is then when B deletes the crate, the history event for placing the crate in As history could be removed. This way A can’t attempt to undo or redo something that has gone.
I’m a bit adverse to deleting stuff from the history however as you lose data. Instead I wanted to try putting a flag on the history event that inhibits it. When A hits ‘undo’ it will skip over the inhibited event and do the one before it. The nice side effect is that if B was to undo the delete, we can uninhibit the history event in As history again, allowing undo and redo to proceed as before.
The idea has edge cases though and, whilst I have seen a few of them, I’m not going to bog this post down with them yet. I’ll do some more experimentation and then report back to you all :).
As for tomorrow I think I’m going to leave this on a branch and get back to a few other bugs that are more likely to be an issue when working this weekend. There is one rather nasty one regarding level loading an reuse of supposedly unique ids :)
Until then,
Peace
TaleSpire Dev Daily 2
Today I refactored how we spawn and sync multiple tiles of the same kind which is used when dragging out tiles when in build mode. The new implementation uses less memory to synchronize but more importantly has a single entry in the undo/redo history so you can undo a slab of tiles in one go. In the process of doing this I also simplified one way of sending messages which means there is less boilerplate code to write (less code less bugs).
The last third of the day was mostly spent doodling on the whiteboard to work out a nice way of handling how edits made by multi game masters can cause conflicts in the undo/redo history.
A simple is case is as follows.
There are two GMs, A & B and each have their own undo/redo history[0]
- GM
Aplaces a floor-tile - GM
Aplaces a crate - GM
Bdeletes the crate - GM
Apresses undo
What should happen?
If B hadn’t delete the crate then A’s undo would have removed the crate. But the crate is already gone.
If we do nothing but move back in the history then A will be confused. A successful input without an output makes the user feel like either they did something wrong or the system is broken.
It feels like the sane thing is that if nothing can be done we skip to the previous entry. But then what do we do with redos?
Also if GM A dragged out 20 tiles and B deletes just one, what is the correct behavior. I think I’d expect the rest of the tiles to be removed. So then does redo restore them all?
I think I have a solution for this but I only got it partially finished today. I’ll get back into this tomorrow and see how it feels.
If that doesn’t feel nice then I am considering briefly showing a ‘ghost’ of the deleted object so you at least get the indication that something happened.
Right, time to get some food and get ready for the lisp stream in a few hours.
Ciao.
[0] Separate undo/redo is pretty important to avoid people undoing each other’s work, this rapidly escalates to bloodshed.
Boring Caveats
These are just my daily notes as I work on TaleSpire. It’s so cool that people are interested in the game and it’s way more fun to share this stuff that just keep it away, however nothing said here should be taken as any kind of promise that a thing will exist in a given release or work in the way stated. Stuff changes constantly and I’m wrong about at least 1000 things a day so whatever I’m stoked about today may well be tomorrows nightmare.
So yeah, that’s that. Back to the code :)
TaleSpire Dev Daily 1
Alright, another day down.
Today was primarily spent adding the undo/redo system which is looking pretty good now. A few bugs to iron out but nothing that looks terrifying.
As you’d probably imagine it’s a simple list of history actions and an index of where in the history you currently are. Each event has Undo and Redo methods and some serialized state for the thing that was being added/removed/etc. This a dirt simple approach and can get pretty unwieldy for systems with many more kinds of actions but for our little thing it’s just fine.
During making this I noticed that the board synchronization code was being too conservative about when it could send the board so now it gets sent much sooner after loading from disk. The basic run down goes something like this:
Tiles load their assets (visuals and scripts) asynchronously so it can be a relatively long time (a few frames) after the tile is created before the Lua scripts inside are running. Because of this, when deserializing we cache the state intended for this asset until the Lua scripts are fully set up.
When loading levels we obviously want to send the full state to the other players so we waited for all the assets to be full loaded before sending the level to other players. This was pointless as a give tiles can only be in 3 states regarding initialization.
- it’s fully set up and running
- it’s been initialized, has some cached state, and is still loading
- it’s been initialized, has no cached state, and is still loading (like when you first place it)
In all of these cases we can serialize as, even if it hasn’t finished loading, we have the pending state or we know it’s going to have default state.
We also could just sync the level data from the local file and append the additional setup data (character network ids etc), and we may go that way, however for now the runtime cost of load-then-sync is so low currently that it’s not worth it.
Tomorrow I will be refactoring dragging out tiles. Simple stuff but it needs some attention so it plays nicer with sync and undo.
Seeya tomorrow!
Boring Caveats
These are just my daily notes as I work on TaleSpire. It’s so cool that people are interested in the game and it’s way more fun to share this stuff that just keep it away, however nothing said here should be taken as any kind of promise that a thing will exist in a given release or work in the way stated. Stuff changes constantly and I’m wrong about at least 1000 things a day so whatever I’m stoked about today may well be tomorrows nightmare.
So yeah, that’s that. Back to the code :)
TaleSpire Dev Thang 0
Evening all! I really need to start doing my daily signoffs somewhere people can see.. so here we are!
Most of my work these days is rewriting systems from the prototype you may have seen on the streams. As you can imagine there are lots of things that were hacked in to see how they would feel but were never fleshed out. Today I was working on the sync of state from scriptable tiles. Currently only the state-machine script we are using for the doors and chests is using this change but it’s now easy for us to expand on.
I also finally let my partner try out the building system (see it’s not just you folks who haven’t been let in :D) and have a big ol’ list of things to change. Many are things we knew about but it’s always good to get fresh eyes on it.
This weekend I’m off to @jonnyree’s place so we can plan out the rewrite of the floor and fog-of-war systems so expect news on that next week.
Tomorrow I think I’m going to look at basic undo-redo and see what feels nice when you have multiple people editting the board at the same time.
That’s it for now.
Peace
p.s
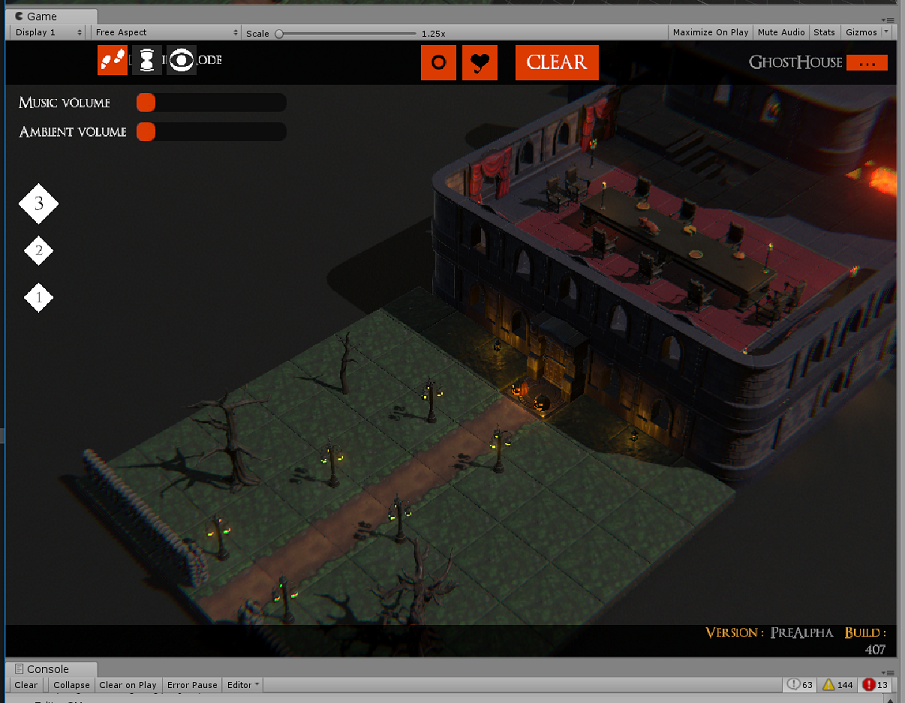
Notes to Self Part N: SSL Checker
I will get back to blogging at some point, I kinda miss it.
However today I just need to note that this guy is super handy for checking that a site’s certificates are set up properly.
https://www.sslshopper.com/ssl-checker.html
At least it’s super useful for a noob like me.
Windows emacs setup
My mate was looking at using emacs on windows and so I wrote a little ‘how to’. I then added my own opinions of stuff to start with so it got bigger. Made sense to just dump it here:
Note
I’m probably out of date! I just saw you can install emacs via pacman in msys which might handle a bunch of the ‘path’ & environment variable shit for you. I’m going to look into this and then update this guide.
Install
- download this chap http://ftp.gnu.org/gnu/emacs/windows/emacs-26/emacs-26.1-x86_64.zip
- There is no install process so just extract it to c:\ so you have a folder like c:\emacs-25-1
- open the c:\emacs-*-\bin folder
- copy the path to that directory
- add it to the PATH environment variable
- make a folder called ‘home’ folder in c:\ (or if you have one for msys skip this step). I do this as twice I’ve had windows shit up after updates and tell me my account isnt mine anymore and I hate fighting that shit
- Add a environemnt varable called HOME and set it to your new (or mysys) ‘home’ directory
- Basic setup is done but there are some things you will want.
Package manager
Dont download packages yourself, keeping them current is a pain, emacs comes with a package manager but the official package source is a little behind the times so we will add one that is much more used by the community ‘melpa’
See this video for how to use and install it: https://www.youtube.com/watch?v=Cf6tRBPbWKs
Short version is:
- hit ‘M-x’ [0] which will open the minibuffer at the bottom of emacs, type ‘customize’ and hit return.
- Type ‘package’ in the search bar and hit return.
- Scoot your cursor down to the arrow next to ‘package archives’ and hit return to open that subtree
- hit return on the ‘INS’ button and add ‘melpa’ as the archive name and ‘http://melpa.org/packages/’ as the url
- ‘C-x C-s’ to save (which means) hold down control and press ‘x’ then ‘s’
This will have edited your .emacs file in your ‘home’ directory, this is nice as lots of packages use the customize system and its often friendlier than searching docs for the right thing to edit.
Magit (reticently optional)
- restart emacs (rarely neccessary but I want to be sure evertyhing is fresh) and hit ‘M-x’ and type ‘list-packages’ and hit return
- give it a second to pull the package list and then install ‘magit’ (see that video for a guide of how to do that)
- This is the nicest damn git client, I’d install emacs for this even if I wasnt using it as a text editor.
Biased Baggers .emacs file additions (optional)
Open your .emacs file and paste the following at the top of the file
It looks like a lot just its just shit I’ve slowly accrued whilst using emacs.
;; so package manager is always good to go
(package-initialize)
;; utf8 is a good default
(setenv "LANG" "en_US.UTF-8")
;; when you start looking for files its nice to start in home
(setq default-directory "~/")
;; Using msys?
;; to make sure we can use git and stuff like that from emacs
(setenv "PATH"
(concat
;; Change this with your path to MSYS bin directory
"C:\\msys64\\usr\\bin;"
(getenv "PATH")))
;; Fuck that bell
(setq ring-bell-function #'ignore)
;; Turn off the menu bars, embrace the keys :p
(tool-bar-mode -1)
(menu-bar-mode -1)
;; Dont need emacs welcome in your face at every start
(setq inhibit-splash-screen t)
;; typing out 'yes' and 'no' sucks, use 'y' and 'n'
(fset `yes-or-no-p `y-or-n-p)
;; Highlight matching paren
(show-paren-mode t)
;; This might be out of date now, need to ask kristian
(setq column-number-mode t)
;; You can now used meta+arrow-keys to move between split windows
(windmove-default-keybindings)
;; Kill that bloody insert key
(global-set-key [insert] 'ignore)
;; Stop shift mouse click opening the font window
(global-set-key [(shift down-mouse-1)] 'ignore)
(global-set-key [(control down-mouse-1)] 'ignore)
;; C-c C-g now runs 'git status' in magit. Super handy
(global-set-key (kbd "\C-c \C-g") `magit-status)
;; Jump to matching paren. A touch hacky but I nabbed it from somewhere and has worked well enough for my stuff
;; probably something better out there though (this is language independent though).
;; Move to one bracket and hit 'Control )' to jump to the other bracket
(defun goto-match-paren (arg)
"Go to the matching if on (){}[], similar to vi style of %"
(interactive "p")
;; first, check for "outside of bracket" positions expected by forward-sexp, etc.
(cond ((looking-at "[\[\(\{]") (forward-sexp))
((looking-back "[\]\)\}]" 1) (backward-sexp))
;; now, try to succeed from inside of a bracket
((looking-at "[\]\)\}]") (forward-char) (backward-sexp))
((looking-back "[\[\(\{]" 1) (backward-char) (forward-sexp))
(t nil)))
(global-set-key (kbd "C-c )") `goto-match-paren)
ssh-agent hack (only needed if you have the issue I did)
Windows is a pita with some of this stuff. I have emacs on machine using the bash provided with git rather than a dedicate msys or whatever install and I got confused some ssh-agent issues. So I just made a windows shortcut that runs emacs from git bash and that helped. I get propted for my ssh-agent password on launch (which I do once a day) and then im free to work.
The shortcut just pointed to: "C:\Program Files\Git\git-bash.exe" -c "emacs-25.2"
Control Key (optional)
The control key is in the wrong place and it’s not good for the hand to keep having to reach for it. Let’s make capslock an extra control key.
make a file called control.reg and paste this in it
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Keyboard Layout]
"Scancode Map"=hex:00,00,00,00,00,00,00,00,02,00,00,00,1d,00,3a,00,00,00,00,00
Save it, run it and restart windows for it to take effect.
Done (optional :p)
Save and restart emacs again. Hopefully there are no errors (bug me if there are)
Remember that emacs is your editor, nothing is too stupid if it makes your experience better. For example I kept mistyping certain key combos so I bound the things I kept hitting instead to the same functions, it’s small but it makes me faster.
Thats all for now, seeya!
[0] (M stands for meta and is the alt key [the naming comes from the old lisp machine keyboards iirc)
{kind=link}
Cleaning up a photo of a whiteboard
I have small bad handwriting so some of the automatic methods out there really didnt work for me.
This is an excellent start:
https://gist.github.com/adsr303/74b044534914cc9b3345920e8b8234f4
In case that gist is gone:
Duplicate the base image layer.
Set the new layer's mode to "Divide".
Apply a Gaussian blur with a radius of about 50 (Filters/Blur/Gaussian Blur...)
Note: Alternatively just perform a ‘difference of gaussians’ on the image setting the first to radius 70 and the second to radius 1
I used a Gaussian blue with radius 70 in both directions. Mode is a dropdown near the top of the layers panel.
Next pick a background color and paint over the world offending background features; stuff like magnets and erasers.
Then flood fill with that color to normalize as much as possible.
Then flood fill with white. This should be pretty effective now.
Open up the hue/saturation (some name like that) tool up the saturation as the colors will be a bit washed out.
Finally open up brightness & contrast and drop the brightness a tiny bit.
That’s it. Much nicer to stare at and maintains all the features.

slime-enable-concurrent-hints
This is just me dumping something I keep forgetting. When you are live coding you often block the repl, you can call swanks handle-requests function to keep the repl which works but the minibuffer likely wont be showing function signatures (or other hints) any more. To enable this add this to your .emacs file and call using M-x slime-enable-concurrent-hints
(defun slime-enable-concurrent-hints ()
(interactive)
(setf slime-inhibit-pipelining nil))
Fuck yeah progress!
I’ve been on holiday for a week and it’s been great for productivity; the march to get stuff out my head before my new job goes rather well.
More docs
First stop rtg-math. This is my math library which for the longest time has not been documented I fixed that this week so now we have a bootload of reference docs. Once again staple is hackable enough that I could get it to produce signatures with all the type info too. Blech work but I can not think about that for a while. One note is that the ‘region’ portion of the api is undocumented as that part is still WIP.
SDFs
Next I wanted to get some signed distance functions into Nineveh (which is my library of useful gpu functions). SDFs are just a cool way to draw simple things and so with the help of code from shadertoy (props to iq, thoizer & Maarten to name a few) I made a nice little api for working with these functions.
One lovely thing was in the function that handles the shadows, it needs to sample the distance function at various points and rather than hardcoding it we are able to pass it in as a function. As a result we get things like this:
(defun-g point-light ((fn (function (:vec2) :float))
(p :vec2)
(light-position :vec2)
(light-color :vec4)
(light-range :float)
(source-radius :float))
(shaped-light fn
#'(length :vec2)
p
light-position
light-color
light-range
source-radius))
Here we have the point-light function, it takes a function from vec2 to float and some properties and then calls shaped-light passing in not just this but also a function that describes the distance from the light source (allowing for some funky shaped lights, though this is WIP).
This made me super happy as using first class functions in shaders as a means of composition had been a goal and seeing more validation of this was really fun.
Particle Graphs
One thing with these functions is when you want to visualize them it’s a tiny bit tricky as for each point you have a distance, which makes 3 dimensions. We can plot the distance as a color but it requires remapping negative values and the human eye isnt as good as differentiating color as position.
To help with this I made a little particle graph system.
define-pgraph is simply a macro that generates a pipelines that uses instancing to plot particles, however it was enough to make visualizing some stuff super simple. However as they are currently just additive particles it is difficult to judge which are in front sometimes. I will probably parameterize that in future.
Live recompiling lambda-pipelines
In making this I realized that there was a way to make CEPL’s lambda pipelines[0] be able to respond to recompilation of the functions they depend on without any visible api change for the users. This was clearly to tempting to pass up so I got that working.
The approach is as follows (a bit simplified but this is the gist):
(let ((state (make-state-struct :pipeline pline ;; [1]
:p-args p-args))) ;; [2]
(flet ((recompile-func ()
(setf (state-pipeline state) ;; [4]
(lambda (&rest args)
(let ((new-pipeline
(recompile-pipeline ;; [5]
(state-p-args state)))) ;; [6]
(setf (state-pipeline state) ;; [7]
new-pipeline)
(apply new-pipeline args))))));; [8]
(setf (state-recompiler state) #'recompile-func)
(values
(lambda (context stream &rest args) ;; [3]
(apply (state-pipeline state) context stream args))
state)))
[1] first we are going the take or pipeline function (pline) and box it inside a struct along with the arguments [2] (p-args) used to make the pipeline. If we hop down to the final lambda we see that this state object is lexically captured and the boxed function unboxed and called each time the lambda is called. Cool so we have boxed a lambda, however we need to be able to replace that inner pipeline whenever we want.
To do this we have the recompile-func, ostensibly we call this to recompile the inner pipeline function, however there is a catch: the recompile function could be called from any thread. Threads are not the friend of GL so we instead recompile-func actually replaces the boxed pipeline [4] with the actual lambda that will perform the recompile. As it is only valid for the pipeline to be called from the correct thread we can safely assume this. So next time the pipeline is called it’s actually the recompile lambda that will be called; this finally does the recompile [5] (using the original args we cached at the start [6]) and then replaces itself in the state object with the new pipeline function [7]. As the user was also expecting rendering to happen we call the new pipeline as well [8].
There are trade-offs of course, this indirection will cost some cycles and as we don’t know how the signature of the inner pipeline function will change we can’t type it as strictly as we would want to otherwise. However we can opt out of this behavior by passing :static to the pipeline-g function when we make a lambda pipeline, this way we get the speed (and no recompilation) when we need it (e.g. when we ship a game) and consistency and livecoding when we want it (e.g. during development).
Needless to say I’m pretty happy with this trade.
vari-describe
vari-describe is a handy function which returns the official glsl docs if available. This was handy but I have a growing library of gpu functions that naturally have no glsl docs.. what to do? The answer of course is to make sure docstring defined inside these are stored by varjo per overload so they can be presented. In the event of no docs being present we can at least return the signatures of the gpu function which, as long as the parameter names were good, can be quite helpful in itself.
This took a few rounds of bodging but works now. A nice thing also is that if you add the following to your .emacs file:
(defun slime-vari-describe-symbol (symbol-name)
"Describe the symbol at point."
(interactive (list (slime-read-symbol-name "Describe symbol: ")))
(when (not symbol-name)
(error "No symbol given"))
(let ((pkg (slime-current-package)))
(slime-eval-describe
`(vari.cl::vari-describe ,symbol-name nil ,pkg))))
(define-key lisp-mode-map (kbd "C-c C-v C-v") 'slime-vari-describe-symbol)
You can hold control and hit C V V and you get a buffer with the docs for the function your cursor was over.
This all together made the coding experience significantly nicer so I’m pretty stoked about that.
Tiling Viewport Manager
This is a project I tried a couple of years back and shelved as I got confused. In emacs I have a tonne of files/programs open in their respective buffers and the emacs window can be split into frames[9] in which the buffers are docked; this way of working is great and I wanted the same in GL.
The idea is to have a standalone library that handles layouting of frames in the window into which ‘targets’ (our version of buffers) are docked. These targets can either just be a CEPL viewport or could be a sampler or fbo.
As the target is itself just a class you can subclass it and provide your own implementation. One thing I was testing out was making a simple color-picker using this. Here’s a wip, but the system cursor is missing from this, the point being ‘picked’ is at the center of the arc.

Back to work
Back to work now so gonna lisping will slow down a bit. In general I’m just happy with this trend, it’s going in the right direction and it feels like this could get even more enjoyable as I build up Nineveh and keep hammering out bugs as people find them.
Peace all, thanks for wading through this!
[0] pipelines in CEPL are usually defined at the top level using defpipeline-g, lambda pipelines give us pipeline-g which uses Common Lisp’s compile function to generate a custom lambda that dispatches the GL draw.
[9] in fact emacs has these terms the other way around but the way I stated is usually eaiser for those more familiar with other tools
Lisping Furiously
This week has been pretty productive.
It started with looking into a user issue where compile times were revoltingly slow. It turns out they were generated very deeply nested chains of ifs and my code that was handling indenting was outstandingly bad, almost textbook example of how to make slow code. Anyway after getting that fixed up I spent a while scraping back milliseconds here and there.. there’s a lot of bad code in that compiler.
Speaking of that, I knock Varjo a bunch, and I’d never make it like this again, but as a vessel for learning it’s been amazing, most issues I hear about in compilers now I can at least hook somewhere in my head. It’s always ‘oh so that’s how real people do this’, very cool stuff. Also, like php, varjo is still unreasonably still providing me with piles of value; what it does is still what I wanted something to do.
After that I was looking into user extensible sequences and ended up hitting a wall in implementing something like extensible-sequences from sbcl. I really want map & reduce in Vari, but in static languages this seems to mean some kind of iterator.
It would really help to have something like interfaces but I can’t stand the idea of not being able to say how another user’s type satisfies the interface, so I started looking into adding traits :)
I was able to hack in the basics and implement a very shoddy map and could get stuff like this:
TESTS> (glsl-code
(compile-vert () :410 nil
(let* ((a (vector 1.0 2.0 3.0 4.0))
(b (mapseq #'(sin :float) a)))
(vec4 (aref b 0)))))
"// vertex-stage
#version 410
void main()
{
float[4] A = float[4](1.0f, 2.0f, 3.0f, 4.0f);
float[4] RESULT = float[4](0.0f, 0.0f, 0.0f, 0.0f);
int LIMIT = A.length();
for (int STATE = 0; (STATE < LIMIT); STATE = (STATE++))
{
float ELEM = A[STATE];
RESULT[STATE] = sin(ELEM);
}
float[4] B = RESULT;
vec4 g_GEXPR0_767 = vec4(B[0]);
gl_Position = g_GEXPR0_767;
return;
}
but the way array types are handled in Varjo right now is pretty hard-coded when I had it making separate functions for the for loop each function was specific to the size of the array. So 1 function for int[4], 1 function for int[100] etc.. not great.
So I put that down for a little bit and, after working on a bunch of issues resulting in unnecessary (but valid) code in the GLSL, I started looking at documentation.
This one is hard. People want docs, but they also don’t want the api to break. However the project is beta and documenting things reveals bugs & mistakes. So then you have to either document something you hate and know you will change tomorrow, or change it and document once.. For a project that is purely being kept alive by my own level of satisfaction it has to be the second; so I got coding again.
Luckily the generation of the reference docs was made much easier due to Staple which has a fantastically extensible api. The fact I was able to hack it into doing what I wanted (with some albeit truly dreadful code) was a dream.
So now we have these:
- Reference Docs for the Vari language
- Reference Docs for the Varjo compiler
- The start of a user guide for Varjo
Bloody exhausting.
The Vari docs are a mix of GLSL wiki text with Vari overload information & handwritten doc strings for the stuff from the Common Lisp portion of the api.
That’s all for now. On holiday for a week and I’m going to try get as much lisp stuff out of my head as possible. I want my lisp projects to be in a place where I’m focusing on fixes & enhancements, rather than features for when I start my new job.
Peace