From the Burrow
TaleSpire Dev Log 324
Hi folks!
The HeroForge work is rapidly solidifying. We have had some testers playing with it and finding plenty of bugs, but nothing looks too scary. We have been able to try out some more normal creations…


…and some that are a little more out there.

In recent days I’ve been working on:
- Support for multiple creatures on a single base
- A mistake in mipmap generation
- A Linux (via Proton) specific bug due to how I was calling some WinAPI functions for random data
- Issues with miniature placement
- A line-of-sight bug which arose because of the changes needed to the creature code.
- Better use of head/hand/etc positions from model, and sensible fallback values;
Handling scale
The eagle-eyed among you may have noticed some large creatures with surprisingly small bases. Until now, the base size has matched the creature size (0.5x0.5 -> 4x4). After some discussions with HeroForge, we decided that the scale of the base relative to the creature should match the HeroForge editor as closely as possible.
One problem that immediately arose was that you can’t just use the base size as the default scale. Otherwise, this chap

who is a 1x1 creature can be scaled up to 4x4, which gives you this

Which is unplayable[0].
This meant decoupling base size and creature size. We use the total size of the mesh to pick a sensible default size and let the base be rescaled to keep the proportions required. This keeps things looking good while also being playable[1]

Today
So far today, I’ve hooked up the emissive map, which is where HeroForge bakes its lights[2].
 Note: As you can see there is still work to do on the strength of the emissive
Note: As you can see there is still work to do on the strength of the emissive
It seems that the emissive map is included even if it is empty, so I am updating the asset conversion process to check for this. We can then exclude blank maps, saving some GPU memory in the process.
I am then back on bugs and loose ends. I have a lot of ‘todos’ in the code where I need to handle failure cases and decide how to relay them to the user. This will be fine, but it takes a little time. All of these cases will be relevant for the creature modding too.
I won’t finish all the fixes today naturally, but it’s all looking very positive. Getting a mini from HeroForge into TaleSpire takes about ten seconds, depending on download time (mine is pretty slow).
Until next time!
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] I’m trying not to be hyperbolic here. I tried playing with it, and it was utterly useless at those scales.
[1] Even today, scale can be tricky in TaleSpire. I definitely don’t want to claim that our approach with HeroForge is ideal, but this feels in line with the current experience of the built-in assets.
[2] Except for the “dark magic” lights. We need to work out how/if we can support those.
TaleSpire Dev Log 323
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
Hey everyone,
Last week was quite a doozy. I didn’t mention it at the time, but I was in the process of trying (and failing) to buy a house, so lots of extra distractions.
Photon issues
A few of you also got bitten by a Photon issue earlier in the week so let’s talk about that first.
We’ll kick off with a bit of background. Photon is a service we use for handling real-time network communication in TaleSpire. By adding their SDK to your game (which we will call “the client”) can create “rooms.” Other clients can then join the same room. When multiple clients are in the same room, they can send data to each other. The data can be transmitted reliably (via RPC) or unreliably[0]. Photon also has a lot of functionality to help with managing networked GameObjects to trivially keep them in sync. When a room is closed, no information persists.
Photon operates servers worldwide so that the time to send messages between clients is minimized. Running such a service is a huge undertaking, and even the pros struggle with it. Without something like Photon, TaleSpire wouldn’t have happened as we would not have been able to make something similar in the time our funds allowed.
We do have our own backend and data message service, but it is not designed to handle real-time traffic. Instead, we focus on what you can’t do with Photon: communication between rooms and persisting data.
Right, that’s a lot of background, but hopefully, Ι got across that this service is valuable and is not trivially replaced[1]. But when Photon has issues, we feel it.
That was what happened earlier this week. For about an hour, some people whose campaigns are hosted in the EU were having issues connecting. We were confused as Photon’s status page was not showing a problem. We have confirmed with other developers using Photon that the event occurred and are starting a conversation with Photon’s support to see what we can learn.
It’s somewhat disconcerting to see such issues after Photon being solid for so long, but we aren’t keen to throw out the baby with the bathwater, so we take these things slowly.
Voice chat
As we are talking about network stuff, let’s ramble about voice chat.
Voice chat is an interesting challenge. In principle, we can just find a suitable[3] webrtc client and hook it up. Of course, hooking it up is where it gets fun.
WebRTC is principally p2p. Setting up the connection requires exchanging some messages, so there does need to be a way to do that. Of course, we have our backend, so we can use that to handle the setup (of course, then it’s not pure p2p, but the call will be).
Next, you have NAT travelsal. Basically, it is not always possible, so sometimes (let’s say 15% of the time), you can’t have a p2p connection. What to do? Well, WebRTC allows for relays that the problematic client can connect to in those cases. Of course, these relays have to be hosted somewhere (not p2p), and that costs money. You can certainly find people who host free ones (google does this), but as you can imagine, you need to trust them.
And we are far from done. Let’s talk traffic. We will assume that we have five clients connected, and that all managed to connect peer-to-peer. That means that each person has to send their voice and video data to all four other machines. More players? More overhead. And all of those clients also have to receive data from every other client too.
That traffic adds up real fast! So being ingenious, you decide to change the approach. How about we have some central machine that all the clients send their voice and video to. That machine then has a stream for each player that you can connect to. So if there are ten clients, each client is uploading one stream and receiving nine. That is a significant improvement over the nine outbound and nine inbound approach when communicating p2p. That does mean we just lost p2p. Worse, we now need servers around the world for relaying this information.
Ten media streams per client are still quite a lot. Instead, you could have the previously proposed central server take all the media streams, combine them into a single stream, and make that available to the clients. Now each client only needs two streams, one inbound and one outbound. However, now the servers behind the scenes aren’t just relaying data; they are re-encoding audio and video, which is much more resource-intensive. So the cost of your backend just went up a lot!
The above is a clumsy, simplified view of some of the problems in adding voice and video chat. However, these are precisely the kinds of tradeoffs discord, zoom, and others make. It is not viable to hand-wave these problems away if you are selling a product. Your customers will care.
And so we go back to TaleSpire. We need voice and video chat. And we are going to use WebRTC to provide p2p calls. However, this will take time. Unity also has a service for voice chat called Vivox. I will look into this as a means to bring voice chat to TaleSpire faster without us having to provide extra infrastructure.
I don’t yet know if it will be a good fit, but it is definitely worth a look. It could even be that we use it as the default for those who don’t want to trade off the overhead for the additional security of p2p.
HeroForge integration
In the last dev-log, I talked about how Ι had the core HeroForge functionality working, but also that I had written some of it quickly rather than robustly so we could start testing other parts of the system.
My job since then has been rewriting to make things solid. The short version of the problem is that we have code that:
- queries which miniatures we are meant to have
- downloads miniatures
- converts miniatures
- caches miniature data
- deletes miniatures that are no longer needed from the cache
All of these processes are asynchronous, so things can get fun when operations overlap.
For example, let’s say that someone links a miniature to their campaign, and then when trying to link a different mini, accidentally unlinks the first one, realizes their mistake, and links it again. Let us also say they have a good internet connection and that by the time they correct their error, the miniature data has been downloaded and that the conversion has begun (this is a realistic situation).
Now! They unlinked, so we should delete the mini from the cache, but it’s not there yet as it’s still converting. So we can try cancel the conversion process, but it’s not guaranteed that the message will be processed before the other thread has finished. Instead, let us assume we mark somewhere to delete the mini when it hits the cache.
We can also recall they have now relinked while this was happening. So we do need the mini. So if we delete it, we need to download it and convert it again. And if we do try and download it, we need to make sure we download it to a different folder as deleting the local data takes time too.
I’m belaboring the point a bit, but Ι hope it’s clear that by assuming different timings of user input, downloads, and processing, we can end up with various different situations to handle. [4]
After a good few flow diagrams and pacing around my room, we have something that behaves reliably. Ι can’t think of a way to describe it without making this post much longer. The short version is that there is a strict hierarchy between the HeroForge account handling code, the cache manager, and the download manager. The cache also needs to handle the possibility of multiple versions of the same mini being in flight at once (rare case but needs handling).
Caches and running multiple copies of TaleSpire
Now I hear you calling out, “caching is just so fun, tell us more!” and to that Ι say, get help. But also… sure.
Some of you out there run multiple copies of TaleSpire on the same machine. It’s a relatively uncommon case, but it can be helpful for streamers or TV play.
The problem is that TaleSpire caches files (parts of boards, HeroForge minis, etc.) in a specific directory. If we have two copies of TaleSpire running, both are trying to write to those folders simultaneously. Worse, they might try and delete the same stuff too.
So far, we have ignored the problem as conflicts were rare, and the use case was niche. However, these problems will become mainstream with the upcoming package manager.
To handle this, we have to detect whether a cache is in use and, in such a case, make a new cache (or reuse an old one). And we have to do this in a cross-platform fashion.
This is really a variant of the “detect whether my program is already running problem,” so let’s look into it.
We need some construct to signal that a resource is taken across processes. Another wrinkle in the problem is that this not only needs to be cross-platform but ideally needs to be supported in MS and Mono’s DotNet implementations.
If this were an interthread problem, we would use a mutex, but your traditional mutex doesn’t communicate across processes. Windows does have the named mutex, which might work, but isn’t supported on ‘Nix[5]. Linux does support named semaphores, so there might be a route there.
Windows also has file locking, and while Unix OS’ don’t tend to (afaik), they usually have advisory locking. This soft construct doesn’t prohibit overwriting but instead indicates that you shouldn’t. As we can query this information for a given file, we can use this as our communication construct.[6]
With this tool in hand, Ι made a system that does the following on TaleSpire start:
- tries to acquire the primary cache
- if it succeeds, it also tries to clean up any old caches which are not in use[7]
- if it fails, it looks to see if there is an older temporary cache it can claim else, it makes a new one
Thanks to the locking, we can trust that multiple clients can’t claim the same cache simultaneously.
Wrap up
That’s most of the news from me Ι think. Naturally, everyone else in the team has plenty going on too, but this log is long enough :)
Hope you are all doing well,
Until next time!
[0] If you are unused to network programming, you might be wondering why unreliable messages would be desirable. The reason is that for many cases, the latest values are all you care about, and older values are nearly useless. Player position is often a good example of this.
Making messages reliable takes a lot of work and sleight of hand performed either by your program or the network protocol. This adds a lot of overhead that you simply can’t afford in most cases in games.
This is a big subject, and I’m butchering it in this little comment, but hopefully, this helps a little.
[1] peer-to-peer is its own challenge, and it has plenty that makes it significantly trickier than the client-server approach. We will tackle it in the future, but it’s not something I expect to go smoothly :D
[2] And still isn’t, which is annoying
[3] It’s got to work and not be a resource hog.
[4] I’ve also left out a bunch of fun details such as file locking and OS/filesystem-specific considerations
[5] We are using Proton on Linux for the foreseeable future, so that case should be easy, but we still need a native client for Mac
[6] This approach is hairy but commonly used.
[7] It leaves a few around as the small cost in disk space is worth it to allow multiple clients to work faster. There would only be multiple caches if there was a time when multiple copies of TS were open at the same time.
TaleSpire Dev Log 321
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
The weekend was very successful. Ree made significant progress with the UI for the HeroForge integrations, and I worked on the implementation.
I started by fixing an issue causing minis not to be positioned correctly relative to the bases. Next up was scaling. I surveyed our current minis to find reasonable thresholds for picking different ‘default scale’ values for the miniatures. I need to test more minis with this. It will not be perfect, but it should get us started.
Next, I wrote the client-side code that handles unlinking minis from a campaign. Technically it works, but I noticed potential race conditions between asset conversion and cache clearing. This is obviously unsuitable, so I’m writing a manager to mediate access to the cache.
Usually, today would be a workday, but as I worked all Saturday and Sunday, I will take today as a break and get back into this tomorrow morning.
Have a good one folks!
TaleSpire Dev Log 321
Hi again,
As expected, today has been about HeroForge. I’ve added the manager that handles pulling down thumbnails and have been reworking parts of the conversion process.
Hmm, it’s very annoying how little text my day compressed down to :D
I’ve now merged our HeroForge branch into master. This is great as we are forced to deal with all the broken things. My plan for today is to help out with the UI where I can and otherwise to find and fix bugs.
The first order of business is definitely fixing some incorrect texture formats we are picking on load.
I’ll keep you posted,
Peace.
TaleSpire Dev Log 320
Good-evening all,
I am exhausted right now but didn’t want to leave another day without a dev log, so here is a tiny one.
I’ve continued work on trying to make some support tooling. It’s clearly one of those less fun things that my brain doesn’t want to do, so it’s been a bit of an uphill struggle.
I’m over at Ree’s for a few days now, and tomorrow we dive into HeroForge stuff again. I’m very excited about this and will let you know how it goes.
Right, I’m off to bed.
Seeya folks
TaleSpire Dev Log 319
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
Hi folks!
I’m back from my break and have been getting stuck into things for the last two days.
- I’ve updated the HeroForge convertor to use some metadata embedded in the model (previously, this was in a separate file)
- Thanks to some changes by HeroForge, I can now separate the ‘extras’ from the base so we can use our own base (which we need for the indicators)
- I’ve tested our code with the production version of their API (I have been using their api sandbox until recently)
- I tried making some very large minis to explore edge cases of the conversion process.
- I’ve merged the latest work from the master branch into the HeroForge branch.
- Worked on some server stability improvements (still got some code-gen things to finish there)
Tomorrow I’ll be focusing on making tools to help the team with support tickets. Currently, things like restoring deleted boards rely on some hacky scripts I wrote ages back and are not in a state useful for anyone else.
I’ll be visiting Ree from Friday to Monday to work on HeroForge integration together. I’m hoping to deal with most of my loose ends on the tech side during that time. It’s optimistic, but we’ll see how it goes.
I had a lovely break and am glad to be back into the swing of things again.
I should have another dev log for you tomorrow.
Peace.

TaleSpire Dev Log 316
I’ve been bamboozled, hoodwinked, and led astray.
I was tricked into adding a feature I was not ready to add, but we will be shipping anyway.
Today we are talking about creature copy/paste!
So, creature copy/paste is a bit of a minefield. The reason it has been delayed is that supporting everything we want is hard. For example, if you can copy/paste a creature, you expect it to work with slabs, which means selection bounds should work with them, which really implies multi-delete should work too… and undo/redo.
This is not trivial. Multiplayer undo/redo gets hard in ways that you cannot get around with quick fixes. Explaining why would turn this post into an essay, so I’m going to ask for your forgiveness in not covering this and instead ask you to trust me on that point. [0]
I did try to get it working before the Steam release, but it got nasty, and it was a case of pushing back the release or delaying the feature. I’ll admit that I didn’t expect I wouldn’t have revisited it yet, but c’est la vie.
Just a warning, this story doesn’t end with all of the above being supported, but you will be able to copy and paste creatures in (and out of) the game soon.
This all started with me trying to add “creature blueprints.” The idea of creature blueprints is to let you right-click a creature and generate a talespire:// URL containing all the setup info for that creature. This would allow you to share these blueprints with others. It was a simple, neat idea.
So, in short order, I had it working. You could right-click and click a button to get the URL. For convenience, we allow people to paste talespire:// URLs into TaleSpire to get the same effect as following the link [1]. It seemed like the correct behavior, so I added that too.

I showed it to some folks, and they said it would be neat if Ctrl-C did the same as the button. It sounded good to me, and, dumb as I am, I didn’t notice until I tested it that I had just been prodded into adding creature copy/paste [2].

Of course, it lacked all the complimentary features that I listed above. But this time I looked at it, I felt a bit differently. No, it does not work with undo/redo yet, but neither does spawning creatures right now. This means it isn’t out of place in the current build. It also is only about copying single creatures at a time, so none of the expectations around selections apply yet.
Honestly, I should have realized this a lot sooner. I just have to chalk it up to experience and remember to challenge my assumptions more. “Perfect is the enemy of good” seems relevant here.
The next thing to crop up was that when you paste a creature, it comes with all its stat values. However, the names of the stats in the campaign the creature was copied from might not match yours. In the future, the stat names should probably belong to a rule system, and the blueprint should hold an id to the rule system in use. However, I don’t want to repeat the same mistake by waiting for future features. So let’s get something simple out.
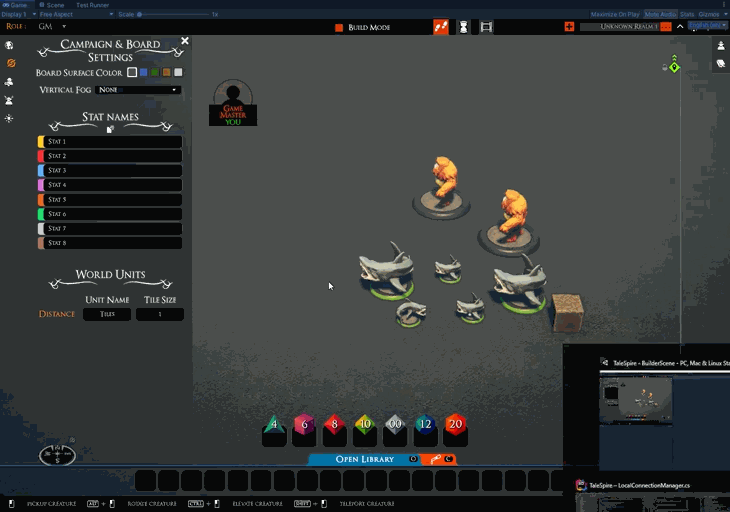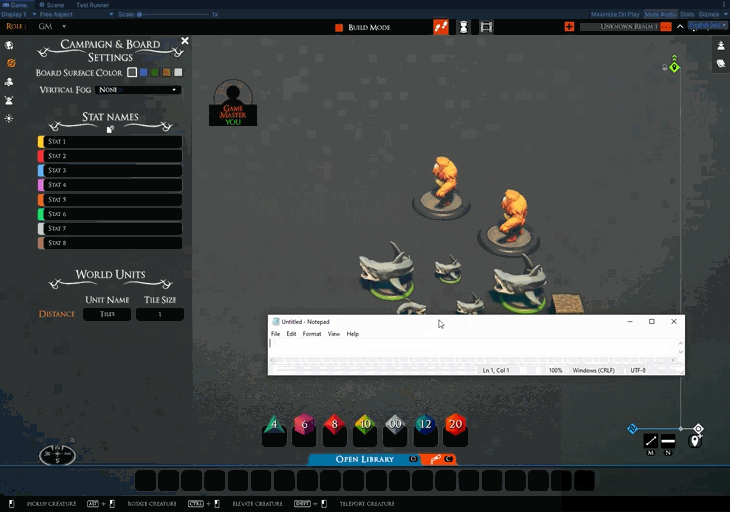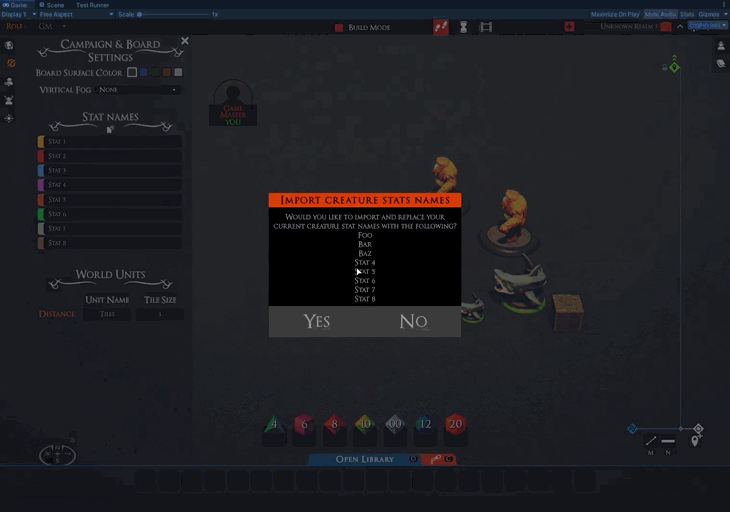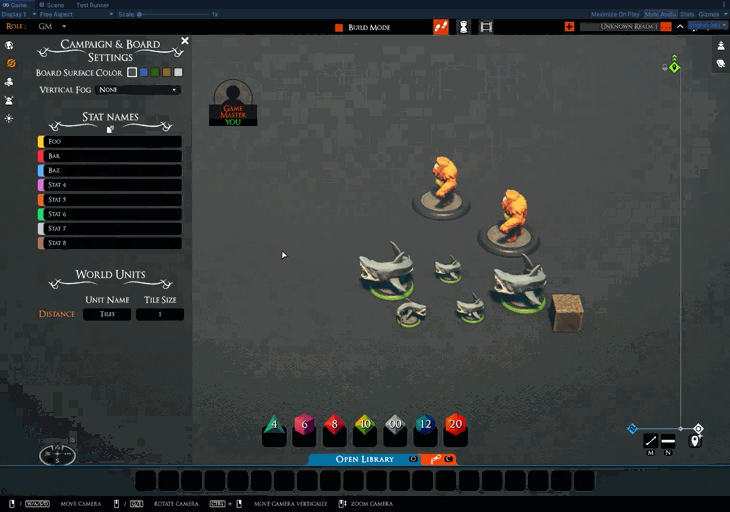
We are adding a copy button to the stats settings. Clicking it adds a URL to the clipboard, which contains the names. You can then ship these around to allow others to quickly apply the same stat names as you.
While not being the smoothest journey, it is working, and I want to get this out to you asap. We are still testing and ironing out some of the uglier bugs, but we haven’t seen any scary release blockers so far.
More news on this coming soon,
Peace.
[0] Even just selecting and deleting is scary. What if you select 100 unique creatures, delete them, and then hammer undo/redo a little? The server has to be informed of all these changes, and that is no small amount of data. And yes, it’s trivial to come up with ideas for handling this, but being good enough 90% of the time is not good enough. In short, this feature needs to be written slowly, carefully, and with testing.
[1] We added this when we saw confusion around how to use talespire://published-board URLs. Probably due to being used to how slabs worked.
| [2] It really is staggering how blind one can be when being single-minded. I knew what I was making so clearly that what I was actually making was a surprise : |
TaleSpire Dev Log 315
Heya folks!
As you’d expect, I’ve been working on HeroForge stuff.
I carried on with metadata integration into the conversion process. Most of Monday was messing around with HeroForge and looking at what kinds of scales, bases, etc., we get for different builds.
I had a few questions about some values in the metadata, so I sent off an email to HeroForge and, as always, got a quick response. So I know what to mess with next.
I had some time before the response came, however, so I did some work on internal tools. I resurrected some unfinished code for managing the news feed.
Both the news feed tooling and the HeroForge code required patching the backend, so I did that too (yay erlang live patching)
That’s all from me for today,
Have a good one!
p.s. Amongst a ton of other work, Ree has got a few bug-fixes/tweaks written, so I’ll probably put out an update tomorrow with those and the fix to the “names of hidden creature incorrectly visible to players” bug.
TaleSpire Dev Log 314
Hi folks,
Work continues well on the HeroForge Integration.
In the last dev-log, I wrote about a specific issue related to perception updates. I was pretty confident with the solution I had come up with. But then I had a sleep and didn’t like it anymore :D
So I reworked that code again, and I’m now much happier with the approach. The TLDR is that in cases where the creature index (some metadata) isn’t yet available, we queue up the perception updates. There are, of course, details that made it easier said than done, but the result should serve us well.
Next, I started integrating the miniature metadata from HeroForge. We can pull metadata for each miniature as well as the asset file itself. This contains a bunch of info that we need, such as points of interest like head/s, chest/s, hand positions, etc.
I made a quick first pass that used this data, and it looked good. The first draft helped me spot places that were sub-par[0], so I’m currently rewriting it.
Technically this is all going well.
On the more human side: I needed to visit the police today to finalize my permanent residency. The Norway side of this has been flawless, but dealing with it put me back in the Brexit headspace, along with other thoughts I was happier leaving back in England. This distracted me today, and I decided to work Saturday instead and take the afternoon for some rest and games.
Hope you are having a good day,
Seeya!
[0] I was only pulling and processing the metadata when pulling the mini itself. If I, instead, handled it before downloading the model data, the game could start using that data without waiting for the whole mini to download.
TaleSpire Dev Log 313
Hi folks,
To support HeroForge and creature modding, we had to start supporting the spawning of creatures before their meta-data is available locally.
This means (amongst other things) that we don’t know the head position and thus can’t correctly calculate vision when a creature moves.
As getting this right is one of my blockers, I decided I would take today very easy and not force a solution. I wanted to play around and give myself time away from the screen to think about it.
Initially, I thought that I might just sync the head position to other clients when a creature is spawned and when a board is synced. However, this fails in the following scenario:
- Player A joins a board
- The board contains a creature they don’t have locally
- Player A’s client starts downloading the creature
- Player B joins same board before Player A’s download completes
- Player A is now responsible for syncing the board to Player B, but doesn’t have the data for the creature
Perfectly reasonable, but messes up the approach. After thinking it over and discounting another idea or two, I decided to sync the head position along with position and rotation when a creature is dropped (dropped in this case, meaning released from the player’s “hand”).[0]
This had me revisiting the code that handles syncing the creature drop, which was a little dated. I cleaned this up, and it should now be trivial to send this data. I’ll add that tomorrow and start testing.
So that’s it, not much for a day, but I’m glad I wasn’t rushing this.
Have a good one.
[0] The idea being that the player should have a creature loaded before being able to move it. I’ll have to add some UX to communicate this clearly.