From the Burrow
TaleSpire Dev Log 439
Hi folks,
Today, I’ve been tinkering with improving the sense of presence of other builders in the game.
Communal building is a foundational part of TaleSpire. Even though we are far from finished, the fact that large groups of people can build together socially is something we are very proud of. However, one area that has been lacking is communicating what you are doing to other builders before you place something.
When building with legos, it’s easy to gesture or show each other what you are up to. To that end, I’ve begun working on showing the tile or prop you are holding to other builders.
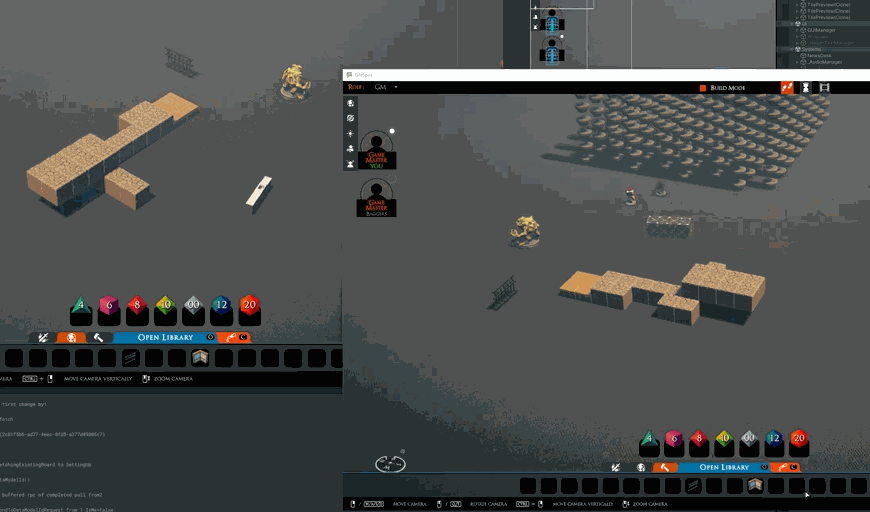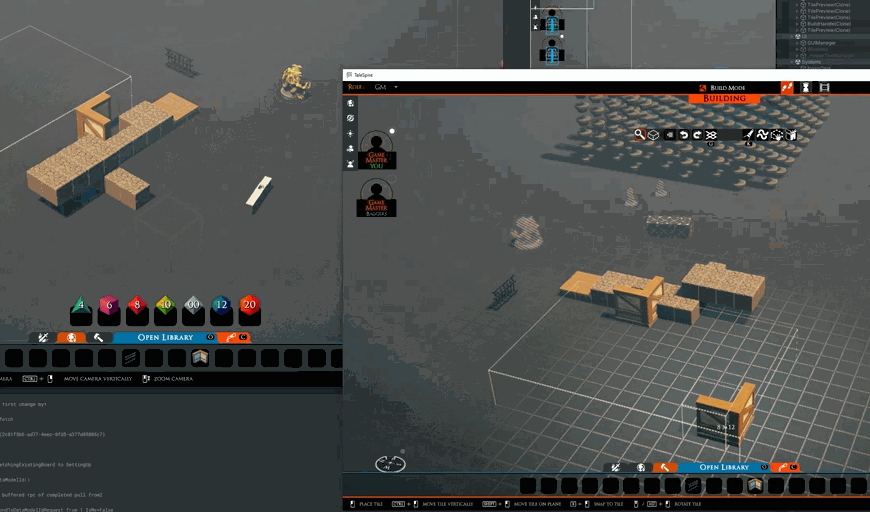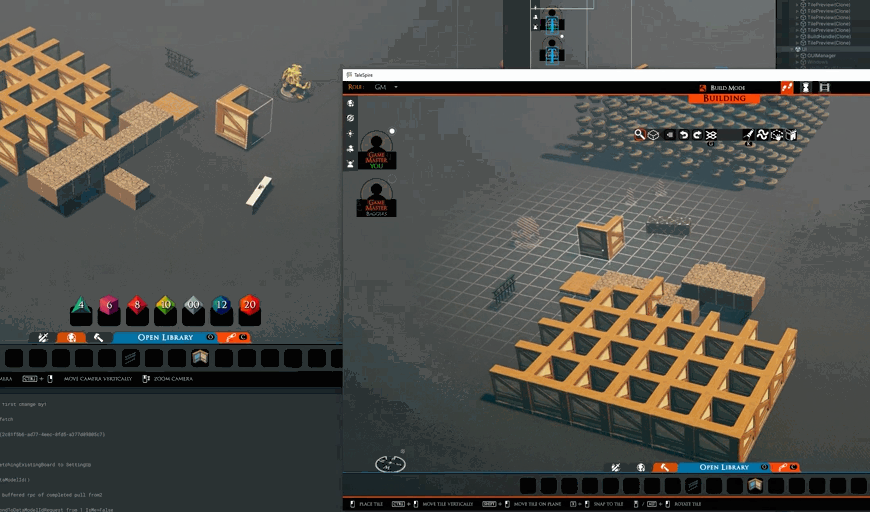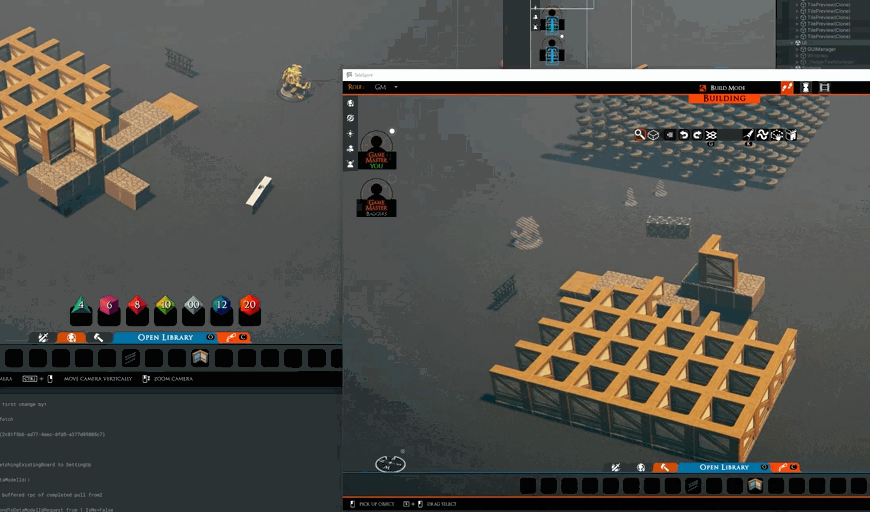
We still need to make it more obvious that the item is being held by another person (probably with a visual effect) and maybe even which person is holding it. However, along with voice chat, it’s already easier to ask questions about positions and orientations while also getting motivation from seeing others at work.
Naturally, this will be for GMs only, as you wouldn’t want the players to see what devilry you are secretly constructing up ahead!
That said, we will start experimenting with a “ping” system in the not-too-distant future, allowing for more visual communication between both GMs and players.
That’s all for tonight,
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
TaleSpire Dev Log 438
Hi folks,
Bug month may be over, but the bugs certainly aren’t. Today, I’ve been working on some server-side bugs. I didn’t want to tackle these last week while @borodust was away due to the risk of causing a problem that would send him alerts during his vacation!
All the fixes are minor, mainly cases where we weren’t sending messages to the clients in response to events like boards being imported.
I will test these fixes shortly, and then tomorrow, we’ll look into pushing them to staging.
That’s all from me tonight. Hope you are doing well.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire - Bug Month Patch 11
Heya folks, we are reaching the end of bug month. This is our eleventh patch over the last twenty-one working days. We will now be switching back over to our usual mix of features, bugs, and general improvements. We’ll be writing about what we are up to in our dev-logs, so if you are interested, be sure to follow us there.
The bug we are fixing today is the… uh… lack of folders for unique creatures?
Okay, okay, it’s a feature, not a bug release, but it’s still a fun one to wrap up the month with! It currently works the same way as the board folders do (including the limitations), and we will expand the functionality of both over time.
We hope you find this handy. We love building this game and can’t wait to send more stuff your way.
Do remember that we have a stream on twitch this Friday, June 14, at 20:00 UTC.
We have an event reminder set up on our discord here https://t.co/FH5HQ2iz78 . We hope to see you there.
Have fun!
BUILD-ID: 14438443 - Download Size: Win / Linux 2.8 MB / Mac OS 8.8 MB
p.s. The board in the gif the lovely “Guildhall” by PsiaBaba: https://talestavern.com/slab/townhall-guildhall/
Bug Month Patch 10 - The patch that already happened
This is going to be more of a dev-log than a release post. It turns out that, along with the assets we shipped yesterday, I had also accidentally pushed the fixes I was in the process of testing.
Luckily, the fixes have passed the tests, so I’m putting this out there to let you know what they were.
If you updated yesterday, then good news! You already have these fixes. If you didn’t… GOOD NEWS! You’re getting them in your next update!
The fixes in question were.
- We have fixed a shadow bug that would manifest if there were more than 500 of a single kind of prop in a 16x16x16 region
- We wait a little longer before retrying the pinging of Photon servers
- We removed the slight hover that props had during placing. It made it really hard to line up props accurately
- We now snap the position of the prop you are placing to hundredths of a unit while in your hand. The snapping is always done when the prop is placed, so this change ensures that you are seeing what you will get when you place the prop.
- Unity wasn’t showing some lower framerates, so we tweaked settings to show lower frame rates if they are integer multiples of valid frame-rates. This is a hack, but should help some folks who want to set TaleSpire to 30fps
Lastly, Mac users may have noticed that, on macOS, we now save screenshots to the desktop. This is because the old location was super ugly and tricky to get to. We will replace this with a path you can configure in the future.
Alright, I’m gonna get back to work and see if I can get something ready for tomorrow.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
Bug Month Patch 9
We are back with the second patch of the day.
In this release, we:
- Fixed a bug where props in the hand would animate constantly.
- Fixed a bug where props turned into creatures would animate constantly.
- Fixed a tutorial where the keybinding information was not responding to settings changes.
- Minor fixes to wording in tutorials.
- Add help bar hints to assist with rotating tiles and props
For those who hadn’t seen the first two bugs, this is how dumb it looked.

Really kills the space survival vibe when a crate is going full muppet!
We have another release going through testing now, so come back tomorrow for new goodies.
Ciao.
BUILD-ID: 14438443 - Download Size: Win / Linux 2.8 MB / Mac OS 8.8 MB
Bug Month Patch 8
This patch didn’t make it out last week so we are kicking off with it now.
It fixes a single, but confusing bug where tiles are seemingly hidden by a hide-volume but not actually inside one.
We will be back very soon with fixes.
BUILD-ID: 14643688 - Download Size: Win / Linux 2.9 MB / Mac OS 7.1 MB
TaleSpire Dev Log 436
Hi folks,
Yesterday was spent working towards a fix to prevent cases like the lost build session we spoke of in the last dev log. It’s coming along, but I’m going to give it another afternoon of thought as we can’t afford to get this wrong. It should go into testing later this week.
Yesterday, I also had a long tag-testing session with @chairmander. We picked some creatures and then tagged them using the new system so we could compare our results. As you might have seen in dev-log 434, he’s been working on a set of “blessed tags” and a sort of questionnaire that guides us towards some consistency in our tags across creatures[0].
The testing went well. We found some bugs in our prototype tagging tool, tweaked a couple of questions, and modified a few tag relationships that didn’t hold up under use.
Today, I’m handing this over to a contractor who has not been involved in any of this work. They will then do the same exercise as we did yesterday, and @chairmander and I will see how it works in practice. This is important as we’ve been looking at this problem for a while, so our biases and assumptions are very much baked into the system.
The contractor will then spend a couple of days tagging. We’ll get feedback, make necessary tweaks, and then unleash them on the rest of the creatures. In parallel, and as soon as we are happy enough with the blessed tag list[1], we will upload them to mod.io and start working on some UI for you folks to be able to use them.
Alright, I’d best be off. I need to get a little work done before the daily.
Peace.
Disclaimer: This DevLog is from the perspective of one developer. So it doesn’t reflect everything going on with the team
[0] It is possible to add custom tags, but a core set offers consistency and also lets us upload them to sites with fixed tag lists like mod.io.
[1] This list wont be final, but will hopefully represent a good start.
TaleSpire Dev Log 435
Good evening folks.
Today, I was looking into a really ugly slowdown when opening the “community” section of the asset library. I cracked open the profiler and, after poking around, found that calls to new Texture2D were insanely slow, easily 1ms each. I think it might be that either Unity is initializing the contents of the texture (which I’m immediately replacing) or can only make a certain number per frame.
The next version of Unity above the one we use does have an API call that allows making textures without initializing them, but the one we use doesn’t. I tried upgrading the project to that newer version on the off chance everything would just work, but no. Some APIs critical to TaleSpire have changed, and refactoring the code that relies on them is not trivial.
So, I need to decide on a different approach next. I could write some C++ to make the textures without initializing them and call that from Unity. And/or I could spread the texture creation over several frames. The first option is trickier than I’d like as I don’t think the conversion between Unity’s GraphicsFormat and DX11’s formats are documented anywhere (hopefully, I’m wrong; please leave a comment if you know!)
Before I could dig further into that, two things came up. One scheduled and one not.
The first was a very disappointing case. TaleSpire did not recover from a lost connection properly and lost 2 hours of someone’s work. This is terrible. So much of creation happens in the moment, and doing something for a second time is never quite the same. With our newer infrastructure, we now have much better logging, so we quickly tracked down the bug. What happened was that TaleSpire, at some point, lost connection to the backend (potentially due to a network issue.) Upon reconnection, we did not correctly re-register the ID of the board the player was working on. This put an invalid value into a temporary cache, which subsequently caused uploads to fail. The board was not destroyed, but the work for that session was lost. This bug has been around a long time, but now we’ve seen it, we know how to fix it. The first step is ensuring the server fails much sooner when it hits this case. That will cause the problem to manifest faster, and thus, the player won’t be able to spend hours making things that we then lose. The second step is to fix TaleSpire itself. On reconnection to the backend, we must ensure that the board-id is registered before allowing play to continue. We will have a fix for this soon.
The scheduled portion of the afternoon was a planning meeting. @Borodust and I sat down and sketched out the next few months of backend development. We also took some time to review previous decisions and talked over some recent process problems we’d like to correct. It was nice, which is not something you usually hear in meetings. Working in a tiny team on something we really want to see exist helps a lot.
And that’s all for today. I’ll be back with more fixes and dev-logs in the next week.
Hope you enjoy the weekend.
Ciao.
Disclaimer: This DevLog is from the perspective of one developer. It doesn’t reflect everything going on with the team
TaleSpire - Bug Month Patch 7
Hi again folks,
In this patch, we have a few tweaks and an experimental thing we’d like to hear your opinions on.
We have:
- Set 800x600 to be the smallest resolution pickable. This avoids a case where the window became so small you couldn’t change the resolution back again.
- Fixed the stats in the radial menu so that they update immediately if another player changes them (before you’d have to close and re-open the radial menu.
- Added result counts to community mod browser folders
Now, on to the experimental thing. As we all know, using the community mod browser needs work. The search is somewhat lacking, and the experience of finding creations is sub-par.
A big part of the answer will be tagging. We are bringing tags to creatures soon™ (we’ll have a dev-log on progress by Monday, and the tagging tool is going into internal testing on Tuesday), but in the meantime, I was wondering if there were any quick wins.
The search implementation is on mod.io’s end so we can’t tweak that. The current behaviour is such that if you search “Lord of the Rings” - it will return every result where the name contains any of the following words: ‘The’, ‘Lord’, ‘of’, ‘the’, ‘Rings’.
There is another option, though. They have an option[0] where you can use % as a wildcard. That means you could search fi%b% and get results with both “fireball” and “Firebird.”
So here is the question: Is that useful to any of you? It sounds like it could be, but in theory and in practice can be very different.
To that end, I’ve added it to the game so you can try it out. By default, the search is the same as before, and the wildcard symbol won’t work. However, if you start the search with a question mark, it will switch to the mode where you can use wildcards. For example, ?fi%b% matches “fireball” and “firebird” as mentioned above.
That’s it for today. We’ll be back soon with more fixes.
Ciao
BUILD-ID: 14543672 - Download Size: Win / Linux 4.9 MB / Mac OS 7.8 MB
[0] Fellow nerds might like to check out their api docs. The two places I think are most relevant are https://docs.mod.io/restapiref/?http#get-mods and https://docs.mod.io/restapiref/?http#filtering Do let us know if you find anything interesting!
Bug Month Patch 6
Today, we tackle a bug that has thwarted the pasting of certain kinds of slabs.
When a slab that combined thin tiles and props was copied, this bug made it impossible to place the slab back on the grid correctly. It would be misaligned.
The following shows the difference before and after this patch.
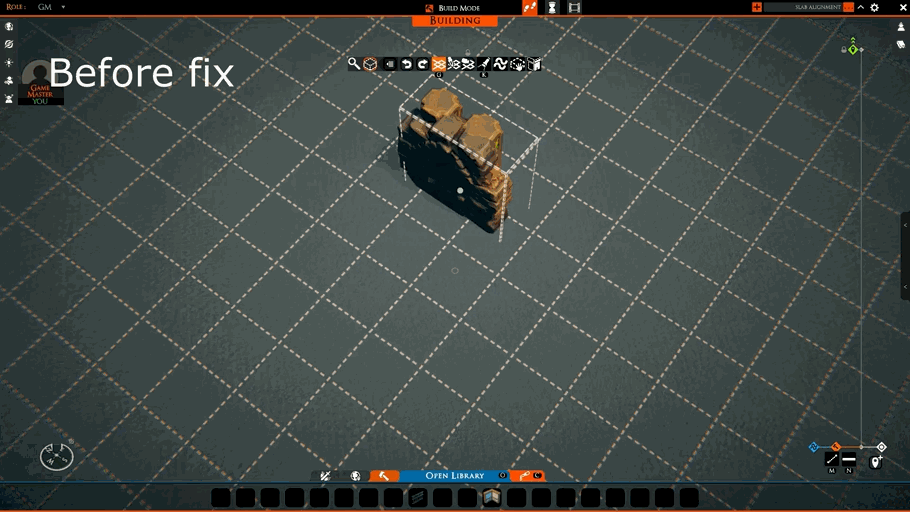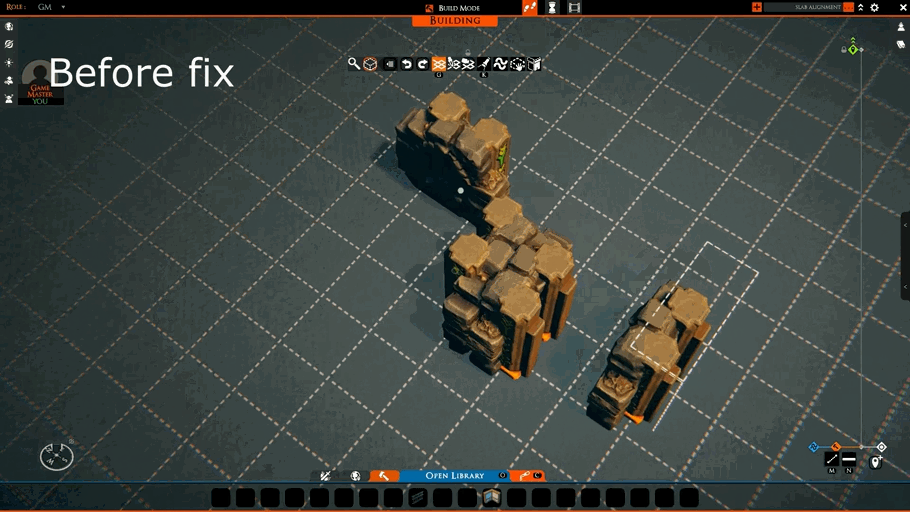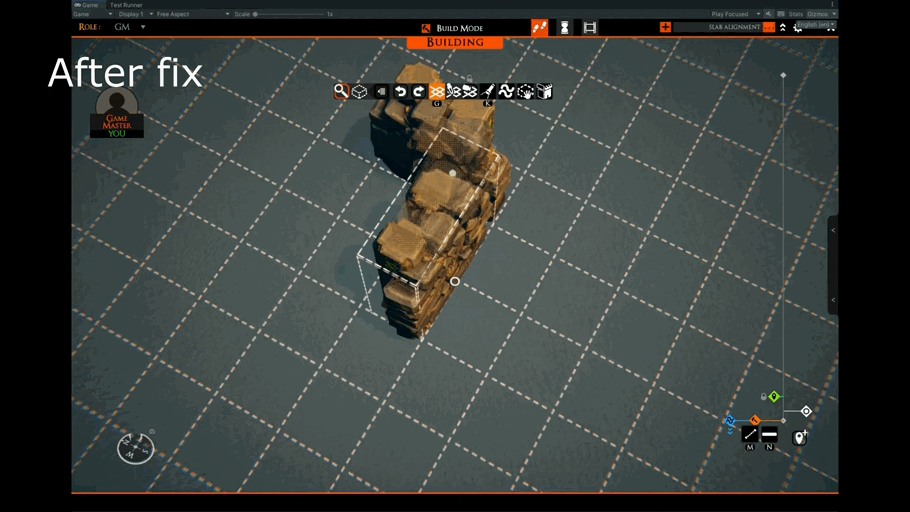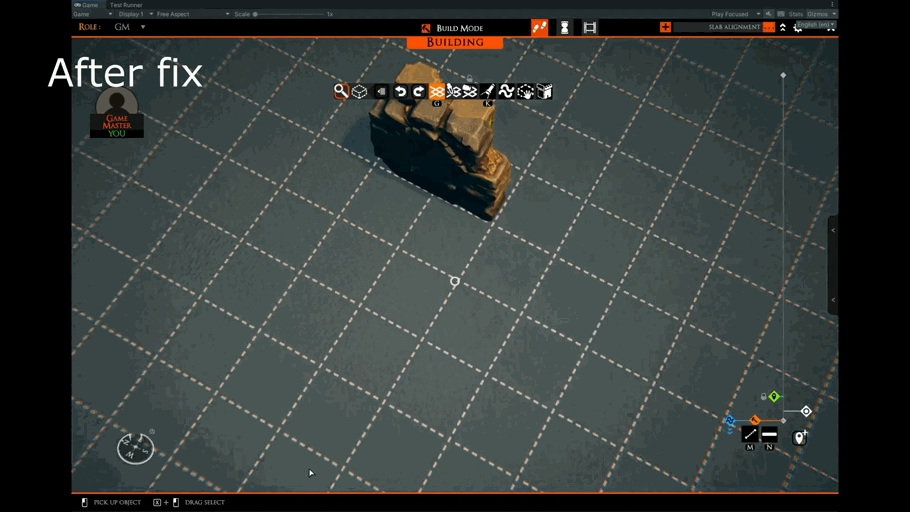
Along with this, we fixed a case where a malformed slab could put tiles in unsupported rotations. This also allows for some data optimizations later on.
That’s all for this today. We will be back on Monday with Seats and more fixes.
BUILD-ID: 14497681 - Download Size: Win / Linux 2.9 MB / Mac OS 6.7 MB
Ps. We are not going to make a habit of releasing on the weekend. This fix was going to ship on Thursday, but our main build server decided to freak out and mess up the end of our week. Remember, computers can hear you, and as soon as you announce a deadline they will do their damnedest to mess that up :p